
- 1OpenCV实现图像平移、旋转_opencv 图像旋转
- 2英文学习单词记录_美[e s kr n s]
- 3gitee创建项目到多人协作_gitee多人协作
- 4前端vue-改造el-table,表头,表格(边框,背景色)_vue边框颜色
- 5基于NXP IMX8M + FPGA体外诊断POCT设备
- 6【计算机网络】TCP握手与挥手:三步奏和四步曲_四次挥手的作用
- 7C++ 自己实现一个unordered_map(hashmap)_c++unorderedmap实现
- 8第四届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2025)
- 9DuiLib简介与控件使用说明
- 10【动态规划】C++解决01背包问题(模板01背包、分割等和子集、目标和、最后一块石头的重量)_01背包模板
【国内 AI大模型产业发展深度分析 2024】
赞
踩
文末有福利!
伴随人工智能技术的加速演进,AI 大模型已成为全球科技竞争的新高地、未来产业的新赛道、经济发展的新引擎,发展潜力大、应用前景广。近年来,我国高度重视人工智能的发展,将其上升为国家战略,出台一系列扶持政策和规划,为 AI 大模型产业发展创造了良好的环境。
**2024 年,多重利好因素将推动大模型快速发展,首先是“人工智能+”行动等来自政府层面的有力支持,其次用户提升生活、工作效率的需求激增,再加上科技公司加大对 AI 领域投入资金、人力、技术研发,各环节协同支撑大模型发展。
第一章 扬帆起航:中国 AI 大模型产业发展背景
1.1 中国 AI 大模型产业发展政策驱动力
2024 年《政府工作报告》中提出开展“人工智能+”行动。伴随人工智能领域中大模型技术的快速发展,我国各地方政府出台相关支持政策,加快大模型产业的持续发展。
-
北京着力推动大模型相关技术创新,构建高效协同的大模型技术产业生态;
-
上海强调打造具备国际竞争力的大模型;
-
深圳重点支持打造基于国内外芯片和算法的开源通用大模型,支持重点企业持续研发和迭代商用通用大模型;
2023 年以来我国各地出台的大模型产业相关政策
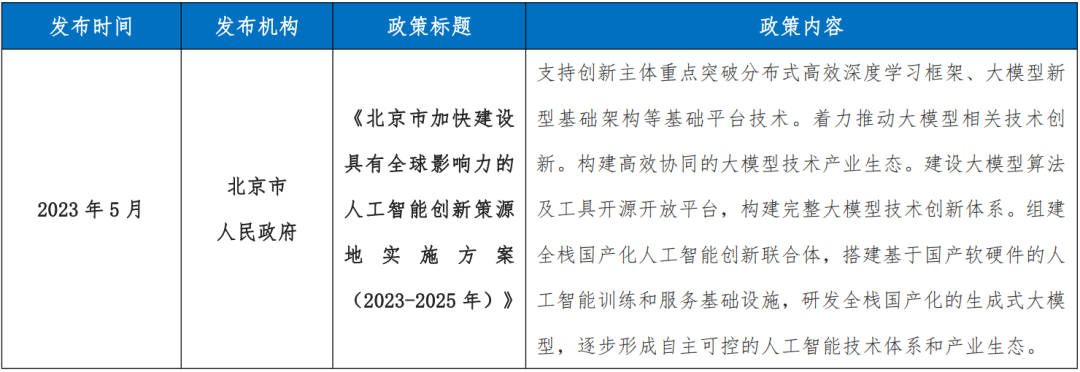
