
- 1学生免费使用JetBrains开发工具,lntelliJ IDEA,Webstrom等开发工具_github学生版可以使用webstorm嘛
- 2一分钟带你了解Huawei LiteOS组件开发指南_liteos添加组件
- 3python如何获取动态页面数据_python爬取动态网页表格数据
- 4低代码平台前端的设计与实现(一)渲染模块的基本实现_代码渲染
- 5Python基础练习题--第四章 循环结构_python循环结构例题
- 6人工智能的应用和学习方向_ai行业应用学习
- 7获取详情API接口(抖音)_抖音api接口文档
- 8mac Monterey 安装vmware fusion12 个人免费授权版_vmware fusion 12宣布个人用户免费
- 9oracle asm平衡,深入了解Oracle ASM(一):基础概念
- 10Redis实战(5)——Redis实现消息队列_redis消息队列实现
【长文阅读】MAMBA作者博士论文<MODELING SEQUENCES WITH STRUCTURED STATE SPACES>-Chapter3 Computing SSMs_mamba motivation
赞
踩
Chapter 3 Computing Structured SSMs
Gu A. Modeling Sequences with Structured State Spaces[D]. Stanford University, 2023.
本文是MAMBA作者的博士毕业论文,为了理清楚MAMBA专门花时间拜读这篇长达330页的博士论文,由于知识水平有限,只能尽自己所能概述记录,并适当补充一些相关数学背景,欢迎探讨与批评指正。内容多,分章节更新以免凌乱。
第3章讨论了结构化状态空间模型(SSM),特别是S4模型的计算。它概述了SSM的计算挑战,并提出了结构化SSM的需求。这一章介绍了两类结构化SSM:S4-Diag(对角线结构状态空间模型)和S4-DPLR(对角线加低秩参数化)。章节详细讨论了这些模型、它们的算法和计算复杂性,并对这些模型进行了深入比较。此外,还简要调查了其他类型的结构化SSM,涉及SSM的各个方面,包括参数化细节和计算效率。
3.1 Motivation: Computational Difficulty of SSMs
这一节讨论状态空间模型(SSM)的计算难度。首先,定义了最优效率的SSM,并介绍了两种不同的计算模式:循环模式和卷积模式。接着讨论了这两种模式的优化计算问题,强调了即使对于结构化的矩阵,实现高效的SSM计算也是具有挑战性的。为了解决这些挑战,文档提出了一些解决方案和思路,比如使用对角矩阵和利用特定的算法来减少计算复杂度。这些讨论为引入结构化SSM(特别是S4模型)提供了动机和理论基础。
定义了两种模式:
定义3.1(循环模式计算):展开 SSM 递归的一个步骤需要与离散状态矩阵 A A A 进行矩阵向量乘法 (MVM)。如果可以在 O ( N ) O(N) O(N) 时间内计算该 MVM,则 SSM 具有最佳递归模式而不是 O ( N 2 ) O(N^2) O(N2)。
定义3.2(卷积模式计算): SSM卷积模式需要具体化状态空间内核 K ‾ \overline{\boldsymbol{K}} K,如果该 SSK 可以在 O ( L + N ) O(L +N) O(L+N) 时间内计算,则 SSM 具有最佳卷积模式。
本节内容就是简单说明,为后续引出结构化方式做铺垫,简要概述一下,不展开。
3.1.1 General Recurrent Computation:这部分讨论了在循环模式下计算状态空间模型(SSM)的一般方法。它探讨了循环网络的效率和它们处理长序列数据时的挑战,特别是在资源受限的情况下。
3.1.2 General Convolutional Computation:这一小节集中讨论了卷积模式下的SSM计算。卷积模式在处理时间序列数据时更加高效,但它们也面临复杂度和优化的问题。
3.1.3 Structured SSMs:此部分介绍了结构化状态空间模型(如S4)作为一种解决上述计算问题的方法。它探索了通过特定结构化设计来优化SSM的可能性,强调了结构化方法在计算效率和模型性能上的优势
3.2 Diagonally Structured State Space Models
3.2节详细探讨了对角线结构化状态空间模型(Diagonally Structured State Space Models),简称为S4-Diag。这部分首先介绍了使用对角矩阵来简化SSM计算的理论基础。接着,它提出了S4-Diag模型,并讨论了该模型的两个主要问题:递归模式下的计算和卷积核的计算。对于递归模式,由于使用对角矩阵,使得计算变得更加简单。对于卷积核,使用范德蒙德矩阵的乘法进行计算,这也简化了计算过程。这一节还讨论了S4-Diag模型的时间和空间复杂度,并提供了实现示例。通过这些讨论,展示了对角线结构化SSM在简化计算和提高效率方面的优势。
