1.什么是爬虫
爬虫是指模拟人通过浏览器请求网站服务器获取数据并提取数据的自动化程序.
(1).请求: 使用程序模拟浏览器或网络应用向服务器发起请求
(2).提取数据: 抓取数据后往往这些数据并不全是目标数据, 需要通过程序对数据进行解析, 清洗得到我们想要的数据, 最后将清洗后的数据进行持久化存储.
(3).自动化: 爬取数据往往数据量很大, 需要应用程序代码实现自动抓取.
2.爬虫的基本流程
(1).发起请求: 通过程序模拟浏览器向服务器发起请求, 只有向服务器发起请求, 服务器才有可能向我们响应数据.
(2).获取响应: 向服务器发送请求后, 如果服务器能正常响应, 爬虫程序会获得来自服务器的响应, 即response. 通过对response进行解析可以的到要爬取的数据, 这里的数据可能是HTML, Json字符串, 二进制数据(如图片视频等)等类型.
(3).解析数据: 一把直接从服务器获取的数据不能直接使用或持久化存储, 需要通过一定的技术手段对数据进行解析, 比如获取的是HTML, 可以用正则表达式或网页解析库进行解析, 进而获得需要的数据; 如获得的是Json字符串, 可以将字符串loads序列化; 如果获取的是二进制流, 可以写入文件存储下来.
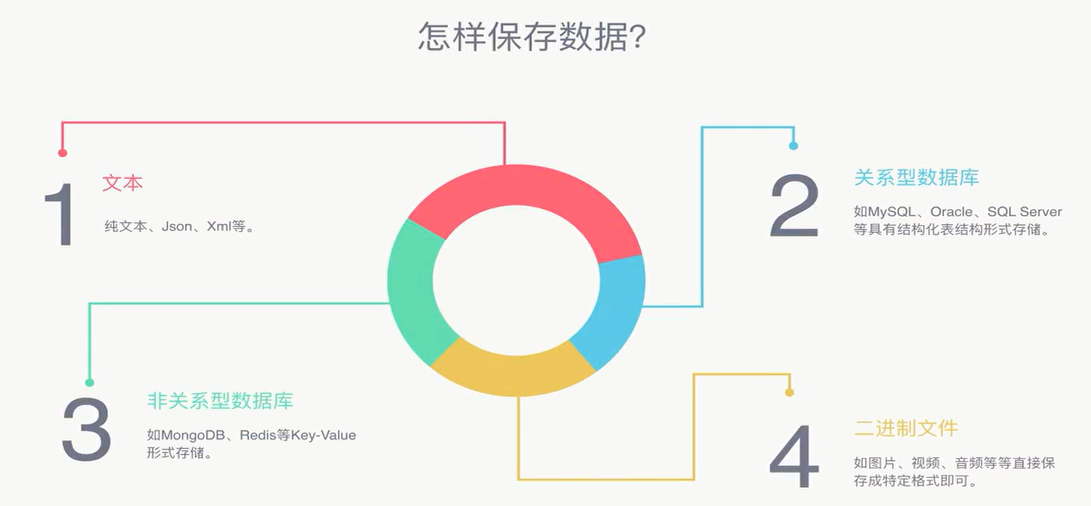
(4).数据持久化存储: 数据持久化存储就是将爬取到的并清洗过后需要入库的数据存储下来, 存储的形式多种多样, 可以保存为文本, 也可以保存至数据库, 或者保存为特定格式的文件

3.request请求
(1).请求与响应的过程:
1).浏览器发送信息给某网址所在的服务器, 这个过程就叫做HTTP Request, 即请求.
2).服务器收到浏览器发送的消息后, 能够根据浏览器发送消息的内容, 做相应处理, 把消息返回给浏览器, 这个过程叫做HTTP Response, 响应.
(2).请求方式 — get与post: 浏览器向服务器发送请求的方式有很多, 不同的方式有不同的作用. 爬虫中常用的请求有get请求和post请求.
1).get请求: get请求将参数拼接在url上发送给服务器, 服务器解析URL后作出响应,get请求提交的数据最多只有1024个字节, 而post方式没有限制
2).post请求: post请求一般将要传递给服务器的信息放置在formdata中, 服务器根据post请求方式解析数据并作出响应.
(3).URL是个什么鬼?
URL全称为统一资源定位符, 如一个网页文档, 一张图片, 一个视频都可以用url唯一来确定. 用户是通过URL来向服务器发送请求的, 服务器解析URL后返回资源给客户端, 所以不同的资源, 对应不同的URL.在爬虫中, URL是一个很重要的东东, 获取不到资源请求的URL, 就谈不上爬虫了.
(4).请求头: 请求头是一次请求的信息标识, 常用的请求头如下:
1).User-Agent:简称UA,它是一个特殊的字符串头,其携带的信息可以让服务器识别客户使用的操作系统及版本,浏览器及版本信息等.如果请求中缺少UA,可能会被服务器识别非法请求,所以一般情况下,我们每次请求都会进行UA伪装.
2).Cookies:也常用作复数形式,Cookies.它是服务器为辨别用户进行会话跟踪二存储在用户本地的数据,其功能就是维持当前的访问会话.
(5).请求体:
请求时额外携带的数据, 如表单提交时的表单数据, 当以post请求方式向服务器请求数据时, 我们一般都要构建一个请求体数据, 在request中携带这写数据向服务器发起请求, 才能正常的获取服务器的相应. 比如使用爬虫程序登陆某网站时, 我们需要构建页面需要填写的用户名, 密码, 验证码, 还有一些其他的信息等的数据提交给服务器.

