
- 1python爬虫beautifulsoup爬当当网_利用python爬虫可视化分析当当网的图书数据!
- 2nginx报错client_body_temp permission denied_nginx body 超报错
- 3python爬虫可以做哪些好玩的_Python爬虫解读哪个景点人少又好玩!
- 4rust运行shell命令并获取输出_rust 执行shell
- 5打造智能障碍物检测系统:从零开始的深度学习项目
- 6Flink从入门到实践(一):Flink入门、Flink部署_flink 从入门到精通
- 7Rabbitmq与Erlang对应版本关系_rabbitmq和erlang版本对应
- 8android ble_android ble 存在
- 9MongoDB的安全认证详解_mongodb 认证
- 10浏览器自动化利器Selenium IDE使用指南
集群式Hadoop,Spark,Hive的集群安装_hive和hadoop可以不装在同一台服务器吗
赞
踩
原因
因为赛题要求必须要使用大数据的东西,所以我们搭建了Hadoop的集群,用Spark分析数据,为了方便spark不直接对Hadoop操作,Spark对Hive的操作更方便,所以我们安装了Hive,在这里对Hadoop,Hive和Spark的简介我就不做赘述,但需要注意的一点,因为我们集群式的搭建,在Hadoop2.0以上的版本,Spark可以直接在Hadoop集群上面运行,并且通过yarn进行管理。
Hadoop的安装
3 台服务器,都是阿里云的,一台作为master、另外2台的作为slave1、slave2,系统是 centos7.6x64,如果使用服务器搭建 hadoop 最好是在同一个 vpc 里面的,不同的网落之间会有奇奇怪怪的情况,我这里为了省钱,三台是学生轻量级应用服务器
因为Hadoop是需要运行在Java的环境中的,所以三台主机都是需要安装jdk的,我这里安装的是jdk1.8。
JDK的安装
jdk1.8的下载地址下载jdk-8u291-linux-x64.tar.gz
我这里的安装路径是 /usr/local/src/,通过 FTP把 jdk 上传
#mkdir java
#cd java
#tar zxvf 包名

配置java的系统路径
vim ~/.bashrc
JAVA_HOME=/usr/local/src/java/jdk1.8.0_291
export PATH="$JAVA_HOME/bin:$PATH
使修改生效
bash
- 1
- 2
- 3
- 4
- 5

输入java -version出现java版本号即证明jdk安装成功

再次强调三台机器都需要安装JDK
设置三台机器的hostname
#vim ~/.bashrc

修改完hostname以后
#bash
#hostname

这个地方我好像遇到了一个问题,hostname确实是改了,但是我的并不是root@master,再次重连以后才变成master,另外两台主机也需要重复上面的操作
设置DNS
这里要注意的是,对于master机器端的配置,master设置的是内网ip,slave1、slave2设置的是外网ip,slave1、slave2机器的配置同理
master机器:
master的内网ip master
slave1的外网ip slave1
slave2的外网ip slave2
slave1机器:
master的外网ip master
slave1的内网ip slave1
slave2的外网ip slave2
内网的 ip 地址可以通过 ifconfig查看
#vim /etc/hosts
3 台机器都设置好dns之后,互相 ping 一下,看能否 ping 通

对于小白来说第一次使用ping命令时不知道如何结束ping命令,命令使用CTRL+C结束

设置SSH免密登录
以 master 机器为例,ssh-keygen一路回车
注意:ssh最好设置中间遇到bug也要解决,不然后面Hadoop运行不起来,大概率是因为ssh免密登录没有设置好
#ssh-keygen

在master执行
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
在slave1执行
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
在对master执行ssh连接时我遇到了一个问题,master的ssh无法实现,即使密码输入的正确仍然无法连接,我在网上查阅了各种的资料,各种配置我全都改了,还是没有解决问题,后来发现是因为ssh对文件的操作权限有限制
- .ssh目录的权限必须是700
进入ssh目录默认的目录路径是 /etc/ssh
chomd 700 ssh
- .ssh/authorized_keys文件权限必须是600
chomd 600 . .ssh/authorized_keys
将文件的权限修改完以后master成功实现ssh连接
在 master 上使用ssh命令,另外两台同理
ssh slave1
ssh slave2