引理 3.3:共轭是 SSM 上的等价关系
( A , B , C ) ∼ ( V − 1 A V , V − 1 B , C V ) (\boldsymbol{A}, \boldsymbol{B}, \boldsymbol{C}) \sim\left(\boldsymbol{V}^{-1} \boldsymbol{A} \boldsymbol{V}, \boldsymbol{V}^{-1} \boldsymbol{B}, \boldsymbol{C} \boldsymbol{V}\right) (A,B,C)∼(V−1AV,V−1B,CV)
对上式补充说明
证明可以从状态空间模型(SSM)的两种表达形式出发。首先,有两个SSM,其状态分别用 x x x 和 x ~ \tilde{x} x~ 表示:
1.对于第一个SSM:
x ′ = A x + B u y = C x
x′y=Ax+Bu=Cxx′y=Ax+Bu=Cx 2.对于第二个SSM(经过变换):
x ~ ′ = V − 1 A V x ~ + V − 1 B u y = C V x ~
x~′y=V−1AVx~+V−1Bu=CVx~x~′y=V−1AVx~+V−1Bu=CVx~
- 这里, x ~ ′ \tilde{x}^{\prime} x~′ 表示下一状态。
- V − 1 A V x ~ V^{-1} A V \tilde{x} V−1AVx~ 是状态变换的主要部分。首先, x ~ \tilde{x} x~ 乘以 V V V,将状态空间转换到新的基。然后,应用原始的状态转换矩阵 A A A,最后通过 V − 1 V^{-1} V−1 把状态空间转换回原来的基。
- V − 1 B u V^{-1} B u V−1Bu 表示对控制信号 u u u 的影响,也经过了类似的基变换。
- C V x ~ C V \tilde{x} CVx~表示输出是如何从变换后的状态 x ~ \tilde{x} x~产生的。首先,状态 x ~ \tilde{x} x~乘以 V V V,进行基的变换,然后乘以输出矩阵 C C C 产生最终的输出。
通过 V V V 将第二个 SSM 乘以 V V V 后,这两个SSM变得一样,即 x = V x ~ x=V \tilde{x} x=Vx~。因此,这两个SSM计算的是相同的操作符 u → y \mathrm{u} \rightarrow \mathrm{y} u→y,但在状态 x x x 中通过 V V V 进行了基的变换。换句话说,它们表达了相同的从 u 到 y 的映射。这也被称为 SSM 文献中的状态空间转换。
这些公式通过 V V V和 V − 1 V^{-1} V−1 实现了状态空间的基变换。这意味着虽然状态空间的表示形式改变了,但系统的基本动态(即从输入 u u u 到输出 y y y 的映射)保持不变。这种转换有助于简化问题,或者在特定情况下使得问题更易于分析。在实际应用中,选取合适的变换矩阵 V V V 可以使状态空间更加规范化,例如使得矩阵 A A A更接近于对角矩阵形式,从而简化计算和分析。
命题3.4 :在所有 N × N N \times N N×N 维的复数矩阵集合 C N × N C^{N \times N} CN×N 中,可对角化矩阵的集合 D D D 是稠密的,并且具有完全测度(即其补集的测度为0)。
换句话说,这个命题意味着(几乎)所有的状态空间模型(SSM)都等价于某个对角SSM。这表明,通过适当的变换,大多数SSM都可以被简化为对角形式,这在数学和工程应用中是一个重要的结论,因为对角矩阵通常更易于处理和分析。特别是,计算 K ‾ \overline{\boldsymbol{K}} K成为一种经过充分研究的结构化矩阵乘法,具有高效的时间和空间复杂度。
3.2.1 S4D: Diagonal SSM Algorithms
本小节介绍了对角SSM(状态空间模型)算法,即S4D(Structured State Space Model for Diagonal matrices)。以下是该部分的关键内容:
- 对角SSM的符号表示:
- 当 A A A是对角矩阵时, A n A_n An 表示其对角线上的元素。
- 在单输入单输出(SISO)情况下, B ∈ R N × 1 B \in R^{N \times 1} B∈RN×1 和 C ∈ R 1 × N C \in R^{1 \times N} C∈R1×N,因此可以直接使用 B n B_n Bn 和 C n C_n Cn来表示它们的元素。
