
- 1cv2读取和保存图片_cv2 imread 保存
- 2接口测试工具Apifox 基础篇:前置脚本_apifox前置脚本
- 3【Git工具篇01】Git仓库的三大区域及简单操作(十分详细简单带图示操作)_git的仓库区是什么
- 4服务器Ubuntu系统安装_服务器安装ubuntu
- 5【2024最新版】Mysql数据库安装全攻略:图文详解(Windows版本)_windows安装mysql
- 6【STM32】USART UART 串口通信详解【原理】_uart与usart 引脚连接
- 7Python_vperfect.meidd.xyz
- 8jwt 的 token 被获取怎么办_jwt被盗用怎么解决
- 9Github代码fork之后,如何与原仓库进行同步?_git从fork的源仓库同步代码
- 10了解一下 Redis 并在 CentOS 下进行安装配置_《了解一下 redis 并在 centos 下进行安装配置
【面试考点】HashMap的扩容机制、put详解、源码分析,考点问题解答_hashmap,put流程,为什么扩容,扩容机制
赞
踩
前言
第一次面试被问到了HashMap和HastTable,还是很久之前学JavaSE的时候了解过,忘得差不多。第一次面试又没有做特别的准备,所以答的很不好。现在好好总结一下。本文很多内容都基于:
https://blog.csdn.net/v123411739/article/details/78996181
监于红黑树部分,由于个人能力问题,并没有深究总结。
目录
问:为什么 UNTREEIFY_THRESHOLD 定为6?
(2)计算key的hash值时为什么这么做 (h = key.hashCode()) ^ (h >>> 16) ?
(1)扩容后,某条链表节点在新表中位置为什么只可能分布在 “原索引位置” 与 “原索引 + oldCap” ?
HashMap结构
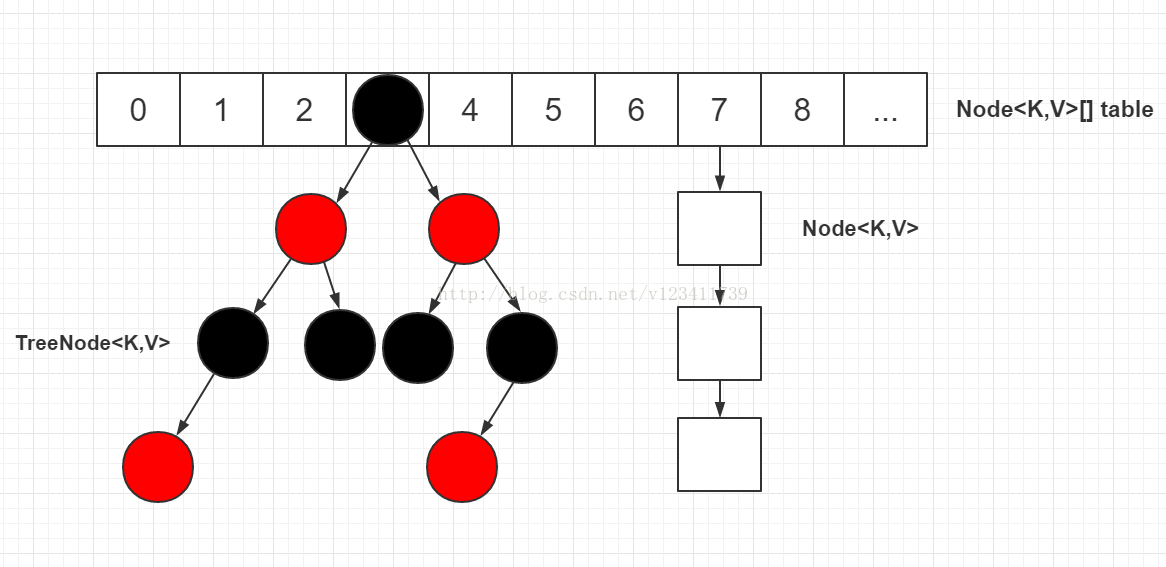
Node
单链表节点
- static class Node<K,V> implements Map.Entry<K,V> {
- // key的hash值
- final int hash;
-
- final K key;
- V value;
-
- Node<K,V> next;
-
- }
红黑树节点
- static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
- TreeNode<K,V> parent; // red-black tree links
- TreeNode<K,V> left;
- TreeNode<K,V> right;
- TreeNode<K,V> prev; // needed to unlink next upon deletion
- boolean red;
- }
- // LinkedHashMap.Entry<K,V>
- static class Entry<K,V> extends HashMap.Node<K,V> {
- Entry<K,V> before, after;
- Entry(int hash, K key, V value, Node<K,V> next) {
- super(hash, key, value, next);
- }
- }
静态变量介绍
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
默认的初始容量为16。注意:capacity 和 size 的区别。
capacity:容量,是指table(哈希桶)的长度
size:当前map中的已存的节点个数(包括单链表或红黑树的节点)
static final int MAXIMUM_CAPACITY = 1 << 30;
最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子。用于计算阈值。
static final int TREEIFY_THRESHOLD = 8;
单链表转换为红黑树的阈值。当某条单链表的节点个数 >= 8时,单链表将转为红黑树。
static final int UNTREEIFY_THRESHOLD = 6;
红黑树转换为单链表的阈值。在扩容时,某棵红黑树的节点重新哈希映射(红黑树拆分),当节点个数少于6个时,将红黑树转换为单链表。(下面结合代码会详细讲)
static final int MIN_TREEIFY_CAPACITY = 64;
