
- 1element切换主题颜色_element color
- 2CVPR2020:点云三维目标跟踪的点对盒网络(P2B)_p2b: point-to-box network for 3d object tracking i
- 3时频域统计特征提取_时频域特征提取
- 4绝对零基础的C语言科班作业⑦(数组)(斐波那契数列)(冒泡排序)_编程找出前1000个素数存放到数组中,然后输入一个整数n,输出第n个素数的值。
- 5小白攻略(三):数学建模论文的写作_数学建模公式自己编吗
- 6HarmonyOS鸿蒙基于Java开发: Java UI 使用工具自动生成JS FA调用PA代码
- 7计算机视觉三大顶级会议CVPR,ECCV,ICCV论文下载地址_nips,cvpr等顶会论文下载
- 8场景异步切换_unity 删除 asyncoperation
- 9【正点原子Linux连载】 第七章 新字符设备驱动实验 摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南
- 10利用@media screen实现网页布局的自适应_@media only screen and
Redis学习笔记_redis save <指定时间间隔> <执行指定次数更新操作>
赞
踩
redis学习笔记
官网:https://redis.io/
redis下载地址:https://download.redis.io/releases/
1. redis安装
1.1.1 解压安装包
tar -zvxf redis-6.0.10.tar.gz
- 1
1.1.2 检查gcc环境是否存在
gcc --version
- 1
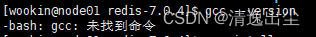
1.1.3 安装gcc环境
yum install gcc
- 1
1.1.3.1 测试gcc是否安装成功

1.1.4 编译redis
make
- 1
1.1.4.1 编译发现报错
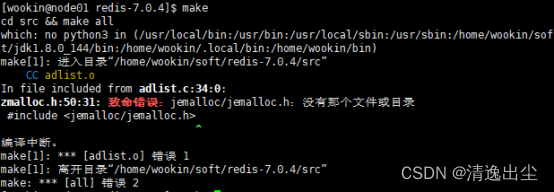
1.1.4.2 清理编译文件重新编译
make distclean
- 1
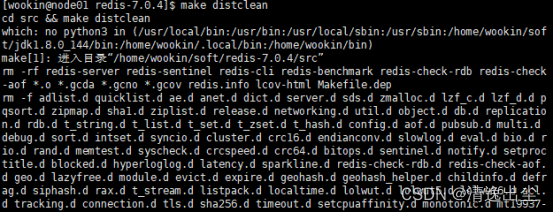
make
- 1
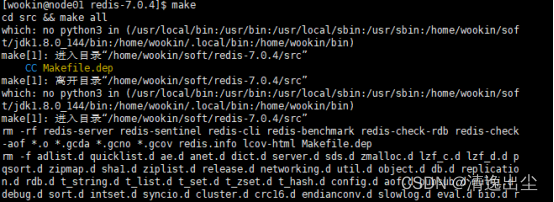
1.1.4 安装redis
make install
- 1
1.2 启动redis
1.2.1 启动redis服务
redis-server redis-conf
- 1
1.2.2 启动redis客户端
redis-cli
- 1
1.3 redis配置文件介绍
# 指定 redis 只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求 bind 127.0.0.1 #是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问,拒绝外部访问。要是开启了密码和bind,可以开启。否则最好关闭,设置为no protected-mode yes #redis监听的端口号 port 6379 #此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度, 当然此值必须不大于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511,而Linux的默认参数值是128。当系统并发量大并且客户端速度缓慢的时候,可以将这二个参数一起参考设定。该内核参数默认值一般是128,对于负载很大的服务程序来说大大的不够。一般会将它修改为2048或者更大。在/etc/sysctl.conf中添加:net.core.somaxconn = 2048,然后在终端中执行sysctl -p tcp-backlog 511 #此参数为设置客户端空闲超过timeout,服务端会断开连接,为0则服务端不会主动断开连接,不能小于0 timeout 0 #tcp keepalive参数。如果设置不为0,就使用配置tcp的SO_KEEPALIVE值,使用keepalive有两个好处:检测挂掉的对端。降低中间设备出问题而导致网络看似连接却已经与对端端口的问题。在Linux内核中,设置了keepalive,redis会定时给对端发送ack。检测到对端关闭需要两倍的设置值 tcp-keepalive 300 #是否在后台执行,yes:后台运行;no:不是后台运行 daemonize yes #redis的进程文件 pidfile /var/run/redis/redis.pid #指定了服务端日志的级别。级别包括:debug(很多信息,方便开发、测试),verbose(许多有用的信息,但是没有debug级别信息多),notice(适当的日志级别,适合生产环境),warn(只有非常重要的信息) loglevel notice #指定了记录日志的文件。空字符串的话,日志会打印到标准输出设备。后台运行的redis标准输出是/dev/null logfile /usr/local/redis/var/redis.log #是否打开记录syslog功能 #syslog-enabled no #syslog的标识符。 #syslog-ident redis #日志的来源、设备 # syslog-facility local0 #数据库的数量,默认使用的数据库是0。可以通过”SELECT 【数据库序号】“命令选择一个数据库,序号从0开始 databases 16 ################################### SNAPSHOTTING ################################### #RDB核心规则配置 save <指定时间间隔> <执行指定次数更新操作>,满足条件就将内存中的数据同步到硬盘中。