- S4D递归算法:
- 在对角SSM上计算任何离散化都很简单,因为对角矩阵上的解析函数可以简化为对其对角线元素逐个执行。
- 通过对角矩阵进行矩阵-向量乘法(MVM)也很简单,因为它可以简化为逐元素乘法。因此,对角SSM轻松满足了定义3.1。
- S4D卷积核:范德蒙德矩阵乘法:
- 当 A A A是对角矩阵时,计算卷积核变得非常简单: K ℓ = ∑ n = 0 N − 1 C n A n ℓ B n K_{\ell}=\sum_{n=0}^{N-1} C_{n} A_{n}^{\ell} B_{n} Kℓ=∑n=0N−1CnAnℓBn
- 这里 K K K 可以表示为 ( B ⊤ ∘ C ) ⋅ V L ( A ) \left(B^{\top} \circ C\right) \cdot V_{L}(A) (B⊤∘C)⋅VL(A),其中 $ \circ$ 是哈达马德积, ⋅ \cdot ⋅ 是矩阵乘法, V V V 是范德蒙德矩阵, V L ( A ) n ℓ = A n ℓ V_{L}(A)_{n \ell}=A_{n}^{\ell} VL(A)nℓ=Anℓ。
总结来说,S4D是一种处理对角SSM的算法,其核心优势在于通过利用对角矩阵的简单性质,简化了计算过程。对角矩阵的解析函数和乘法运算都可以高效地逐元素进行,而范德蒙德矩阵乘法则进一步简化了卷积核的计算。
这里补充说明一些基础数学知识,方便小伙伴看懂:
补充说明1:对角矩阵上的解析函数
指的是对于一个对角矩阵,对其每个对角线上的元素单独应用某个解析函数,并保持矩阵的其他位置为零。这种操作利用了对角矩阵的特性,即除了对角线上的元素外,其他位置的元素都是零。
以 A A A 为一个对角矩阵,其对角线上的元素为 A 11 , A 22 , … , A n n A_{11}, A_{22}, \ldots, A_{n n} A11,A22,…,Ann,那么对 A A A 应用解析函数 f f f 会产生另一个对角矩阵 B B B,其对角线上的元素分别是 f ( A 11 ) , f ( A 22 ) , … , f ( A n n ) f\left(A_{11}\right), f\left(A_{22}\right), \ldots, f\left(A_{n n}\right) f(A11),f(A22),…,f(Ann)。例如,如果我们对一个对角矩阵 A A A应用指数函数 e x e^{x} ex,那么结果 B B B 将是一个新的对角矩阵,其对角线上的元素是 e A 11 , e A 22 , … , e A n n e^{A_{11}}, e^{A_{22}}, \ldots, e^{A_{n n}} eA11,eA22,…,eAnn
这种处理方式在计算上非常有效,因为只涉及到对角线上的元素,而忽略了所有零元素。在状态空间模型(SSM)等领域,这种方法常被用来简化问题和提高计算效率。
补充说明2:对角矩阵的矩阵乘法
对角矩阵的矩阵乘法相对简单。当两个对角矩阵相乘时,结果仍然是一个对角矩阵,其对角线上的元素是原始两个矩阵对应位置元素的乘积。
A = ( a 11 0 ⋯ 0 0 a 22 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ a n n ) B = ( b 11 0 ⋯ 0 0 b 22 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ b n n )
AB= a110⋮00a22⋮0⋯⋯⋱⋯00⋮ann = b110⋮00b22⋮0⋯⋯⋱⋯00⋮bnn AB=⎛⎝⎜⎜⎜⎜⎜a110⋮00a22⋮0⋯⋯⋱⋯00⋮ann⎞⎠⎟⎟⎟⎟⎟=⎛⎝⎜⎜⎜⎜⎜b110⋮00b22⋮0⋯⋯⋱⋯00⋮bnn⎞⎠⎟⎟⎟⎟⎟ A × B = ( a 11 b 11 0 ⋯ 0 0 a 22 b 22 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ a n n b n n ) A \times B =\left(
\right) A×B= a11b110⋮00a22b22⋮0⋯⋯⋱⋯00⋮annbnn a11b110⋮00a22b22⋮0⋯⋯⋱⋯00⋮annbnn
补充说明3:范德蒙德矩阵
范德蒙德矩阵(Vandermonde matrix)是一种特殊形式的矩阵,它在多项式理论、插值法和各种数学、工程和科学问题中都有应用。一个标准的范德蒙德矩阵是由向量的连续幂构成的。
假设有一个向量 α = ( α 1 , α 2 , … , α n ) \alpha=\left(\alpha_{1}, \alpha_{2}, \ldots, \alpha_{n}\right) α=(α1,α2,…,αn),则相应的范德蒙德矩阵 V V V 形式如下:
