
- 1Windows找不到文件‘Gpedit.msc‘。请确定文件名是否正确后,再试一次。_gpedit.msc找不到文件
- 2Linux基础入门教程-超详细_linux入门基础教程
- 3分享三款好用的mac软件网站,资源相当齐全
- 4SpringBoot快速学习
- 5完美解决Python报错:PermissionError: [Errno 13] Permission denied_python permission denied
- 6【论文泛读94】用于文本生成的预训练语言模型:一项调查_tructural adapters in pretrained language models f
- 7了解一下银行科技信息岗_银行信息科技岗的理解
- 8基于pytorch的steam游戏评分的线性回归问题分析
- 9Github hosts修改_github xiugaihots
- 10软件测试——基础理论知识你都不一定看得懂_软件测试理论知识
PaddleX 3.0-beta昇腾版发布:多场景、低代码,开启AI开发新篇章
赞
踩

2023年12月,飞桨正式推出了端云协同的低代码开发工具——PaddleX。这款一站式AI开发工具集成了飞桨开发套件多年积累的模型训练、推理全流程开发的优势能力。同时立足产业真实应用场景,内置12个面向产业应用的飞桨系列模型,如PP-OCRv4、PP-ChatOCRv2、RT-DETR、PicoDet等。基于低代码开发模式,PaddleX不仅可以助力开发者高效实现AI应用,更成为推动企业新质生产力飞跃的利器。为了进一步提升 PaddleX 用户体验以及产品能力,飞桨基于前后端分离架构,对模型产线进行彻底重构,今年3月正式全新升级推出星河零代码产线!开发者无需代码开发经验,只需准备符合产线要求的数据集,6步即可高效体验从数据准备到模型部署的完整AI开发流程。
为进一步满足开发者在本地硬件设备上顺畅地开发模型,飞桨于6月27日发布PaddleX 3.0-beta 昇腾版,该版本聚焦7大主流AI场景,精选68个优质飞桨模型,构建了16条产业级模型产线,包含了多项能力的显著升级,旨在助力企业开发者以低成本、零门槛的方式,有效解决产业中的实际问题。
 核心亮点
核心亮点
模型丰富场景全面: 精选 68 个优质飞桨模型,覆盖图像分类、目标检测、图像分割、OCR、文本图像版面分析、文本图像信息抽取、时序分析等任务场景。
低门槛开发范式,便捷开发与部署: 低代码开发方式。通过统一的 API 接口实现模型产线的全流程开发,同时支持用户自定义模型流程串联。
昇腾硬件高效支持:携手华为团队,深度适配昇腾910芯片,覆盖PaddleX产线重点模型,满足用户多样化需求。
PaddleX 3.0-beta开源体验地址:https://github.com/PaddlePaddle/PaddleX/tree/release/3.0-beta
 模型丰富场景全面
模型丰富场景全面
模型开发的过程中,开发者们常常面临模型零散、选择困难等挑战。为了解决这些问题,当前 PaddleX 精选了68个优质的飞桨模型,覆盖了图像分类、目标检测、图像分割、OCR、时序预测等多个关键领域,并整合为16条模型产线。
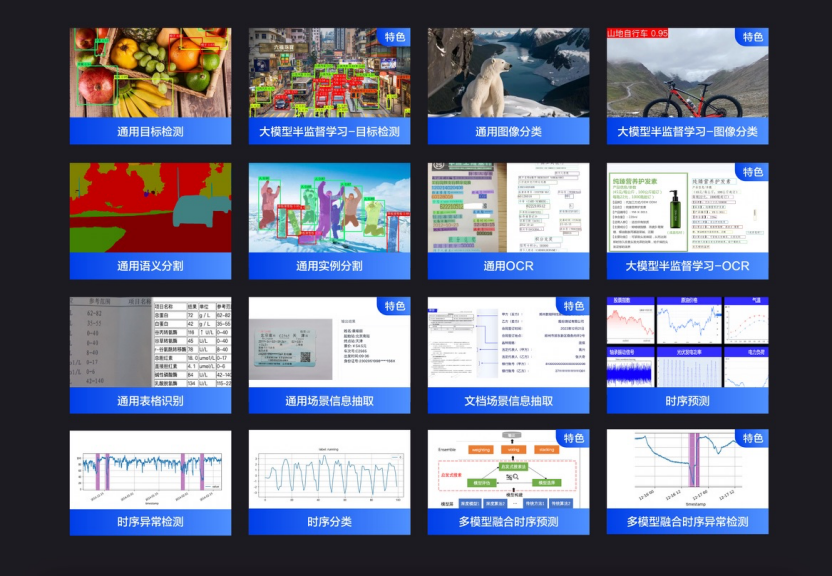
产业级模型产线
 低门槛开发范式
低门槛开发范式
如何低成本开发和优化单模型一直是业界关注的问题,PaddleX 为了解决这个问题,在模型的开发流程上做了升级,开发者无需深入底层原理,仅需要统一的命令,加载不同的配置,即可完成不同任务的数据校验、训练、评估、推理。在此基础上,PaddleX 暴露了关键超参数,支持开发者快速修改调参优化模型。
统一的命令完成数据校验、训练、评估、推理
