
- 1【AIGC】Stable Diffusion的常见错误_stable diffusion zlib.dll
- 2实用的Visual Studio插件_visual studio插件安装
- 3Pytorch预训练模型下载慢解决方式
- 4springboot缓存@Cacheable的使用,及设置过期时间_cacheable缓存时间
- 5中科驭数DPU技术开放日秀“肌肉”:云原生网络、RDMA、安全加速、低延时网络等方案组团亮相
- 6GPT4技术报告介绍_gpt4csdn
- 7中文纠错(Chinese Spelling Correct)最新技术方案总结_中文纠错模型
- 8论文阅读_AI生成检测_Ghostbuster
- 9通信工程专业毕业设计选题推荐 毕设选题指导_通信毕业设计选题推荐
- 10C# 读取多条数据记录导出到 Word 标签模板
CVPR2019:Meta-SR: A Magnification-Arbitrary Network for Super-Resolution 任意尺度的图像超分辨率_meta sr github
赞
踩
论文:Meta-SR: A Magnification-Arbitrary Network for Super-Resolution 任意尺度的超分辨率
代码:https://github.com/XuecaiHu/Meta-SR-Pytorch.git
简介
随着深度卷积神经网络(DCNNs)的发展,近年来对超分辨率的研究取得了巨大的成功。然而,任意尺度因子的超分辨率长期以来一直被忽视。以往的研究大多将不同尺度因子的超分辨视为独立的任务。他们针对每个尺度因子训练一个特定的模型,计算效率较低,且只考虑了几个整数尺度因子的超分辨率。
本文提出了一种称为Meta-SR的新方法,第一个使用单一模型求解任意尺度因子(包括非整数尺度因子)的超分辨率。在Meta-SR中,提出了Meta-Upscale模块来替代传统的上采样(Upscale)模块。对于任意尺度因子,MetaUpscale模块通过将尺度因子作为输入,动态预测高级滤波器的权重,并使用这些权重生成任意大小的HR图像。对于任何低分辨率的图像,Meta-SR仅使用一个单一的模型就可以用任意的比例因子持续地放大它。
本文通过在广泛使用的单图像超分辨率基准数据集上的大量实验来评估该方法。实验结果表明了本模型的优越性。
从固定尺度因子的Upsacle到Meta-Upscale
目前比较先进的SISR方法,如ESPCNN, EDSR , RDN, RCAN,这些方法都是通过亚像素卷积对网络末端的feature map进行放大。不幸的是,这些方法必须为每个比例因素设计一个特定的高档模块。每个上采样模块只能放大固定整数比例因子的图像。超像素卷积只适用于整数尺度因子。这些缺点限制了SISR在真实场景中的使用。但是,我们可以通过适当的放大输入图像来实现非整数尺度因子的超分辨率。但由于计算量的重复和投入量的增大,使得这些方法费时费力,难以投入实际应用。
回忆上面提到的这些SISR的上采样方法:ESPCN,EDSR,RCAN 的不同之处在于它们的Feature Learning Module设计,而相同之处在于都通过网络后面的Upscale Module,以PixelShuffle的方式进行图像的上采样。
以RCAN的网络结构和Pytorch代码为例:

其中深蓝色的为RCAN的Upscale Module,在它后面一般只有负责将feature map的channel变为3的卷积核。
class RCAN(nn.Module): def __init__(self, args): super(RCAN, self).__init__() scale = args.scale num_features = args.num_features num_rg = args.num_rg num_rcab = args.num_rcab reduction = args.reduction self.sf = nn.Conv2d(3, num_features, kernel_size=3, padding=1) self.rgs = nn.Sequential(*[RG(num_features, num_rcab, reduction) for _ in range(num_rg)]) self.conv1 = nn.Conv2d(num_features, num_features, kernel_size=3, padding=1) self.upscale = nn.Sequential( nn.Conv2d(num_features, num_features * (scale ** 2), kernel_size=3, padding=1), nn.PixelShuffle(scale) ) self.conv2 = nn.Conv2d(num_features, 3, kernel_size=3, padding=1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
PixelShuffle的实现方式如下图所示,它将 ( r 2 C , H , W ) (r^2C,H,W) (r2C,H,W)的尺寸变成 ( C , r H , r W ) (C,rH,rW) (C,rH,rW)实现upscale,具体见Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.