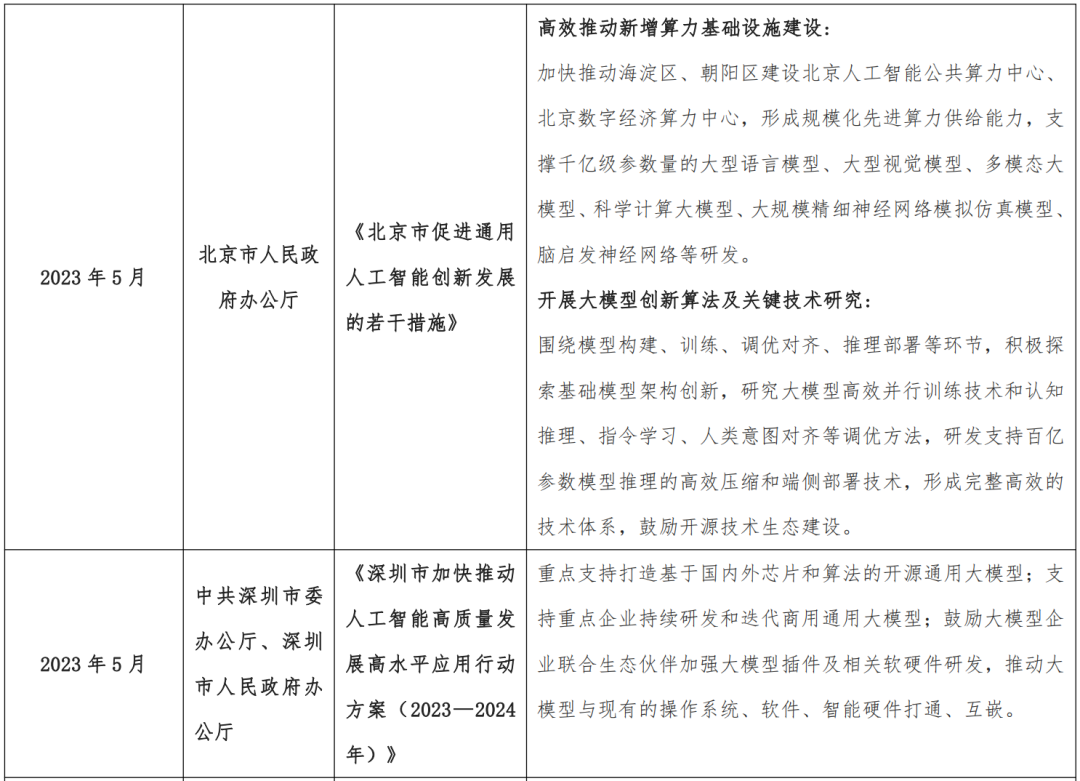

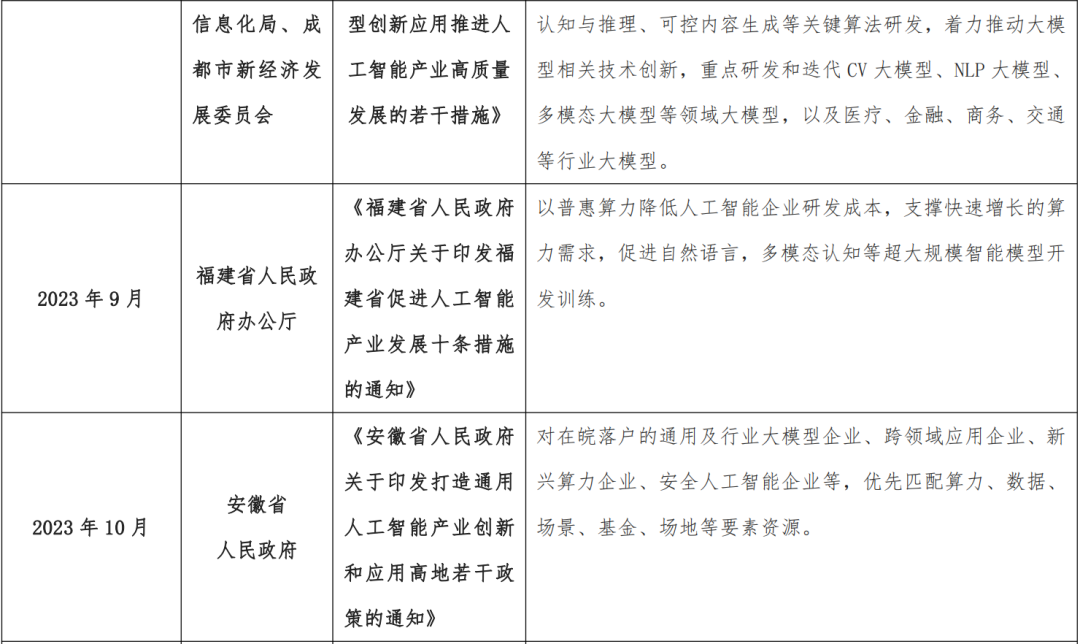
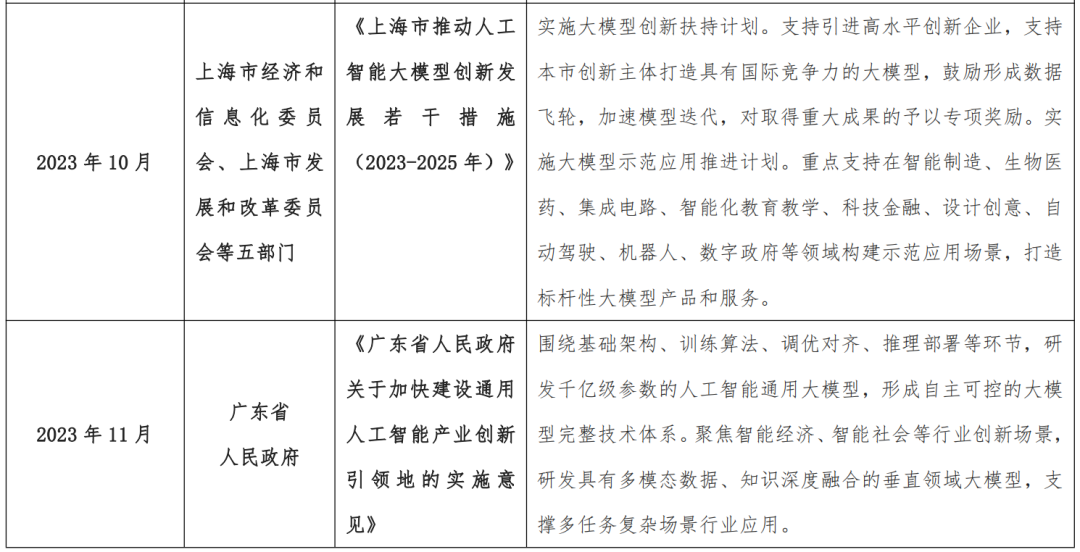
1.2 AI 大模型产业发展技术驱动力
2022 年,OpenAI 推出 ChatGPT,其拥有强大的自然语言交互与生成能力。2023 年,OpenAI 多模态预训练大模型GPT-4 发布,其具备多模态理解与多类型内容生成能力。2024 年,OpenAI 发布视频生成大模型 Sora,提出时空碎片和扩散 Transformer 技术,大模型的多模态生成能力的进一步成熟。本部分将从经典 Transformer 架构出发,通过全面梳理基于人类反馈强化学习、指令微调、提示学习等相关大模型技术,体现技术对于产业发展的带动作用。
1.2.1 Transformer 架构
Transformer 架构是目前语言大模型采用的主流架构,于 2017 年由 Google提出,其主要思想是通过自注意力机制获取输入序列的全局信息,并将这些信息通过网络层进行传递,Transformer 架构的优势在于特征提取能力和并行计算效率。