出现图片中的情况即为成功
安装Hadoop
因为我们这里还需要安装Spark和HIve,所以要注意版本之间的兼容性问题,特别要注意Hadoop和Spark的版本问题,我这安装的Hadoop是2.6.5版本的,你可以选择其他版本的,你可以访问GitHub上的官方Spark项目,下载你可能要用的Spark的源码压缩包,去看他的poxm文件,里面记载兼容的Hadoop和Hive版本,2.6.5版本兼容的Spark版本为2.4.5,Hive版本为1.2.1,
另外和JDK一样三台机器都是需要上传Hadoop的包的,以master机器为例,我仍然将他上传到/usr/local/src目录中
tar xvzf hadoop-2.6.5.tar.gz
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH="\$HADOOP_HOME/bin:$PATH"
使修改生效
bash
- 1
- 2
- 3
- 4
- 5
- 6
切换到 /usr/local/src/hadoop-2.6.5/etc/hadoop
修改 hadoop-env.sh
#vim hadoop-env.sh
大概在第25行加上 JAVA_HOME

验证
hadoop

修改 yarn-env.sh
vim yarn-env.sh
在里面添加
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_291
修改slaves文件,里面添加从节点
vim slaves
里面的localhost不能删掉!!!

修改 core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/tmp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
修改 mapred-site.xml
先复制一份模板
# cp mapred-site.xml.template mapred-site.xml
# vim mapred-site.xml
- 1
- 2
- 3
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
修改 yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
修改 hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/src/hadoop-2.6.5/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/src/hadoop-2.6.5/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在 HADOOP_HOME 目录,创建 3 个空目录
# mkdir tmp
# mkdir -p dfs/name
# mkdir -p dfs/data
- 1
- 2
- 3
用 scp 将 master 的配置同步到 slave1、slave2
# cd /usr/local/src/hadoop-2.6.5/etc
# scp -rp hadoop/ slave1:/usr/local/src/hadoop-2.6.5/etc
# scp -rp hadoop/ slave2:/usr/local/src/hadoop-2.6.5/etc
- 1
- 2
- 3

验证集群
进入 hadoop 的 bin 目录,初始化 hdfs 集群
注意!这个命令只能执行一次,后面别再执行第二次了,不然从节点的datanode的id会对不上,导致你在从节点用 jps 命令查看进程时发现没有datanode,可以改过来但是步骤非常的麻烦,所以要注意不要使用两次这个命令
hdfs namenode -format
- 1

运行 hdfs

查看 master 上的进程

查看 slave1、slave2 上的进程

主机出现六个,从机出现三个即可证明Hadoop安装成功
Spark的安装
因为Spark的运行是需要Scala的环境所以我们需要安装Scala,其实那个poxm文件中也包括了Scala的版本介绍我这里安装的Scala-2.11.12版本的,上传Scala到/usr/local/src目录中,注意:因为Spark是交给yarn管理的,所以我们只需要在master主机上安装Spark即可
# tar zxvf scala-2.11.12.tgz
- 1
配置环境变量
vim ~/.bashrc
SCALA_HOME=/usr/local/src/scala-2.11.12
export PATH="$SCALA_HOME/bin:$PATH"
使修改生效
bash
- 1
- 2
- 3
- 4
- 5

输入scala -version

出现版本号证明scala安装成功
配置Spark
进入Spark安装目录
cd /usr/local/src/spark-2.4.5-bin-hadoop2.6
复制模板
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
在最后加上Hadoop的配置目录
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.5/etc/hadoop
- 1
- 2
- 3
- 4
- 5
- 6
配置环境变量
vim ~/.bashrc
SPARK_HOME=/usr/local/src/spark-2.4.5-bin-hadoop2.6
export PATH="$SPARK_HOME/bin:$PATH"
使修改生效
bash
- 1
- 2
- 3
- 4
- 5

Spark的启动
进入Spark的安装目录
cd /usr/local/src/spark-2.4v.5-bin-hadoop2.6
- 1
接着就可以使用命令启动Spark了,前提是Hadoop必须在运行中
spark-shell --master yarn --deploy-mode client
- 1