V = ( 1 α 1 α 1 2 ⋯ α 1 n − 1 1 α 2 α 2 2 ⋯ α 2 n − 1 ⋮ ⋮ ⋮ ⋱ ⋮ 1 α n α n 2 ⋯ α n n − 1 ) V=\left(
\right) V= 11⋮1α1α2⋮αnα12α22⋮αn2⋯⋯⋱⋯α1n−1α2n−1⋮αnn−1 11⋮1α1α2⋮αnα21α22⋮α2n⋯⋯⋱⋯αn−11αn−12⋮αn−1n 范德蒙德矩阵在多项式插值中尤为重要,特别是在拉格朗日插值法中,它被用来构造通过一组点的多项式。此外,在信号处理和系统理论中,范德蒙德矩阵也被用于各种应用,如频率分析和滤波器设计。
补充说明4:当矩阵是对角阵时,利用范德蒙德矩阵的结构可以显著简化计算过程
假设给定的向量 α = ( α 1 , α 2 , … , α n ) \alpha=\left(\alpha_{1}, \alpha_{2}, \ldots, \alpha_{n}\right) α=(α1,α2,…,αn)及其对应的范德蒙德矩阵如说明3,当对角矩阵 A A A 是一个对角阵时,比如说: A = ( α 1 0 ⋯ 0 0 α 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ α n ) A=\left(
\right) A= α10⋮00α2⋮0⋯⋯⋱⋯00⋮αn α10⋮00α2⋮0⋯⋯⋱⋯00⋮αn 在这种情况下,范德蒙德矩阵 V L ( A ) V_{L}(A) VL(A) 中的每一列实际上就是对角矩阵 的 A A A幂。因此,计算 V L ( A ) V_{L}(A) VL(A) 变得非常简单,只需将 A A A 的对角元素分别取幂。
当涉及到对角矩阵和范德蒙德矩阵的乘法时,计算过程也会简化。例如,在状态空间模型(SSM)的卷积核计算中,如果 A A A 是对角矩阵,那么范德蒙德矩阵 V L ( A ) V_{L}(A) VL(A) 的计算和进一步的矩阵乘法运算都会变得更简单、更直接。因为对角矩阵的幂运算仅涉及到对角元素的幂运算,这大大减少了计算量。
补充说明5:公式 K ‾ ℓ = ∑ n = 0 N − 1 C n A ‾ n ℓ B ‾ n ⟹ K ‾ = ( B ‾ ⊤ ∘ C ) ⋅ V L ( A ‾ ) \overline{\boldsymbol{K}}_{\ell}=\sum_{n=0}^{N-1} \boldsymbol{C}_{n} \overline{\boldsymbol{A}}_{n}^{\ell} \overline{\boldsymbol{B}}_{n} \Longrightarrow \overline{\boldsymbol{K}}=\left(\overline{\boldsymbol{B}}^{\top} \circ \boldsymbol{C}\right) \cdot \mathscr{V}_{L}(\overline{\boldsymbol{A}}) Kℓ=∑n=0N−1CnAnℓBn⟹K=(B⊤∘C)⋅VL(A)的解读
- K ‾ ℓ \overline{\boldsymbol{K}}_{\ell} Kℓ:
- 这是卷积核的一个元素,表示在第 ℓ {\ell} ℓ 时刻的卷积核值。
- 它是通过对每一个 n n n(从0到 N − 1 N-1 N−1)的状态进行求和来计算的。
- 对于每个 n n n,将 C n C_n Cn(输出矩阵 C C C 的第 n n n个元素)、 A ‾ n ℓ \overline{\boldsymbol{A}}_{n}^{\ell} Anℓ(矩阵 A ‾ \overline{\boldsymbol{A}} A 的第 n n n 个元素的 ℓ \ell ℓ 次幂)、和 B ‾ n \overline{\boldsymbol{B}}_{n} Bn(输入矩阵 B B B 的第 n n n 个元素)相乘。
- K ‾ \overline{\mathbf{K}} K:
- 这是整个卷积核矩阵。
- 它可以通过哈达马德积(元素级别的乘积,表示为 ∘ \circ ∘)和矩阵乘法来计算。
- B ‾ ⊤ ∘ C \overline{\boldsymbol{B}}^{\top} \circ \boldsymbol{C} B⊤∘C表示将 B B B 矩阵的转置和 C C C 矩阵的元素级别乘积。