转为红黑树时,要求table(哈希桶)的最小长度为64。
问:为什么 UNTREEIFY_THRESHOLD 定为6?
当链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
变量介绍
transient Node<K,V>[] table;
这就是所谓的 “哈希桶”。table数组的大小总是2的整数次幂。
transient int size;
当前map中已有的节点个数
int threshold;
触发扩容机制的阈值。threshold = capacity * loadFactor
put操作详解
1. 原理
(1)将key的hash值对哈希桶取模,得出键值对在table中的目标索引 index
(2)判断table[index]是否为空,如果为空,则为键值对新建一个节点并直接放到table[index]上,作为单链表的头节点
(3)如果table[index]不为空,则说明此处已经存在链表或红黑树
① 如果是红黑树节点,调用TreeNode的putTreeVal()来添加节点。
② 如果是链表节点,则遍历节点,逐一比较hash值,如果哈希值相同且key的equals()比较相同,则将链表中的节点替换掉。如果遍历到链表尾部,没有发现相同的key,则新建一个节点接到链表尾部。同时判断链表长度是否>=8(TREEIFY_THRESHOLD ),如果是,则调用treeifyBin() 将链表转成红黑树。
注意:
我们要分清楚侧重点,我们了解的是 put 的原理。红黑树的相关操作,能力有限,暂时不去深究。
2. 代码注释
- public V put(K key, V value) {
- return putVal(hash(key), key, value, false, true);
- }
-
- // 通过key的hashCode来计算hash值
- static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
-
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
- boolean evict) {
- Node<K,V>[] tab; Node<K,V> p; int n, i;
- // 如果table数组没有初始化,则调用resize()方法来扩容,从而初始化
- if ((tab = table) == null || (n = tab.length) == 0)
- n = (tab = resize()).length;
- // hash对n(table.length)取模,得出key在table数组中的索引位置index
- // 如果位置为空,则new一个链表节点放进去
- if ((p = tab[i = (n - 1) & hash]) == null)
- tab[i] = newNode(hash, key, value, null);
- else {
- // table[index]不为空,说明,此处已经形成链表或者红黑树
- // 此时,p指向table[index]中的节点,之后会不断修改
- // e是一个中间变量,暂存插入位置的节点
- Node<K,V> e; K k;
- // 如果头节点和key的hash值相同,且equals()比较相同,则e则为插入位置
- if (p.hash == hash &&
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p;
- // 如果头节点是一个TreeNode,说明此处形成了红黑树,调用TreeNode的putTreeVal()来插入。不做详解
- else if (p instanceof TreeNode)
- e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
- else {
- // 走到这,说明此处,形成了单链表
- // 遍历单链表,寻找插入节点
- for (int binCount = 0; ; ++binCount) {
- // 走到了链表尾部,仍然找不到相同的key,则新建一个节点插入到链表尾部
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- // 如果链表的节点个数>=8,调用treeifyBin()将链表转成红黑树
- // 之索引-1,是因为计数时是从头节点的下一个节点开始。那直接将binCount初始化为1,岂不更容易理解?