Transformer 架构图
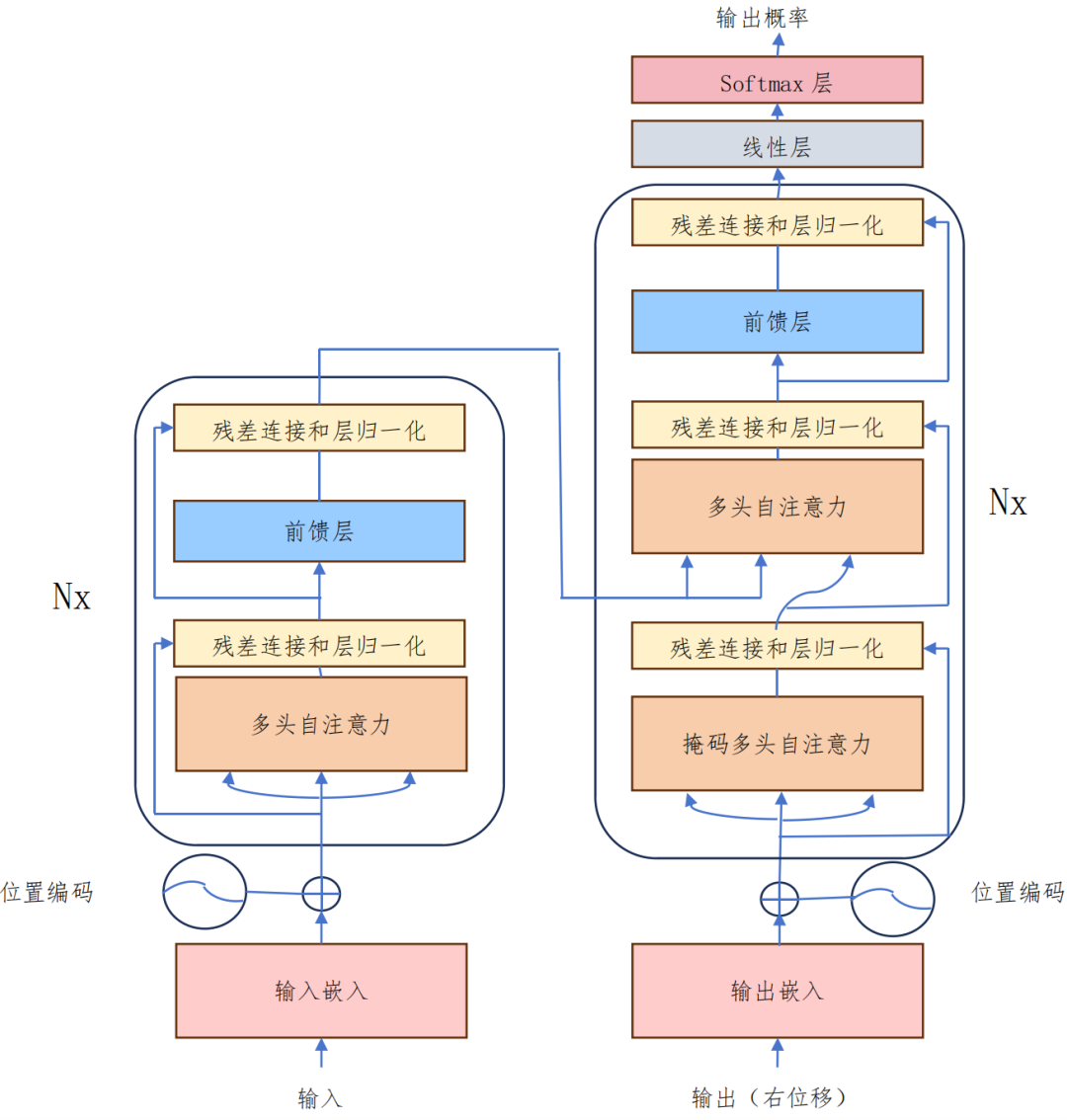
自注意力机制作为 Transformer 模型的核心组件,其允许模型在处理序列数据时,对每个词位置的输入进行加权求和,得到一个全局的上下文表示。
在计算自注意力和多头自注意力之后,Transformer 模型使用前馈神经网络对输入序列进行变换。前馈神经网络由多个全连接层组成,每个全连接层都使用 ReLU激活函数。前馈神经网络的作用是对输入序列进行非线性变换,以捕捉更复杂的特征。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~ , 【保证100%免费】

篇幅有限,部分资料如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/941280
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