python main.py -c config.yaml -o Global.mode=train -o Global.device=npu:0main.py 为模型开发统一入口,config.yaml 中包含了具体模型的信息,如模型名字、学习率、批次大小等,mode 支持数据校验(dataset_check)、训练(train)、评估(evaluate)、推理(predict)。模型训练完之后,会自动保存模型的动态图和静态图权重,方便后续集成。
快速进行模型优化
python main.py -c config.yaml -o Global.mode=train -o Train.learning_rate=0.001 -o Train.epochs_iters=100 -o Global.device=npu:0PaddleX支持开发者对常用超参数进行快速修改进而完成模型的优化,对于模型优化的关键超参数,已经在模型对应的 config.yaml 中暴露,可以通过命令行方便地修改替换。
六行代码集成到自己的项目中
开发者可以方便地将训练好的模型通过六行代码,集成到自己的项目中,也可以通过这些简单的 Python API 完成模型的组合使用。
- from paddlex import create_model
- from paddlex import PaddleInferenceOption
- kernel_option = PaddleInferenceOption()
- kernel_option.set_device("npu:0")
-
-
- model = create_model(model_name="PP-YOLOE_plus-S", model_dir="your_model_dir", kernel_option=kernel_option)
- result = model.predict({'input_path': "xxx.jpg"})
 昇腾硬件支持
昇腾硬件支持
为了满足昇腾用户的AI开发需求,PaddleX团队基于飞桨框架在硬件兼容性和灵活性方面的优势,深度适配了昇腾训练芯片,提升昇腾用户的使用体验。只需要参照 安装文档 安装多硬件版本的飞桨框架后,在启动训练时添加一个配置设备的参数,添加一个配置设备的参数,即可在昇腾上使用上述工具。在昇腾硬件上,PaddleX 3.0-beta 支持的模型数量达到数十个,涵盖图像分类、目标检测、图像分割、时序等多个领域,详细的模型支持列表请在以下链接中查看:昇腾模型列表 。
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta/docs/tutorials/models/support_npu_model_list.md
未来我们将继续在昇腾上适配PaddleX开源的全部模型,敬请期待。
为了让小伙伴们更快速地了解如何基于昇腾芯片进行模型开发全流程操作,以及基于真实产业用户场景与业务数据,如何利用本地GPU算力,低成本零门槛解决产业实际问题,昇腾AI与百度的研发工程师将于8月1日(周四)20:00为大家深度解析从数据准备、数据校验、模型训练、性能调优到模型部署的开发全流程开发难点,从场景、产线、工具完成产业实操体验。赶快扫描下方海报二维码预约报名!

同时,关于 PaddleX 的技术问题欢迎大家扫码上方二维码入群讨论,也欢迎大家在 GitHub 点 star支持我们的工作!

相关链接
开源版体验地址:
http://github.com/PaddlePaddle/PaddleX




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