- V L ( A ‾ ) \mathscr{V}_{L}(\overline{\boldsymbol{A}}) VL(A) 表示将上述乘积与范德蒙德矩阵 V L ( A ‾ ) \mathscr{V}_{L}(\overline{\boldsymbol{A}}) VL(A) 相乘,其中 V L ( A ‾ ) n , ℓ = A ‾ n ℓ \mathscr{V}_{L}(\overline{\boldsymbol{A}})_{n, \ell}=\overline{\boldsymbol{A}}_{n}^{\ell} VL(A)n,ℓ=Anℓ 表示范德蒙德矩阵的一个元素。
由2.2.3节, K ‾ = ( C B ‾ , C A B ‾ , … , C k B ‾ , … ) \overline{\boldsymbol{K}}=\left(\boldsymbol{C} \overline{\boldsymbol{B}}, \boldsymbol{C} \overline{\boldsymbol{A B}}, \ldots, \boldsymbol{C}^{k} \overline{\boldsymbol{B}}, \ldots\right) K=(CB,CAB,…,CkB,…), K ‾ \overline{\mathbf{K}} K可以拆解为Vandermonde 矩阵向量乘法:
K ‾ = [ B ‾ 0 C 0 … B ‾ N − 1 C N − 1 ] [ 1 A ‾ 0 A ‾ 0 2 … A ‾ 0 L − 1 1 A ‾ 1 A ‾ 1 2 … A ‾ 1 L − 1 ⋮ ⋮ ⋮ ⋱ ⋮ 1 A ‾ N − 1 A ‾ N − 1 2 … A ‾ N − 1 L − 1 ] \overline{\boldsymbol{K}}=\left[
\right]\left[B¯¯¯¯0C0…B¯¯¯¯N−1CN−1 \right] K=[B0C0…BN−1CN−1] 11⋮1A0A1⋮AN−1A02A12⋮AN−12……⋱…A0L−1A1L−1⋮AN−1L−1 11⋮1A¯¯¯¯0A¯¯¯¯1⋮A¯¯¯¯N−1A¯¯¯¯20A¯¯¯¯21⋮A¯¯¯¯2N−1……⋱…A¯¯¯¯L−10A¯¯¯¯L−11⋮A¯¯¯¯L−1N−1
由此:对角结构 SSM (S4D) 的解释非常简单
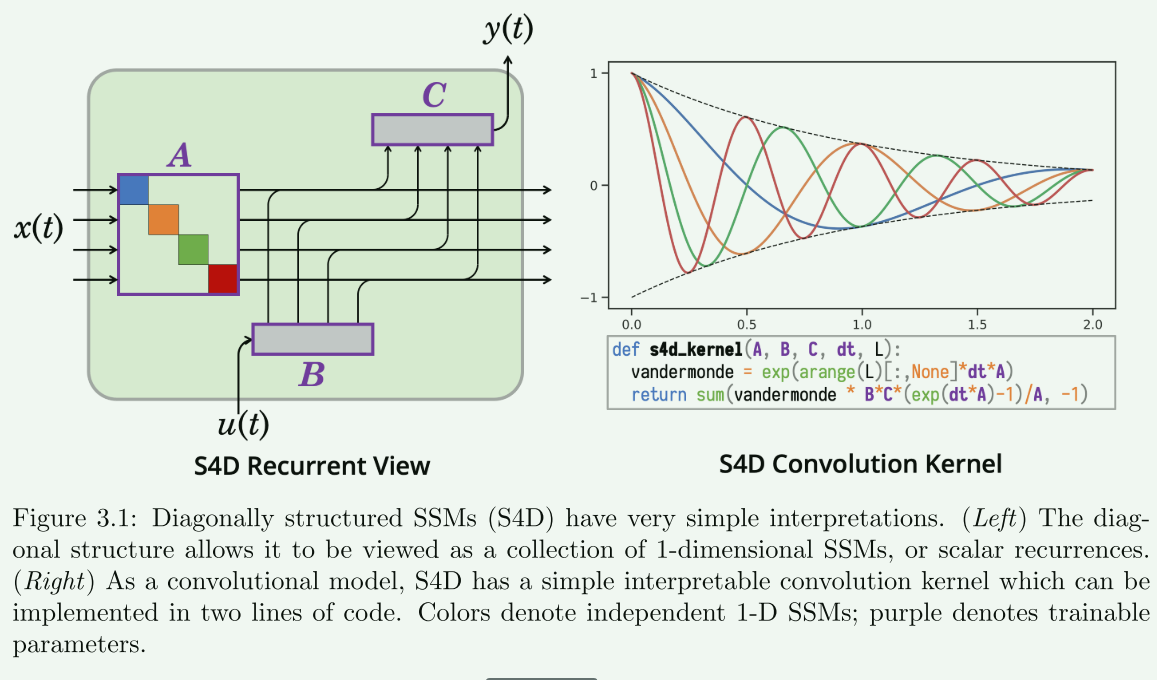
时间复杂度:
具体化 Vandermonde 矩阵 并执行矩阵乘法,这需要 O ( N L ) O(NL) O(NL) 时间和空间。然而,Vandermonde 矩阵经过充分研究,理论上可以在 O ~ ( N + L ) \widetilde{O}(N+L) O (N+L) 运算和 O ( N + L ) O(N + L) O(N+L) 空间中计算乘法 。
3.2.2 Complete Implementation Example
这小节给出了带 ZOH 离散化的 S4D 内核实现,下面给出一些注释,不确保理解正确,欢迎指正:
def parameters(N, dt_min=1e-3, dt_max=1e-1):
# 输入参数为状态大小N和时间尺度的最小、最大值。
# Initialization
# 计算一个几何均匀分布的时间尺度值 [Chapter 5]
log_dt = np.random.rand() * (np.log(dt_max) - np.log(dt_min)) + np.log(dt_min)
# S4D-Lin initialization for (A, B) [Chapter 6]
# 初始化矩阵A的实部和虚部,其实部为-0.5,虚部为从0到N/2的线性序列乘以π
A = -0.5 + 1j * np.pi * np.arange(N//2)
# 初始化矩阵B为全1向量,长度为N/2。
B = np.ones(N//2) + 0j
# Variance preserving initialization [Chapter 5]
# C实部和虚部均为随机正态分布。
C = np.random.randn(N//2) + 1j * np.random.randn(N)
return log_dt, np.log(-A.real), A.imag, B, C
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
def kernel(L, log_dt, log_A_real, A_imag, B, C):
# Discretization (e.g. bilinear transform)
# 根据给定的参数计算离散化后的时间步长dt和矩阵A。
dt, A = np.exp(log_dt), -np.exp(log_A_real) + 1j * A_imag
# 计算离散化后的矩阵dA和dB
dA, dB = (1+dt*A/2) / (1-dt*A/2), dt*B / (1-dt*A/2)