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- // 在遍历链表的中途遇到相同的key,直接跳出
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
-
- p = e;
- }
- }
-
- if (e != null) { // existing mapping for key
- // e节点就是已存在的key所在的节点
- V oldValue = e.value;
- // onlyIfAbsent=true:只有缺失才插入。如果存在相同的key,value不作替换
- if (!onlyIfAbsent || oldValue == null)
- e.value = value;
- // 用于LinkedHashMap
- afterNodeAccess(e);
- return oldValue;
- }
- }
- ++modCount;
- // 当前map中的已存的节点个数+1,如果超过阈值,调用resize()执行扩容机制
- if (++size > threshold)
- resize();
- // 用于LinkedHashMap
- afterNodeInsertion(evict);
- return null;
- }

3. 考点
(1)hash值如何映射到table的某个下标?
hash值对table.length取模,得出key在table数组中的索引位置。只是取模的时候,并没有用"%",而是用了位运算:hash & (table.length-1) 来优化
公式:x mod 2^n = x & (1<<n - 1)
这也是table.length必须是2的整数次幂的原因之一!
(2)计算key的hash值时为什么这么做 (h = key.hashCode()) ^ (h >>> 16) ?
让hashCode的高位也参与运算,从而增大hash值的散列程度。
>>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0。
^表示异或。如果相同的位,异或结果为0;不同的位,异或结果位1。
假设table数组的长度很小,hashCode直接对table.length取模来求目标索引(hashCode & table.length-1)。由于table.length比较小,table.length-1高位全为0,导致&运算的结果高位也全是0。这就意味着结果很大程度都取决于table.length,而受随机性比较大的hashCode影响比较小,从而增加了哈希碰撞的概率!

扩容机制详解
1. 原理
注意下面描述中的“表”,均代表Node数组,table(哈希桶)
(1)创建一个新表(Node数组),长度为旧表的2倍,阈值为旧表的2倍
(2)将旧表的所有节点重新进行哈希映射。旧表的某个索引下的链表或红黑树的所有节点,进行重哈希映射之后,在新表中的索引位置必然只有2个选择(后面解释):
① 与在旧表中的索引位置相同
② 为:在旧表中的索引位置 + 旧表的长度(oldCap)
2. 代码注释
- final Node<K,V>[] resize() {
- Node<K,V>[] oldTab = table;
- int oldCap = (oldTab == null) ? 0 : oldTab.length;
- int oldThr = threshold;
- int newCap, newThr = 0;
- // 旧表长度>0,表示table已经被初始化(table会在第一次put的时候调用resize()来初始化)
- if (oldCap > 0) {
- // 如果旧表的长度超过了最大容量(2^30),则oldCap*2超出了Integer.MAX_VALUE,无法进行重新哈希映射
- // 所以创建长度oldCap*2为的新属猪,只能单纯扩大旧表的阈值
- if (oldCap >= MAXIMUM_CAPACITY) {
- threshold = Integer.MAX_VALUE;
- return oldTab;
- }
- // 如果oldCap*2小与2^30,且如果oldCap>=16,则新表的阈值为旧表的2倍
- else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
- oldCap >= DEFAULT_INITIAL_CAPACITY)
- newThr = oldThr << 1; // double threshold
- }
- // 如果oldCap为0,表示table未被初始化的
- // 如果oldThr>0,oldThr存的就是table数组的初始长度(initialCapacity),有参构造函数指定
- else if (oldThr > 0) // initial capacity was placed in threshold
- newCap = oldThr;
- // 如果oldThr为0,表示是空参构造
- else { // zero initial threshold signifies using defaults
- newCap = DEFAULT_INITIAL_CAPACITY;
- newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
- }
- // 如果新表阈值为0,则通过新表容量*新表阈值来计算
- if (newThr == 0) {
- float ft = (float)newCap * loadFactor;
- newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
- (int)ft : Integer.MAX_VALUE);
- }
-
- threshold = newThr;
-
- @SuppressWarnings({"rawtypes","unchecked"})
-
- // 创建新表
- Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
- table = newTab;
-
- // 如果旧表不为空,则遍历所有节点,将所有节点进行重新哈希映射,放到新表中
- if (oldTab != null) {
- for (int j = 0; j < oldCap; ++j) {
- Node<K,V> e;
- if ((e = oldTab[j]) != null) {
- // 将旧表的节点设置为空,方便gc回收空间
- oldTab[j] = null;
- // 头节点,直接重新计算在新表中的索引位置
- if (e.next == null)
- newTab[e.hash & (newCap - 1)] = e;
- // 如果是红黑树节点,则调用TreeNode的split()方法来进心重哈希映射
- else if (e instanceof TreeNode)
- ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
- // 如果是链表节点
- else { // preserve order
- // 用来拼接一条链表,存储的节点在新表中的索引位置与旧表相同 (第一种位置)
- Node<K,V> loHead = null, loTail = null;
- // 用来拼接一条链表,存储的节点的索引位置为:在旧表中的索引位置+oldCap (第二种位置)
- Node<K,V> hiHead = null, hiTail = null;
- Node<K,V> next;
- do {
- next = e.next;
- // 如果e的hash值与oldCap相&之后为0,则扩容后在新表中的索引位置与旧表相同
- if ((e.hash & oldCap) == 0) {
- if (loTail == null) // 如果loTail为空,表示这是第一个节点
- loHead = e; // 将该节点赋值给loHead
- else
- loTail.next = e; // 不是第一个节点,就添加在loTail的后面
- loTail = e; // 维护尾指针,始终指向最后一个节点
- }
- // 如果e的hash值与oldCap相&之后非0,则扩容后在新表中的索引位置为:在旧表中的索引位置+oldCap
- else {
- if (hiTail == null)
- hiHead = e;
- else
- hiTail.next = e;
- hiTail = e;
- }
- } while ((e = next) != null);
- // 如果loTail不为空,说明旧表的链表节点经过重映射后,有一部分分布到了"第一种位置"
- if (loTail != null) {
- loTail.next = null;
- // 将链表接到新表中的对应位置
- newTab[j] = loHead; // "第一种位置": j
- }
- // 如果hiTail不为空,说明旧表的链表节点经过重映射后,有一部分分布到了"第二种位置"
- if (hiTail != null) {
- hiTail.next = null;
- newTab[j + oldCap] = hiHead; // "第二种位置": j+oldCap
- }
- }
- }
- }
- }
- return newTab;
- }
3. 考点
(1)扩容后,某条链表节点在新表中位置为什么只可能分布在 “原索引位置” 与 “原索引 + oldCap” ?
扩容后,在进行链表节点的迁移的时候,jdk 1.8 不像 jdk1.7 那样对节点进行重哈希。而是巧妙地利用了上述规律:某条链表节点在新表中位置只可能分布在 “原索引位置” 与 “原索引 + oldCap”,只有这两种情况!那么就无需再对链表的每个节点重新计算新的下标索引了,这也是,table.length是2的整数次幂的原因之一。下面解释原因。
假设老表的容量为 16,即 oldCap = 16,则新表容量为 16 * 2 = 32,假设节点 1 的 hash 值为:0000 0000 0000 0000 0000 1111 0000 1010,节点 2 的 hash 值为:0000 0000 0000 0000 0000 1111 0001 1010,则节点 1 和节点 2 在老表的索引位置计算如下图计算1,由于老表的长度限制,节点 1 和节点 2 的索引位置只取决于节点 hash 值的最后 4 位。
再看计算2,计算2为新表的索引计算,可以知道如果两个节点在老表的索引位置相同,则新表的索引位置只取决于节点hash值倒数第5位的值,而此位置的值刚好为老表的容量值 16,此时节点在新表的索引位置只有两种情况:“原索引位置” 和 “原索引 + oldCap位置”,在此例中即为 10 和 10 + 16 = 26。由于结果只取决于节点 hash 值的倒数第 5 位,而此位置的值刚好为老表的容量值 16,因此此时新表的索引位置的计算可以替换为计算3,直接使用节点的 hash 值与老表的容量 16 进行位于运算,如果结果为 0 则该节点在新表的索引位置为原索引位置,否则该节点在新表的索引位置为 “原索引 + oldCap 位置”。

(2)为什么table的长度必须是2的整数次幂?