官方出厂配置默认是 900秒内有1个更改,300秒内有10个更改以及60秒内有10000个更改,则将内存中的数据快照写入磁盘。若不想用RDB方案,可以把 save "" 的注释打开,下面三个注释 # save "" save 900 1 save 300 10 save 60 10000 #当RDB持久化出现错误后,是否依然进行继续进行工作,yes:不能进行工作,no:可以继续进行工作,可以通过info中的rdb_last_bgsave_status了解RDB持久化是否有错误 stop-writes-on-bgsave-error yes #配置存储至本地数据库时是否压缩数据,默认为yes。Redis采用LZF压缩方式,但占用了一点CPU的时间。若关闭该选项,但会导致数据库文件变的巨大。建议开启。 rdbcompression yes #是否校验rdb文件;从rdb格式的第五个版本开始,在rdb文件的末尾会带上CRC64的校验和。这跟有利于文件的容错性,但是在保存rdb文件的时候,会有大概10%的性能损耗,所以如果你追求高性能,可以关闭该配置 rdbchecksum yes #指定本地数据库文件名,一般采用默认的 dump.rdb dbfilename dump.rdb #数据目录,数据库的写入会在这个目录。rdb、aof文件也会写在这个目录 dir /usr/local/redis/var ################################# REPLICATION ################################# # 复制选项,slave复制对应的master。 # replicaof <masterip> <masterport> #如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。 # masterauth <master-password> #当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no,INFO,replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG,SUBSCRIBE, UNSUBSCRIBE,PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB,COMMAND, POST, HOST: and LATENCY命令之外的任何请求都会返回一个错误”SYNC with master in progress”。 replica-serve-stale-data yes #作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议) #replica-read-only yes # 是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。 repl-diskless-sync no #diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。所以最好等待一段时间,等更多的slave连上来 repl-diskless-sync-delay 5 #slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。 # repl-ping-slave-period 10 # 复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时 # repl-timeout 60 #是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。默认是no,即使用tcp nodelay。如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。但是这也可能带来数据的延迟。默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes repl-disable-tcp-nodelay no #复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m # repl-backlog-size 1mb # master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。 # repl-backlog-ttl 3600 # 当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。而配置成0,永远不会被选举 replica-priority 100 #redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能 # min-replicas-to-write 3 # 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave # min-replicas-max-lag 10 # 设置1或另一个设置为0禁用这个特性。 # Setting one or the other to 0 disables the feature. # By default min-replicas-to-write is set to 0 (feature disabled) and # min-replicas-max-lag is set to 10.