从上面的实现方式可以看出,PixelShuffle的上采样方式决定了上采样倍数r必须是整数 ,这使得过去的SISR方法的Upscale Module无法解决任意倍数(非整数)放大的问题。 因此,本文Meta-SR要解决的关键(创新点)是 设计新的Meta-Upscale Module模块替换原来的Upscale Module,使其可以解决任意倍数放大的问题。
对于前面的Feature Learning Module部分,文章可以使用目前的主流模型,例如RDN,EDSR等方法,本文不再详细介绍。
Meta-Upscale Module
上文介绍了文章的贡献之处在于Meta-Upscale Module,它可以与其他现有的SISR网络的Feature Learning Module部分相结合,形成可以处理任意尺度因子的新网络。
其中,基于RDN网络的Meta-RDN 的结构如下图所示,图中体现了Feature Learning Module,Upscale Module及其具体操作。

接下来介绍设计Meta-Upscale Module的三个概念:
1.Location Projection
对于尺度因子(采样倍数)
r
r
r为整数的情况,
r
r
r个像素决定1个像素。但在非整数的情况下,例如
r
=
1.5
r=1.5
r=1.5,可能有2个像素决定1个像素,也可能有1个像素决定1个像素(见下图)。


2.Weight Prediction
文章认为,过去的方法为每个采样倍数预先定义了filters并进行训练。而本文使用一个网络预测filter权重。这个权重预测函数
W
W
W是一个由位置坐标信息构成的向量
v
i
j
v_{ij}
vij经过一个网络形成的。

文章将尺度因子 r r r加入到 v i j v_{ij} vij中(第三项),以区分不同尺度因子的权重。
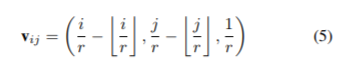
文章认为,如果不加入第三项,例如需要上采样得到2倍和4倍的图像,像素 ( i , j ) (i,j) (i,j)在2倍上和像素 ( 2 i , 2 j ) (2i,2j) (2i,2j)在4倍上的filters的权重是相同的,这样无法区分不同的尺度因子,会影响效果。
Weight Prediction部分的网络代码:
在训练前预先生成
v
v
v向量
def input_matrix_wpn_new(inH, inW, scale, add_scale=True):
......
return pos_mat_small, mask_mat ##outH*outW*2 outH=scale_int*inH , outW = scale_int *inW
- 1
- 2
- 3
这个函数输入inH,inW如果报错:
RuntimeError: "floor" not implemented for 'torch.LongTensor'
- 1
需要将
h_project_coord = torch.arange(0, outH, 1).mul(1.0 / scale)
- 1
改成
h_project_coord = torch.arange(0., outH, 1).mul(1.0 / scale)
- 1
预测权重网络代码(Meta-RDN结构图中可以看到)
class Pos2Weight(nn.Module):
def __init__(self,inC, kernel_size=3, outC=3):
super(Pos2Weight,self).__init__()
self.inC = inC
self.kernel_size=kernel_size
self.outC = outC
self.meta_block=nn.Sequential(
nn.Linear(3,256),
nn.ReLU(inplace=True),
nn.Linear(256,self.kernel_size*self.kernel_size*self.inC*self.outC)
)
def forward(self,x):
output = self.meta_block(x)
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
调用,输出是(1, k × k × i n C h a n n e l × o u t C h a n n e l k\times{k}\times{inChannel}\times{outChannel} k×k×inChannel×outChannel)
local_weight = self.P2W(pos_mat.view(pos_mat.size(1),-1)) ### (outH*outW, outC*inC*kernel_size*kernel_size)
- 1
3.Feature Mapping
由其他网络的Feature Learning Module得到的映射,与Weight Prediction得到的权重作矩阵乘积得到(公式6)。

对应代码
up_x = self.repeat_x(res) ### the output is (N*r*r,inC,inH,inW)
# N*r^2 x [inC * kH * kW] x [inH * inW]
cols = nn.functional.unfold(up_x, 3,padding=1)
scale_int = math.ceil(self.scale)
local_weight = self.repeat_weight(local_weight,scale_int,x.size(2),x.size(3))
cols = cols.contiguous().view(cols.size(0)//(scale_int**2),scale_int**2, cols.size(1), cols.size(2), 1).permute(0,1, 3, 4, 2).contiguous()
local_weight = local_weight.contiguous().view(x.size(2),scale_int, x.size(3),scale_int,-1,3).permute(1,3,0,2,4,5).contiguous()
local_weight = local_weight.contiguous().view(scale_int**2, x.size(2)*x.size(3),-1, 3)
out = torch.matmul(cols,local_weight).permute(0,1,4,2,3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果对比
本文和目前的state-of-art RDN和EDSR结合起来,形成了Meta-RDN 和Meta-EDSR两种方法,并得到了更好的结果。