① hash值对table.length取模,得出key在table数组中的索引位置。只是取模的时候,并没有用"%",而是用了位运算:hash & (table.length-1) 来优化。基于公式:x mod 2^n = x & (1<<n - 1)。这也是table.length必须是2的整数次幂的原因之一!
② threshold(阈值) = capacity(哈希桶大小,table长度)* loadFactor(加载因子, 0.75 = 3/4)。table.length为2的整数次幂(>=16),乘以 0.75=3/4,结果为整数。
③ 扩容后,在进行链表节点的迁移的时候,jdk 1.8 不像 jdk1.7 那样对节点进行重哈希。而是巧妙地利用了:某条链表节点在新表中位置只可能分布在 “原索引位置” 与 “原索引 + oldCap”。那么就无需再对链表的每个节点重新计算新的下标索引了。经过上面的原因解释,我们知道,这也是table.length是2的整数次幂的原因之一。
HashMap的初始容量
哈希表的容量,是指table数组的长度。如果用空参构造,则一开始是默认的16。假如用有参构造,传入初始值,那么会怎么样?
前面已经说明了table数组的长度必须是2的整数次幂。假如传入的不是2的整数次幂,如何纠正呢?
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- // tableSizeFor中对initialCapacity中做了纠正处理
- // 并且将纠正后的初始容量暂存到了threshold中,这一点在resize()中的注释也提到并验证了
- this.threshold = tableSizeFor(initialCapacity);
- }
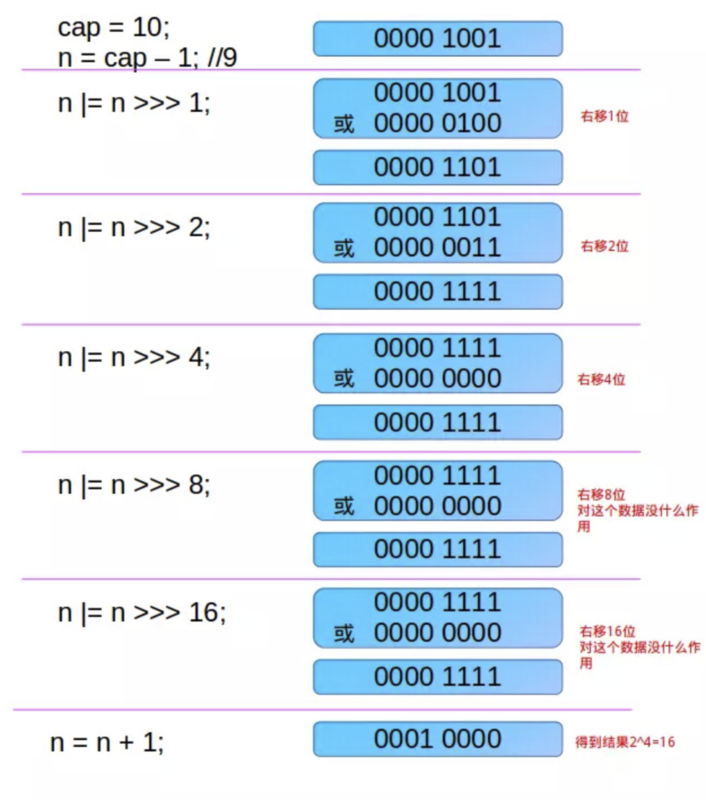
tableSizeFor()函数的作用
纠正并返回初始容量:>= initialCapacity 的 最小的(最接近initialCapacity)的 2的整数次幂
- /**
- * 对initialCapacity作纠正处理
- * 纠正并返回:>= initialCapacity的最小的(最接近initialCapacity)的2的整数次幂
- * 例如:11 -> 16, 8 -> 8
- */
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
tableSizeFor()中的位运算
结合下图,从二进制角度出发,我们发现:中间的5行位运算代码,最终会将 initialCapacity-1 的二进制从最高位到最低位全部变成1。(全1的二进制再+1,就是2的整数次幂).