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
参考博客:redis配置文件中常用配置详解
1.4 redis数据类型
常用指令:
切换数据库命令:select x
查看DB大小:DBSIZE
数据库存储值:set key vale
获取值:get key
exists key:判断是否存在该key值,存在该key值则返回1,不存在返回0
keys *:查看数据库所有的key
flushdb:清空当前数据库
flushall:清空所有数据库
expire key xxx:设置key值xxx秒过期
ttl key:查看该key值剩余多少秒过期
persist key:取消过期
type key:查看当前key的类型
dbsize:查看当前库的key的数量
del key:删除key
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.4.1 String
String是Redis最基本的数据类型,一个Redis中字符串的value最多可以是512M
1.4.1.1 常用命令
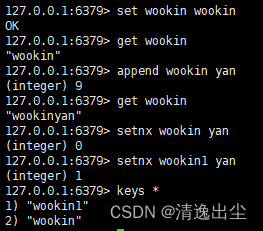
set key value //设置值或者修改值 get key //获取key的value值 append key value //将指定的value最加到原值的末尾 strlen key //获取值得长度 setnx key value //只有在key不存在时,设置key的值 incr key //将key中存储的值增1,只能对数值操作,如果为空,新增值为1 decr key //将key中存储的值减1,只能对数值操作,如果为空,新增值为-1 incrby key num //将key中存储的值减num,只能对数值操作,如果为空,新增值为-num或者num mset k1 v1 k2 v2 //同时设置一个或者多个key-value对 mget k1 k2 k3 //同时获取一个或者多个value msetnx k1 v1 k2 v2 //同时设置一个或者多个key-value对,仅当所有的key都不存在 getrange key 起始位置 结束位置 //获取值得范围类似Java中的subString,前包,后包 setrange key 起始位置 value //在原有值得第某个位置插入value expire key seconds //设置key的过期时间,秒为单位 ttl key //查看key的过期时间, -1永不过期, -2以过期 setex key 过期时间 value //设置键值得同时设置过期时间,单位秒 getset key value //以新换旧,设置新值得时候获取旧值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

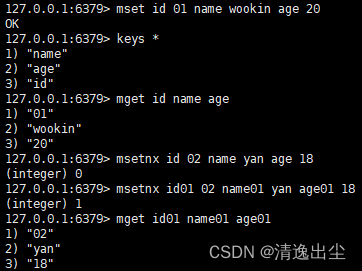
1.4.1.2 应用场景
参考博客:五种数据类型及其使用场景
- “某某综艺”,启动海选投票,只能通过微信投票,每个微信号每4个小时只能投1票。
- 电商商家开启热门商品推荐,热门商品不能一直处于热门期,每种商品热门期维持3天,3天后自动取消热门
- 新闻网站会出现热点新闻,热点新闻最大的特征是对时效性,如何自动控制热点新闻的时效性
1.4.1.2 数据结构
String的数据结构为简单动态字符串(Simple Dynameic String, 缩写SDS)。是可以修改的的字符串,内部结构实现上类似Java的ArrayList,采用预分配冗余空间的范式来减少内存的频繁分配。
1.4.2 List
1.4.2.1 常用命令
lpush k1 v1 v2 v3 //从左边插入一个或者多个值
rpush k1 v1 v2 v3 //从右边插入一个或者多个值
lpop key //从左边吐出一个值
rpop key //从右边吐出一个值
rpoplpush key1 key2 //从key1列表右边吐出一个值,插入到key2列表的左边