出现这个图证明配置成功,这个启动稍微有点慢,记得耐心等待(我是在刷抖音中度过的【手动滑稽】)
bug
你第一次启动时可能不会成功,可能会报以下的错误
ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:89)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:63)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:500)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:933)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:924)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:924)
at org.apach
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
后来我去看了Hadoop的运行状态发现主从机的namenodemanager都没有启动,在网上查阅说是yarn-site.xml的问题“
解决办法:
1.停止Hadoop,进入Hadoop的安装目录,执行以下命令
./sbin/stop-all.sh
- 1
2.进入配置文件目录
cd ./etc/hadoop
- 1
3.修改yarn-site.xml,添加两个属性
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.分发到两个从机中
scp yarn-site.xml/ slave1:usr/local/src/hadoop-2.6.5/etc/hadoop/ yarn-site.xml
scp yarn-site.xml/ slave2:usr/local/src/hadoop-2.6.5/etc/hadoop/ yarn-site.xml
- 1
- 2
5.重启Hadoop,namenodemanager重新出现
./sbin/start.all.sh
- 1

6.重启Spark,命令上面有,发现Spark启动成功
注意:退出Spark的命令为:quit,不要使用CTRL+C,否则下次启动会出现问题
Hive的安装
Hive的安装和Spark的安装一样,都是只需要在一台主机上安装即可
根据poxm文件我们发现Hive的版本兼容是1.2.1的,全称为:apache-hive-1.2.1-bin.tar.gz
安装Hive
1.使用FTP上传hive文件

2.解压
tar zxvf apache-hive-1.2.1-bin.tar.gz
- 1
3.重命名:将文件命名为hive文件
mv apache-hive-1.2.1-bin hive
- 1
4.配置环境变量
vim ~/.bashrc
HIVE_HOME=/usr/local/src/hive
export PATH="$HIVE_HOME/bin:$PATH"
使修改生效
bash
- 1
- 2
- 3
- 4
- 5

执行hive --version
hive --version
- 1
有hive的版本显现,安装成功!
bug1
在这里你可能会遇到jar冲突的问题导致hive安装不成功
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected at jline.TerminalFactory.create(TerminalFactory.java:101) at jline.TerminalFactory.get(TerminalFactory.java:158) at jline.console.ConsoleReader.(ConsoleReader.java:229) at jline.console.ConsoleReader.(ConsoleReader.java:221) at jline.console.ConsoleReader.(ConsoleReader.java:209) at org.apache.hadoop.hive.cli.CliDriver.setupConsoleReader(CliDriver.java:787) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:721) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136) Exception in thread “main” java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected at jline.console.ConsoleReader.(ConsoleReader.java:230) at jline.console.ConsoleReader.(ConsoleReader.java:221) at jline.console.ConsoleReader.(ConsoleReader.java:209) at org.apache.hadoop.hive.cli.CliDriver.setupConsoleReader(CliDriver.java:787) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:721) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这个bug的出现是因为hive的jline jar包和Hadoop yarn/lib文件下的jline jar包不兼容导致,解决办法
将Hadoop下面的jar包换成hive里面的jar包,我是直接使用Ftp软件操作的具体使用命令操作的你可以去网上查一查,这里不再赘述
文件配置
进入hive的配置文件目录
cd /usr/local/src/hive/conf/
- 1
1.修改hive-site.xml:

