
- 1【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(6月 30 日论文合集)_detect any deepfakes: segment anything meets face
- 2朴素贝叶斯分类器(姓名预测性别)_根据姓名判断性别 python
- 3python名称定义怎么解决_类的“Python名称错误:未定义名称”
- 4java访问ad域
- 5动态鼠标指针_问题探究:系统鼠标设置对游戏灵敏度的影响存在吗?
- 6数据库原理第五版第二三章习题_蟺jno,pno(spj)梅蟺pno(a
- 7最全的tcpdump使用详解
- 8【华为 ICT & HCIA & eNSP 习题汇总】——题目集21
- 9Minio多主机分布式 docker-compose 集群部署
- 10大数据综合实验的踩坑总结(林子雨)_大数据实验问题总结
已解决!!!mamba2替换mamba,速度提升2到8倍
赞
踩
mamba已经发布有一段时间了,打着击败transformer的口号,确实引起了一大波关注,核心架构的改进也给研究者提供了新的水论文的思路
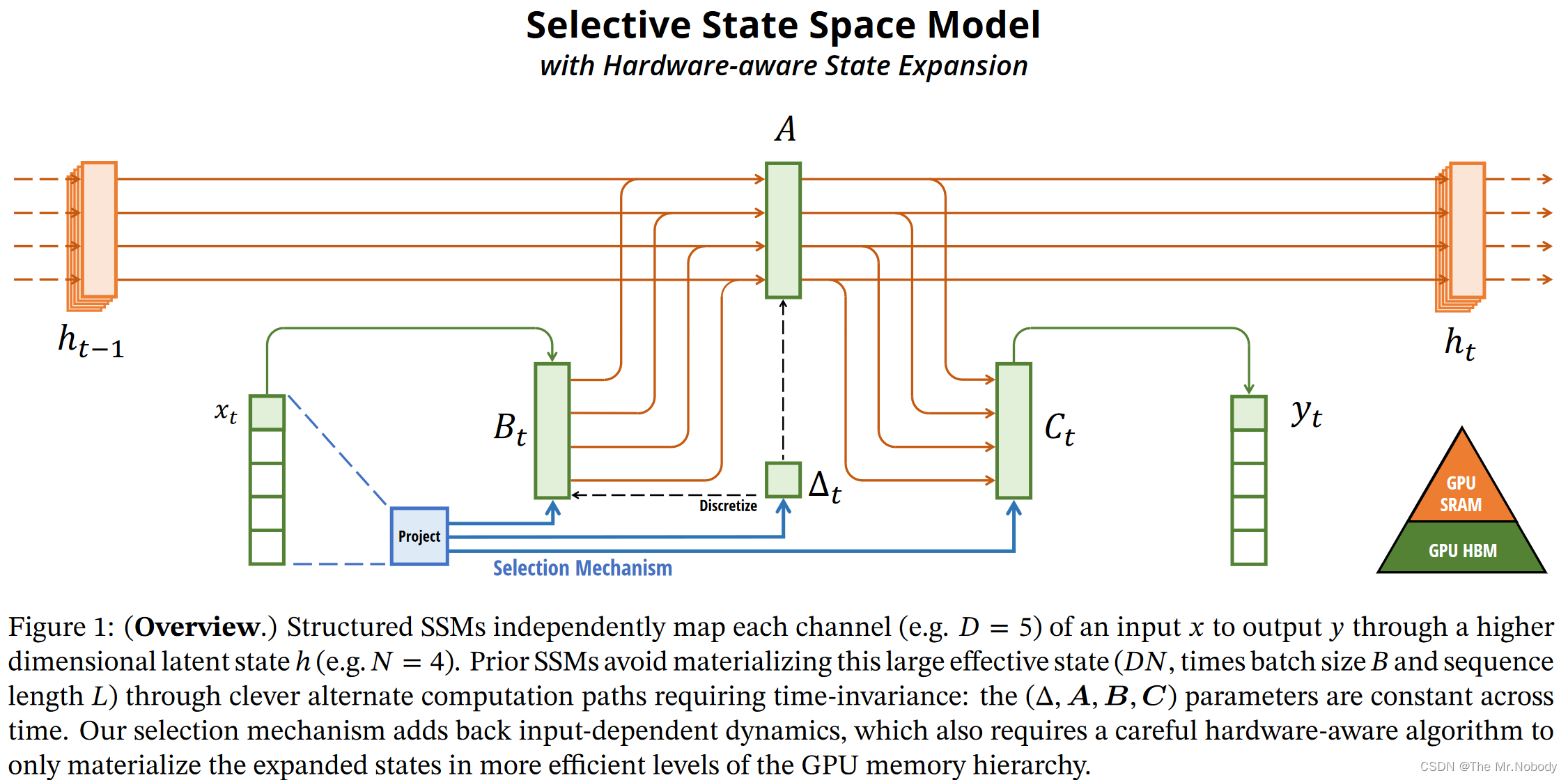
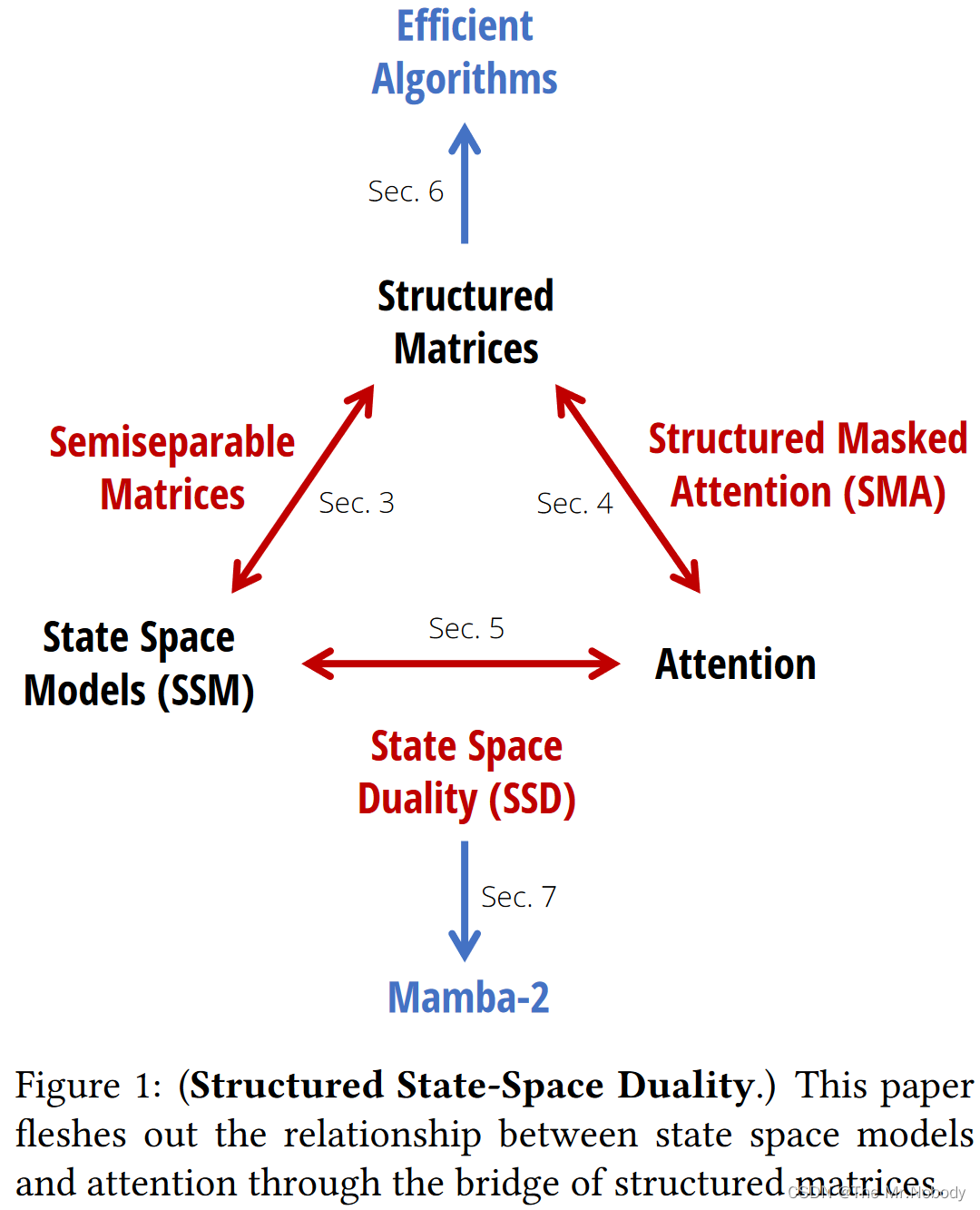
mamba2已经发布,号称比第一代mamba要提速2到8倍,实际上手时却挺打击信心的,发现mamba2的速度还不如mamba。
于是去GitHub仓库中的Issues提问,看了作者Tri Dao的回复,
“Mamba2 is written mostly in Triton, so there’s a lot of CPU overhead if the layer is so small. Two ways to get around that: (1) CUDA graph (or torch compile) (2) use a large model.”
“Try warming up by running it once first. The first time will invoke the triton compiler & autotune so it’ll be slow.”
恍然大悟,于是改了如下代码:
import time
import torch
from mamba_ssm import Mamba2
from mamba_ssm import Mamba
from debug import print_model_parameters
repeat_num = 1000
batch, length, dim = 2, 256*256*2, 256
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=64, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
print_model_parameters(model, output_to_csv=True, file_path='./model.csv')
y = model(x) # warm up first
t1 = time.time()
for i in range(repeat_num):
y = model(x)
assert y.shape == x.shape
print(f"Time of mamba taken: {time.time() - t1:.3f} s")
model = Mamba2(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=64, # SSM state expansion factor, typically 64 or 128
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
print_model_parameters(model, output_to_csv=True, file_path='./model.csv')
y = model(x) # warm up first
t1 = time.time()
for i in range(repeat_num):
y = model(x)
assert y.shape == x.shape
print(f"Time of mamba2 taken: {time.time() - t1:.3f} s")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
代码中增加了序列长度,因为mamba2在处理更长的序列时提升更大
同时增加了warm up的操作,即第一次先预热,不算在消耗时间内
Model's Parameters and Sizes:
Total parameters: 511488
Trainable parameters: 511488
Non-trainable parameters: 0
Time of mamba taken: 24.061 s
Model's Parameters and Sizes:
Total parameters: 431768
Trainable parameters: 431768
Non-trainable parameters: 0
Time of mamba2 taken: 14.011 s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
参考资料
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
https://github.com/state-spaces
https://github.com/state-spaces/mamba/issues/355