# Computation (Vandermonde matrix multiplication - can be optimized)
# Return twice the real part - same as adding conjugate pairs
# 计算卷积核,通过矩阵乘法(含范德蒙德矩阵)计算出的结果取实部并乘以2
return 2 * ((B*C) @ (dA[:, None] ** np.arange(L))).real
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
def forward(u, parameters):
# 获取输入序列u的长度
L = u.shape[-1]
# 使用kernel函数计算卷积核K
K = kernel(L, *parameters)
# Convolve y = u * K using FFT
# 使用FFT对K和u进行快速傅里叶变换
K_f, u_f = np.fft.fft(K, n=2*L), np.fft.fft(u, n=2*L)
# 计算K和u的卷积,时域的卷积等于频域的乘积,再逆变换回来得到卷积结果
return np.fft.ifft(K_f*u_f, n=2*L)[..., :L]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3 The Diagonal Plus Low-Rank (DPLR) Parameterization
介绍了对角加低秩(Diagonal Plus Low-Rank, DPLR)参数化方法。这是一种扩展对角状态空间模型(SSM)的方法,结合了对角矩阵的简单性和低秩矩阵的灵活性。以下是对这一节内容的总结:
-
对角SSM的局限性:
- 对角SSM在实践中因其简单性和灵活性而理想,但其强固的结构有时可能过于限制性。特别是,基于HIPPO矩阵的SSM(第4章和第5章介绍)不能用对角SSM数值表示,这促使了对角结构的扩展。
-
DPLR参数化的动机和目的:
- 本节旨在从计算角度独立介绍DPLR结构,而不涉及第二部分中特殊SSM的联系。
- DPLR参数化和算法的理念在理论上有独立的兴趣,并已在后续的序列模型中使用。
-
DPLR SSM的定义和计算效率:
- DPLR SSM是对角SSM的扩展,包括对角矩阵和低秩矩阵。
- 技术重点是开发这种参数化方法,并展示如何高效地计算SSM的所有表示。
文章给出了算法,看起来较复杂,随着后续论文阅读逐渐展开解读:

3.3.1 Overview of the DPLR State Space Kernel Algorithm
概述了DPLR状态空间核心算法。这个算法是从对角矩阵到DPLR(对角加低秩)矩阵的一个看似简单的扩展,但这个低秩项的添加使得矩阵的计算变得更加困难。特别是与对角矩阵不同,对DPLR矩阵计算幂(对应方程2.8)仍然缓慢(与非结构化矩阵一样),并不容易优化。
为了克服这个瓶颈,算法采用了三种新技术:
- 不直接计算 K ‾ \overline{\boldsymbol{K}} K,而是通过评估其截断生成函数 ∑ j = 0 L − 1 K ‾ j ζ j \sum_{j=0}^{L-1} \overline{\boldsymbol{K}}_{j} \zeta^{j} ∑j=0L−1Kjζj在单位根 ζ \zeta ζ处的值来计算 K ‾ \overline{\boldsymbol{K}} K的频谱。然后,可以通过应用逆快速傅里叶变换(FFT)找到 K ‾ \overline{\boldsymbol{K}} K。
- 这个生成函数与矩阵求解密切相关,并且现在涉及矩阵求逆而不是幂。现在可以通过应用伍德伯里恒等式来纠正低秩项。
- 最后,证明对角矩阵情况相当于柯西核 1 ω j − ζ k \frac{1}{\omega_{j}-\zeta_{k}} ωj−ζk1 的计算,这是一个经过充分研究的稳定近线性算法问题。
补充说明1:伍德伯里恒等式
Woodbury 矩阵恒等式(Woodbury Identity),又称为矩阵逆引理(Matrix Inversion Lemma),是线性代数中的一个重要公式。这个公式提供了一种计算矩阵的逆的高效方法,特别是当我们对原矩阵作了一些小的修改(如添加一个低秩的矩阵)时。Woodbury 公式是这样的:
( A + U C V ) − 1 = A − 1 − A − 1 U ( C − 1 + V A − 1 U ) − 1 V A − 1 (A+U C V)^{-1}=A^{-1}-A^{-1} U\left(C^{-1}+V A^{-1} U\right)^{-1} V A^{-1} (A+UCV)−1=A−1−A−1U(C−1+VA−1U)−1VA−1
