
- 1S4-FPGA-K7板级原理图硬件实战_k7config bank
- 2ElastaticSearch -- es批量插入数据_es 批量插入
- 3mac版Sublime Text菜单汉化问题解决_mac版的subline怎么改中文
- 4接口安全错误合集_如果服务器不需要支持webdav请禁用webdav,或禁用掉不安全的ht tp方法,iis在iis服
- 5Linux基础IO操作详解_linux操作io
- 6八大排序之交换排序与计数排序_交换排序的基本思想和性质
- 7项目管理中的指导委员会是什么?有什么作用?_项目指导委员会
- 8LayaAir引擎78款3D射击主题微信小游戏分享,看看玩过几款!
- 9Quartus做FFT(详细看这篇就够了)_quartus ipcore fft
- 10Windows安装Hadoop_window启动hadoop启动不了提示window找不到yarn
1、HDFS整体概述_hdfs 填空题
赞
踩
1 设计特点
HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
特点:
- 能够运行在廉价机器上,硬件出错常态需要具备高容错性
- 流式数据访问,而不是随机读写
- 面向大规模数据集,能够进行批处理、能够横向扩展
- 简单一致性模型,假定文件是一次写入、多次读取
缺点:
- 不支持低延迟数据访问
- 不适合大量小文件存储(因为每条元数据占用空间是一定的)
- 不支持并发写入,一个文件只能有一个写入者
- 不支持文件随机修改,仅支持追加写入
2 系统架构
HDFS采用master/slave架构。一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的namespace、处理客户端对文件的访问请求。Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。
Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。Namenode和Datanode都是设计成可以跑在普通的廉价的运行Linux的机器上。HDFS采用java语言开发,因此可以部署在很大范围的机器上。一个典型的部署场景是一台机器跑一个单独的Namenode节点,集群中的其他机器各跑一个Datanode实例。这个架构并不排除一台机器上跑多个Datanode,不过这比较少见。
Hadoop 1.x 官方系统架构如图所示:
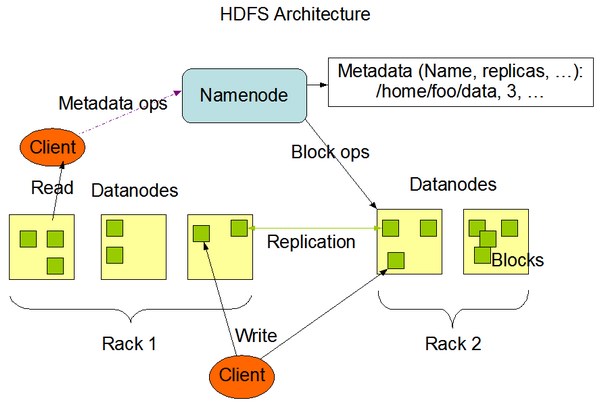
Hadoop 1.x 只有一个Namenode,所有元数据由惟一的Namenode负责管理,当这个NameNode挂掉时整个集群基本也就不可用,因此存在单点故障。Hadoop 2.x 系统架构如图所示:
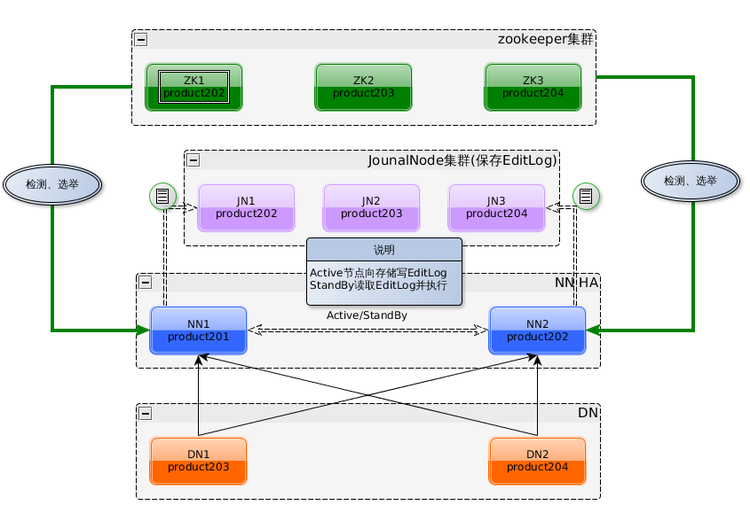
Hadoop 2.x中,HDFS架构解决了单点故障问题,即引入双NameNode架构,同时借助共享存储系统来进行元数据的同步,共享存储系统类型一般有几类,如:Shared NAS+NFS、BookKeeper、BackupNode 和 Quorum Journal Manager(QJM),上图中用的是QJM作为共享存储组件,通过搭建奇数结点的JournalNode实现主备NameNode元数据操作信息同步。
3 重要概念
3.1 数据块
HDFS上的文件被划分为多个块,作为独立的存储单元,默认块大小为128MB。HDFS中小于一个块大小的文件不会占据整个块的空间,例如当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB。
HDFS中的块为什么这么大?HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因为,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。但是块大小这个参数也不会设置得过大,MapReduce中map任务通常一次只处理一个块中的数据,因此如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢。