lrange key 0 -1 //取出列表左边第一个到右边第一个的所有值
lindex key index //按照索引下标获得元素(从左往右)
llen key //获取列表的长度
linsert key before value newvalue //在数据value的后面插入newvalue
lrem key n value //从左边删除n个value
lset key index value //将列表下标为index的值替换为value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
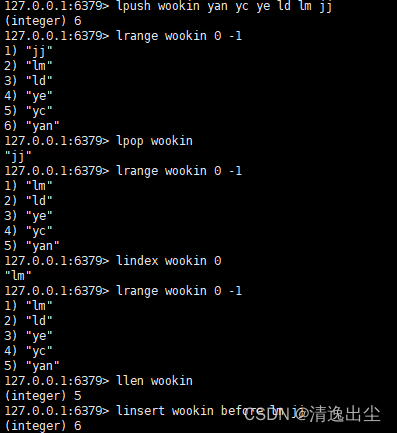
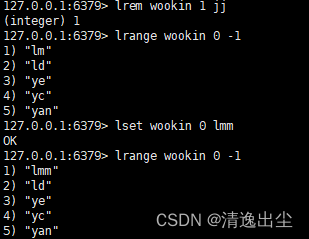
1.4.2.2 列表数据结构
list的数据结构为快速链表quickList。首先在列表元素较少的情况下会使用一块联系的内存存储,这个结构是ziplist,即压缩列表。当数据量比较大的时候才会变成quickList。Redis将链表和ziplist组合起来就组成了quickList。也就是将多个ziplist使用双向指针串起来使用。这样满足了快速插入删除,又不会出现太大空间冗余。
1.4.3 Set
1.4.3.1 常用指令
sadd key value1 value2 //将一个或者多个元素加入到集合key中(value重复将忽略)。
smembers key //去出所有值
sismember key value //判断集合key中是否存在value,有1,没有0
scard key //返回改集合元素的个数
srem key value1 value2 //删除集合中的value1,value2
spop key //随机从key集合中吐出一个值
srandmember key n //随机从key集合中取出n个值,不会删除集合中的值
smove source desination value //把集合中的一个值从一个集合移动到另一个集合
sinter key1 key2 //返回两个集合的交集元素
sunion key1 key2 //返回两个集合的并集元素
sdiff key1 key2 //返回两个集合中的差集元素(key1中的,不包含key2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
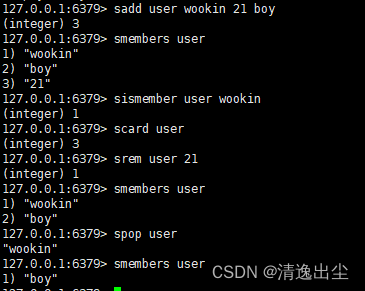
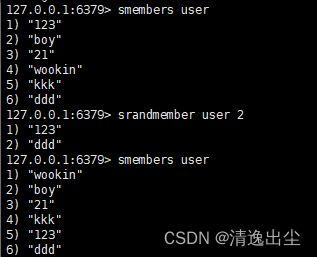

1.4.3.2 数据结构
set数据结构是dict字典,字典是用哈希表实现的。类似与Java中的hashSet。
1.4.4 Hash
hash是一个键值对集合。
1.4.4.1 常用命令
hset key field value //给集合key中的field进行赋值
hget key filed //从集合key中取出field的值
hmset key field1 value field2 value1 //批量赋值
hexists key field //查看集合key中是否存在field
hkeys key //列出key中所有的field
hvals key //列出key中所有的value
hincrby key field increment //为哈希表key中的field的值加上增量1
hsetnx key field value //将哈希表key中field的值设置为value,当且仅当field不存在
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
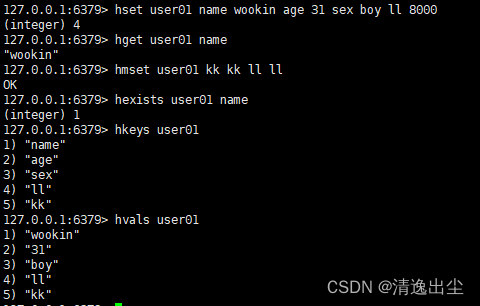
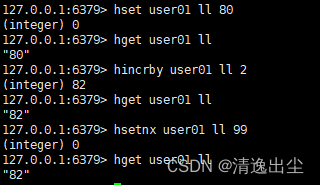
1.4.4.2 数据结构
hash对应的数据结构有两种:ziplist, hashtable。当field-value长度较短且个数较少时,使用ziplist, 否则使用hashtable