这里没有,我们就以模板复制一个:
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
- 1
- 2
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --><configuration> <!-- WARNING!!! This file is auto generated for documentation purposes ONLY! --> <!-- WARNING!!! Any changes you make to this file will be ignored by Hive. --> <!-- WARNING!!! You must make your changes in hive-site.xml instead. --> <!-- Hive Execution Parameters --> <!-- 插入一下代码 --> <property> <name>javax.jdo.option.ConnectionUserName</name>用户名(这是新添加的,记住删除配置文件原有的哦!) <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name>密码 <value>123456</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name>mysql <value>jdbc:mysql://localhost:3306/hive</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name>mysql驱动程序 <value>com.mysql.jdbc.Driver</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!-- 到此结束代码 --> <property> <name>hive.exec.script.wrapper</name> <value/> <description/> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2.复制mysql的驱动程序到hive/lib下面(这里已经拷贝好了)
[root@s100 lib]# ll mysql-connector-java-5.1.46-bin.jar
-rw-r--r-- 1 root root 789885 1月 4 01:43 mysql-connector-java-5.1.46-bin.jar
- 1
- 2
3.在mysql中hive的schema(在此之前需要创建mysql下的hive数据库)初始化mysql数据库
schematool -dbType mysql -initSchema
- 1
4.执行hive命令
hive
- 1
bug2
这里会出现第二个bug你会发现初始化mysql数据库并不会成功报错信息如下:
Error: Syntax error: Encountered “” at line 1, column 64. (state=42X01,code=30000)
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
Underlying cause: java.io.IOException : Schema script failed, errorcode 2
Use --verbose for detailed stacktrace.
*** schemaTool failed ***
- 1
- 2
- 3
- 4
- 5
出现这个错误是因为
执行命令:cp hive-default.xml.template ./hive-site.xml 复制文件并在hive-site.xml文件里配置关于mysql的一些连接信息的配置
问题就是出在hive-site.xml
hive-default.xml.template 的开头就写明了 WARNING!!!对该文件的任何更改都将被Hive忽略
其实hive-site.xml是用户定义的配置文件 hive在启动的时候会读取两个文件一个是hive-default.xml.template 还有一个就是hive-site.xml 当执行cp复制命令时 hive-site.xml 里就有了hive-default.xml.template的内容 当你继续写入关于mysql的配置保存后进行初始化hive mysql时就会报这个错误,然后hive的Metastore 服务起不来。
解决办法
在复制的hive-site.xml里保存你写的配置项,然后将其他的删掉
hive-site.xml只能写你自己的配置项,其他删掉
执行之前的初始化命令,发现hive已经启动成功
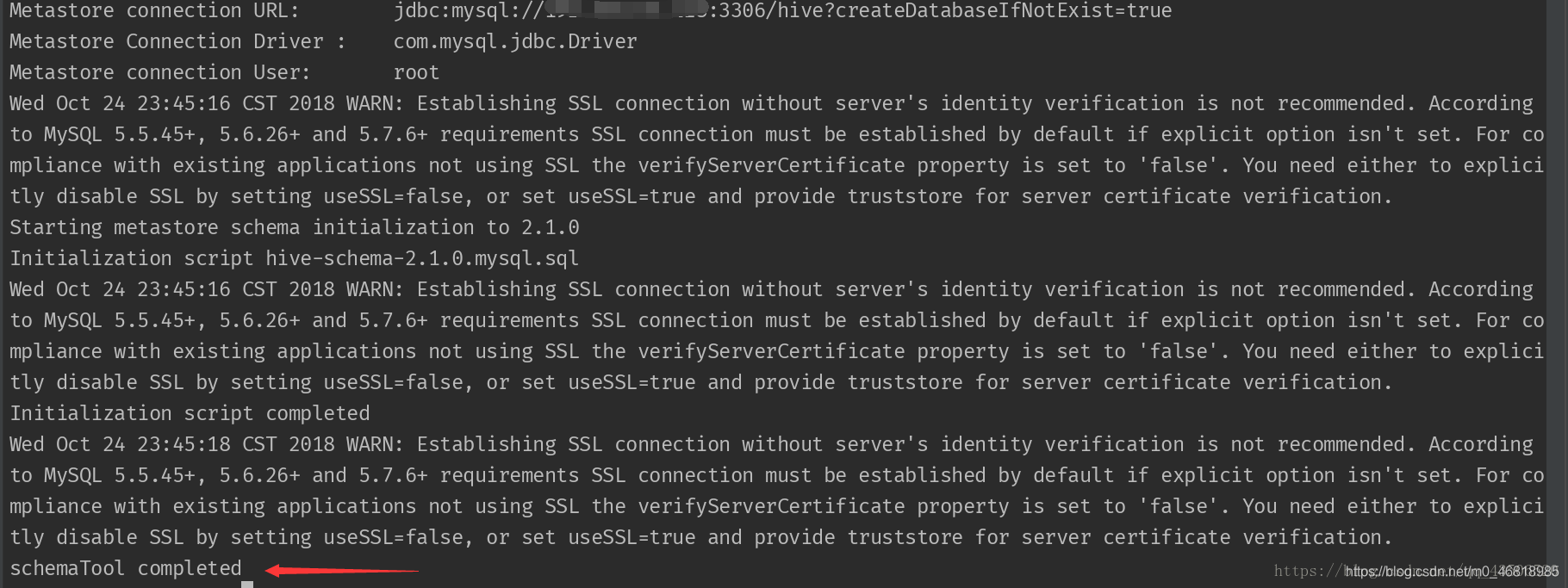
可能你搭建过程中还会出现其他bug,我也是第一次搭建,这次博客只是记录一下搭建过程,不足之处还望批评指正,如果有其他的bug,请参考其他技术大牛的文章