其中 A A A 是一个 n × n n \times n n×n 可逆矩阵, U U U 和 V V V 分别是 $ n \times k$ 和 k × n k \times n k×n 矩阵, C C C 是一个 k × k k \times k k×k 可逆矩阵。这个恒等式在计算机科学、统计学和工程领域中有广泛的应用,尤其是在需要处理大规模数据或计算大型矩阵逆的场合。
简单来说,Woodbury 矩阵恒等式提供了一种计算修改后的矩阵逆的更有效率的方法,尤其是当修改部分的规模较小(即低秩)时。这样可以避免直接计算整个大矩阵的逆,从而节省计算资源和时间。
补充说明2:Cauchy Kernel
柯西核(Cauchy Kernel)是复分析中的一个概念,它在许多数学和工程领域中都有应用。柯西核是柯西积分公式的核心部分,该公式是复分析中最基本和重要的定理之一。
柯西核通常定义为:
1 z − z 0 \frac{1}{z-z_{0}} z−z01
其中, z z z 和 z 0 z_0 z0 是复数,且 z ≠ z 0 z \neq z_{0} z=z0。在这个表达式中, z 0 z_0 z0 是固定的,而 z z z 是变量。
柯西积分公式使用柯西核来表达一个在复平面上的解析函数内部和边界上的值之间的关系。具体来说,如果 f ( z ) f(z) f(z) 是一个在闭合路径及其内部解析的复函数,那么对于路径内的任何点 z 0 z_0 z0 ,该函数在该点的值可以通过沿着闭合路径积分柯西核与 f ( z ) f(z) f(z) 的乘积来计算:
f ( z 0 ) = 1 2 π i ∮ C f ( z ) z − z 0 d z f\left(z_{0}\right)=\frac{1}{2 \pi i} \oint_{C} \frac{f(z)}{z-z_{0}} d z f(z0)=2πi1∮Cz−z0f(z)dz
这里的 C C C 表示围绕点 z 0 z_0 z0 的闭合路径。
柯西核在复变函数理论中扮演着重要角色,因为它不仅用于求解特定点的函数值,还在解析函数的泰勒级数展开、留数定理以及许多其他复分析的核心概念中起着关键作用。此外,在信号处理、控制理论和物理学等领域,柯西核也有着广泛的应用。
3.3.2 S4-DPLR Algorithms and Computational Complexity
涉及S4-DPLR(Structured State Space Models with Diagonal Plus Low-Rank matrices)算法及其计算复杂性。
定理3.5 (S4递归):给定任何步长 Δ \Delta Δ,计算递归的一步 可以在 O ( N ) O(N) O(N) 操作中完成,其中 N N N 是状态大小。
定理 3.6(S4 卷积):给定任何步长 Δ \Delta Δ,计算 SSM 卷积滤波器 K ‾ \overline{\boldsymbol{K}} K可以减少到 4 次柯西乘法,仅需要 O ~ ( N + L ) \widetilde{O}(N+L) O (N+L) 运算和 O ( N + L ) O(N + L) O(N+L) 空间。
3.3.3 Hurwitz (Stable) DPLR Form
3.3.3节主要介绍了Hurwitz(稳定)DPLR形式,这是一种用于确保状态空间模型(SSM)渐近稳定的DPLR(对角加低秩)矩阵的特殊形式。关键点包括:
- Hurwitz矩阵定义:Hurwitz矩阵是指其每个特征值都具有负的实部,这样的矩阵确保了SSM的稳定性。
- 离散时间SSM中的应用:在离散时间SSM中,A矩阵需要是Hurwitz矩阵,以确保在递归神经网络(RNN)模式中的稳定性。
- 连续时间视角:从连续时间的角度来看,线性常微分方程(ODEs)解为指数函数,而Hurwitz矩阵可以防止随时间增长而增大的不稳定性。
- 控制谱的困难:控制一般DPLR矩阵的谱是困难的。早期版本的S4发现,未受限制的DPLR矩阵在训练后通常会变得非Hurwitz,无法在无界递归模式中使用。
- Hurwitz DPLR形式:为了解决这个问题,提出了一种修改后的DPLR矩阵——Hurwitz DPLR形式,使用 Λ − P P ∗ \boldsymbol{\Lambda}-\boldsymbol{P} \boldsymbol{P}^{*} Λ−PP∗而不是 Λ + P Q ∗ \Lambda+P Q^{*} Λ+PQ∗的参数化。这种形式简化了控制 A A A矩阵谱的问题。
- 稳定性的实现:利用Hurwitz DPLR形式,可以更容易地控制状态矩阵 A A A的谱,因为 − P P ∗ -\boldsymbol{P} \boldsymbol{P}^{*} −PP∗是一个负半定矩阵。这种形式使得控制学习的A矩阵的谱变得更简单,仅需控制对角部分 Λ \Lambda Λ。