对分布式文件系统中的块进行抽象会带来很多好处。
- 第一个好处 是一个文件的大小可以大于网络中任意一个磁盘的容量。
- 第二个好处 是使用抽象块而非整个文件作为存储单元,大大简化了存储子系统的设计。
- 第三个好处 是块还非常适合用于数据备份进而提供数据容错能力和提高可用性。
HDFS将每个块复制到少数几个物理上相互独立的机器上(默认为3个),可以确保在块、磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会从其他地方读取另一个复本,而这个过程对用户是透明的。一个因损坏或机器故障而丢失的块可以从其他候选地点复制到另一台可以正常运行的机器上,以保证复本的数量回到正常水平。同样,有些应用程序可能选择为一些常用的文件块设置更高的复本数量进而分散集群中的读取负载。
3.2 NameNode(管理节点)
NameNode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件(fsimage)和编辑日志文件(edits log)。
在Namenode启动时,会加载磁盘镜像到内存中以进行元数据的管理,存储在NameNode内存;磁盘镜像是某一时刻HDFS的元数据信息的快照,包含所有相关Datanode节点文件块映射关系和命名空间(Namespace)信息,存储在NameNode本地文件系统;日志文件记录client发起的每一次操作信息,即保存所有对文件系统的修改操作,用于定期和磁盘镜像合并成最新镜像,保证NameNode元数据信息的完整,存储在NameNode本地和共享存储系统(QJM)中。
4 高可用性
https://www.pianshen.com/article/2758201725/
Hadoop 2.X 以上版本增加了对HDFS高可用性(HA)的支持。在这一实现中,配置了一对活动-备用(active-standby) NameNode。当活动NameNode失效,备用NameNode就会接管它的任务并开始服务于来自客户端的请求,不会有任何明显中断。实现这一目标需要在架构上做如下修改。HDFS HA架构图如下所示:
- NameNode之间需要通过高可用共享存储实现编辑日志的共享。当备用NameNode接管工作之后,它将通读共享编辑日志直至末尾,以实现与活动NameNode的状态同步,并继续读取由活动NameNode写入的新条目。
- DataNode需要同时向两个NameNode发送数据块处理报告,因为数据块的映射信息存储在NameNode的内存中,而非磁盘。
- 客户端需要使用特定的机制来处理NameNode的失效问题,这一机制对用户是透明的。
- 辅助NameNode的角色被备用NameNode所包含,备用NameNode为活动的NameNode命名空间设置周期性检查点。
有两种高可用性共享存储可以做出选择:NFS过滤器或群体日志管理器(QJM, quorum journal manager)。QJM是一个专用的HDFS实现,为提供一个高可用的编辑日志而设计,被推荐用于大多数HDFS部署中,同时,QJM的实现并没使用Zookeeper,但在HDFS HA选举活动NameNode时使用了Zookeeper技术。QJM以一组日志节点(journalnode)的形式运行,一般是奇数点结点组成,每个JournalNode对外有一个简易的RPC接口,以供NameNode读写EditLog到JN本地磁盘。当写EditLog时,NameNode会同时向所有JournalNode并行写文件,只要有N/2+1结点写成功则认为此次写操作成功,遵循Paxos协议。其内部实现框架如下:
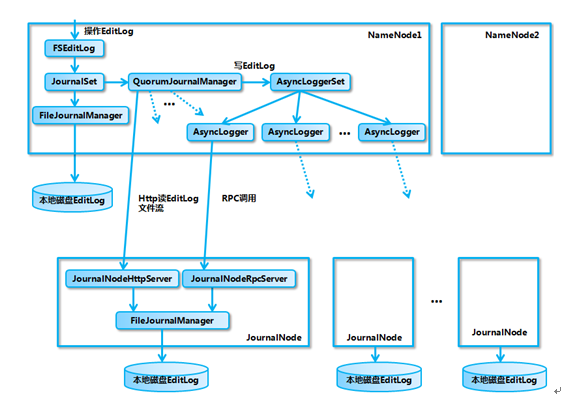
参考文章
https://www.cnblogs.com/luengmingbiao/p/11235327.html#_label3