n |= n >>> 1; // 将 initialCapacity-1 的最高位变成1
n |= n >>> 2; // 将 initialCapacity-1 的从最高位数起,前2位变成1
n |= n >>> 4; // 将 initialCapacity-1 的从最高位数起,前4位变成1
......
由于int值占4个字节,因此最多只需要 >>> 32位。
HashMap 和 Hashtable 的区别
- HashMap 允许 key 和 value 为 null,Hashtable 不允许。
- HashMap 的默认初始容量为 16,Hashtable 为 11。
- HashMap 的扩容为原来的 2 倍,Hashtable 的扩容为原来的 2 倍加 1。
- HashMap 是非线程安全的,Hashtable是线程安全的。
- HashMap 的 hash 值重新计算过,Hashtable 直接使用 hashCode。
- HashMap 去掉了 Hashtable 中的 contains 方法。
- HashMap 继承自 AbstractMap 类,Hashtable 继承自 Dictionary 类。
总结
- HashMap 的底层是个 Node 数组(Node<K,V>[] table),在数组的具体索引位置,如果存在多个节点,则可能是以链表或红黑树的形式存在。
- 增加、删除、查找键值对时,定位到哈希桶数组的位置是很关键的一步,源码中是通过下面3个操作来完成这一步:1)拿到 key 的 hashCode 值;2)将 hashCode 的高位参与运算,重新计算 hash 值;3)将计算出来的 hash 值与 “table.length - 1” 进行 & 运算。
- HashMap 的默认初始容量(capacity)是 16,capacity 必须为 2 的幂次方;默认负载因子(load factor)是 0.75;实际能存放的节点个数(threshold,即触发扩容的阈值)= capacity * load factor。
- HashMap 在触发扩容后,阈值会变为原来的 2 倍,并且会对所有节点进行重 hash 分布,重 hash 分布后节点的新分布位置只可能有两个:“原索引位置” 或 “原索引+oldCap位置”。例如 capacity 为16,索引位置 5 的节点扩容后,只可能分布在新表 “索引位置5” 和 “索引位置21(5+16)”。
- 导致 HashMap 扩容后,同一个索引位置的节点重 hash 最多分布在两个位置的根本原因是:1)table的长度始终为 2 的 n 次方;2)索引位置的计算方法为 “(table.length - 1) & hash”。HashMap 扩容是一个比较耗时的操作,定义 HashMap 时尽量给个接近的初始容量值。
- HashMap 有 threshold 属性和 loadFactor 属性,但是没有 capacity 属性。初始化时,如果传了初始化容量值,该值是存在 threshold 变量,并且 Node 数组是在第一次 put 时才会进行初始化,初始化时会将此时的 threshold 值作为新表的 capacity 值,然后用 capacity 和 loadFactor 计算新表的真正 threshold 值。
- 当同一个索引位置的链表节点的个数>=8时,并且此时table数组的长度大于等于 64,则会触发链表节点(Node)转红黑树节点(TreeNode),转成红黑树节点后,其实链表的结构还存在,通过 next 属性维持。链表节点转红黑树节点的具体方法为源码中的 treeifyBin 方法。而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容。
- 当同一个索引位置的红黑树节点在移除后,个数<= 6 个时,会触发红黑树转成链表。红黑树节点转链表节点的具体方法为源码中的 untreeify 方法。
- HashMap 在 JDK 1.8 之后不再有死循环的问题,JDK 1.8 之前存在死循环的根本原因是在扩容后同一索引位置的节点顺序会反掉。
- HashMap 是非线程安全的,在并发场景下使用 ConcurrentHashMap 来代替。