- 性能影响:尽管Hurwitz DPLR形式的参数较少且表达能力有限,但实际上并不影响模型性能。
补充说明:Hurwitz matrices
Hurwitz 矩阵(有时也称作 Routh-Hurwitz 矩阵)是控制理论和稳定性分析中的一个重要概念。它用于确定一个线性系统的稳定性,特别是用来判断系统的特征方程的所有根是否都位于复平面的左半部分(即具有负实部),这是系统稳定的必要条件。
给定一个线性时间不变系统的特征多项式:
p ( s ) = a n s n + a n − 1 s n − 1 + ⋯ + a 1 s + a 0 p(s)=a_{n} s^{n}+a_{n-1} s^{n-1}+\cdots+a_{1} s+a_{0} p(s)=ansn+an−1sn−1+⋯+a1s+a0
其中 a i a_i ai 是实数系数, s s s 是复变数。这个多项式的根决定了系统的稳定性。
为了构造 Hurwitz 矩阵,按以下方式排列这些系数:
a n − 1 a n − 3 a n − 5 ⋯ ⋯ 0 a n a n − 2 a n − 4 ⋯ ⋯ 0 0 a n − 1 a n − 3 ⋯ ⋯ 0 0 a n a n − 2 ⋯ ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋱ ⋮ 0 0 0 ⋯ a 1 a 0
an−1an00⋮0an−3an−2an−1an⋮0an−5an−4an−3an−2⋮0⋯⋯⋯⋯⋱⋯⋯⋯⋯⋯⋱a10000⋮a0an−1an00⋮0an−3an−2an−1an⋮0an−5an−4an−3an−2⋮0⋯⋯⋯⋯⋱⋯⋯⋯⋯⋯⋱a10000⋮a0 这个矩阵是一个 n × n n \times n n×n 的方阵,其中 n n n 是多项式的次数。按照这种方式,第一列从 a n − 1 a_{n-1} an−1 到 a 1 a_1 a1 依次排列,第二列从 a n a_n an 到 a 0 a_0 a0,以此类推。没有系数填充的位置用零填充。
要判断系统是否稳定,我们需要计算这个 Hurwitz 矩阵的所有顺序主子式的行列式(即从左上角开始,逐步扩大的方阵的行列式)。如果所有这些主子式的行列式都是正的,那么系统是稳定的。这个判据是基于 Routh-Hurwitz 准则,它提供了一种不需要计算特征根的方法来判断系统稳定性。
简而言之,Hurwitz 矩阵是分析控制系统稳定性的一种工具,通过检查其构成的特定矩阵的性质来避免直接计算复杂的根。
3.4 Additional Parameterization Details
本小节讨论了S4模型的额外参数化细节。这部分内容包括:
- 离散化(Discretization):探讨了不同离散化方法之间的折衷,包括欧拉方法和更准确的方法如ZOH和双线性方法。这部分强调了对于S4D,任何离散化方法都是可行的,因为对角矩阵的任何矩阵函数都可以简化为对角线上的元素级函数。
- A的参数化(Parameterization of A):讨论了 A A A的稳定性,特别是在作为自回归生成模型使用时。对于对角SSM, A A A的实部可以通过指数函数来约束,从而保证稳定性。对于DPLR参数化,除了对角部分的约束, A A A还应表示为Hurwitz DPLR形式。
- B和C的参数化(Parameterization of B and C):对于S4D,由于离散卷积核 K ‾ \overline{\boldsymbol{K}} K的计算只依赖于 B B B和 C C C的逐元素乘积,因此可以直接参数化此乘积,而不是学习两个独立参数。
- 复数的使用(Use of Complex Numbers):强调了在对角SSM中使用复数矩阵的重要性,以及复数矩阵在DPLR SSM中的应用。
- 共轭对称性(Conjugate Symmetry):讨论了从实数到复数的转换中的一个小细节,即在对角化实数SSM为复数SSM时,结果参数总是成共轭对的形式出现,因此可以去除一半的参数。
3.5 Comparing S4-Diag and S4-DPLR
本节比较了S4-Diag和S4-DPLR两种模型。这一部分重点分析了这两种模型的性能差异和适用场景:
- 性能差异:文档强调了S4-DPLR在某些任务中比S4-Diag表现更好,尤其是在需要复杂时间动态建模的情况下。
- 参数数量:S4-DPLR具有更多的参数,这使得它能够捕捉更复杂的动态,但也可能导致过拟合。
- 适用性和效率:对于简单的序列建模任务,S4-Diag可能更为高效,因为它参数更少、计算更简单。而S4-DPLR适合于那些需要模型捕捉更复杂动态的高级任务。