1.4.5 Zset
zset是一个没有重复元素的有序集合。
1.4.5.1 常用指令
zadd key score1 value score2 value //将一个或者多个member和score值加入到有序集合key中
zrange key start stop <WITHSCORES> //返回有序集key中下标在start和stop之间的元素。带WITHSCORES,可以让分数一起和值返回到结果集
zrangebyscore key minmax [withscores] [limit offset count] //返回有序集key中所有score值介于min和max之间(包括min和max)。即按照分数从小到大排序
zrevrangebyscore key max min //从大到小排序
zincrby key increment value //为元素的score加上增量
zrem key value //删除元素value
zcount key min max //统计该集合,分数区间内的元素个数
zrank key value //返回该值在结合中的排名,从0开始
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
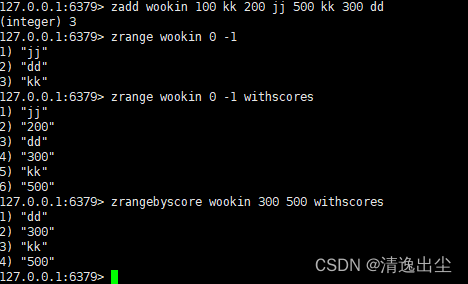
1.4.5.2 数据结构
zset底层使用了两个数据结构:hash和跳表
1.5 常见面试问题
1.5.1 缓存穿透
问题描述:
redis和数据库中没有相关数据。redis无法拦截,直接被穿透到数据库,导致数据库压力过大宕机。
解决方案
- 对不存在的数据缓存在redis中,值存为null。并设置过期时间
- 对参数进行效验,不合法参赛进行拦截
1.5.2 缓存击穿
问题描述
热点数据失效,高并发直接打到数据库。
解决方案
- 设置热点数据永不过期
- 加上互斥锁
1.5.3 缓存雪崩
问题描述:
在高并发下,大量的缓存key在同一时间失效,大量的请求直接落在数据库上,导致数据库宕机。
解决方案:
- 随机设置key的失效时间,避免大量key集体失效。
- 诺是集群部署,可将热点数据均匀部署在不同的redis库中
- 热点key不设置失效时间
- 跑定时任务,在缓存失效时间前刷新缓存
1.5.4 Redis的数据过期淘汰机制
定期删除 + 惰性删除策略
定期删除:定时器监视所有的数据,判断key是否过期,过期就删除。
惰性删除:在获取key时,先判断key是否过期,如果过期就删除。
redis还有内存淘汰机制:
- volatile-lru:从已设置过期时间的数据集中选出使用少的数据淘汰
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
- volatile-radom:从已设置过期时间的数据集任意挑选数据淘汰
- allkeys-lru:内存不足新数据写入时,移除最近最少使用的key
- allkeys-random:任意挑选数据淘汰
- no-eviction:永不过期
- volatile-lfu:从已设置过期时间的数据集挑选最不经常用的的数据淘汰
- allkeys-lfu:当内存不够时,删除最不经常用的数据
1.5.5 单线程的Redis为什么这么快
- redis是完全基于内存的,读取效率高
- 单线程操作避免了频繁的切换上下文,频繁切换上下文会影响性能
- 合理高效的数据结构
- 采用了非阻塞IO多路复用机制。
1.5.6 redis实现分布式锁
参考文章:如何用Redis实现分布式锁
redis设置分布式锁的思路是:
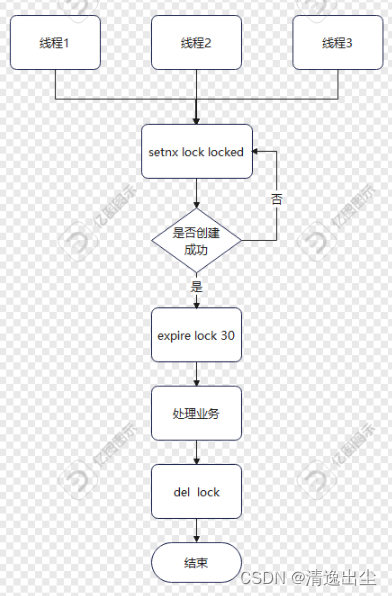
1.5.6.1 分布式锁的要求
- 互斥性。(在分布式集群中,同一个方法在同一时间只能被一台机器上的一个线程获得)。
- 可重入性(递归调用不应该被阻塞、避免死锁)。
- 锁的超时(避免死锁、死循环等意外情况)。
- 加锁和解锁必须为同一客户端(除非锁到期自动收回,否则加锁和解锁需为同一客户端)。