4.response响应
Response相应, 我们一般比较关注三方面: 响应状态, 响应头, 响应体
1). 响应状态: 响应状态代表服务器响应的情况, 如200代表响应请求成功, 301代表重定向, 404代表向服务器请求的资源不存在, 500代表服务器端出现错误.
2).响应头: 响应头包含了一系列服务器返回给我们的信息, 如响应的资源的内容类型, 内容的长度, 服务器地址信息, 设置Cookie等等
3).响应体: 响应体是我们最关心的东东了, 因为我们请求的资源, 要爬取的数据都包含在响应体中, 如HTMLL页面, 图片视频的二进制数据等.

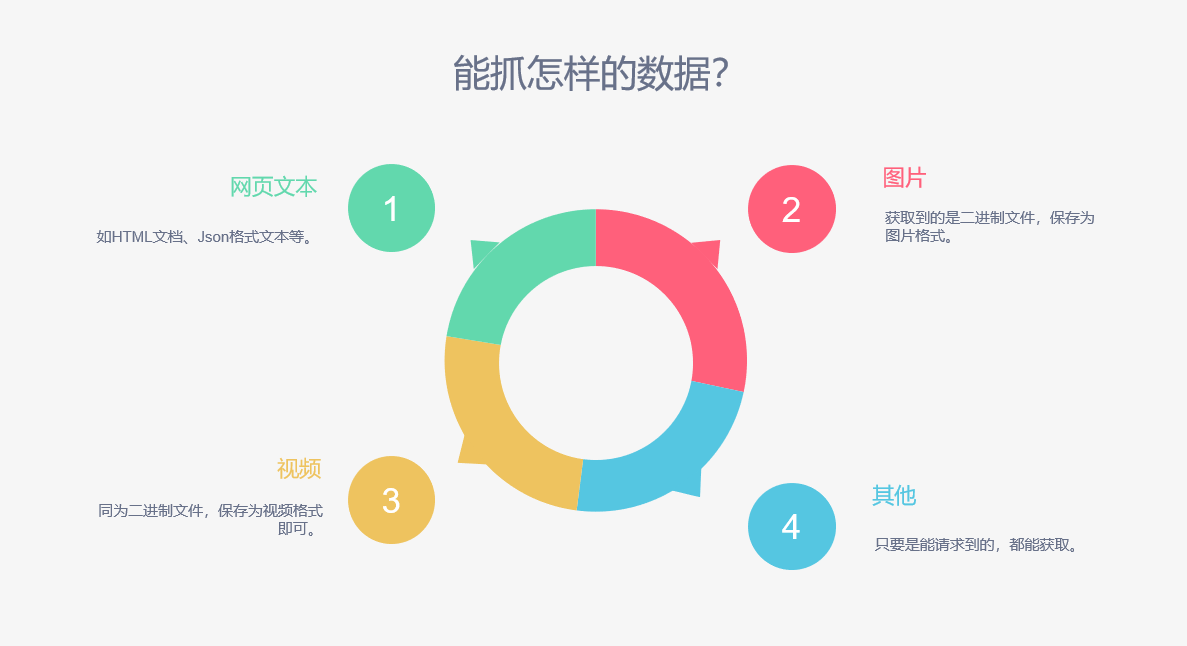
5.爬虫能够抓取怎样的数据
1).网页文本: 爬虫能够从指定的URL直接获取HTML文档, Json格式的文本数据. 针对于HTML可以选择合适的解析库进行解析, 获取页面中指定的数据; 如果是Json格式文本, 可以序列化为可操作的序列类型, 通过序列的方法操作数据.
2).图片: 网页中加载的图片都是通过指定的URL请求服务器后以二进制流的方式传送至客户端浏览器的, 通过浏览器的解析就车险处理网页中的图片了. 当我们用爬虫程序请求图片的URL时 可以从服务器获取二进制流, 打开文件, 将二进制流写进文件再保存, 图片就爬取成功了.
3).视频: 爬虫的世界里并不区分视频还是图片, 因为底层它们都是二进制流, 爬取到数据后都可以用写文件的方式持久化存储.
4).其他数据: 一般情况下, 只要是能够获取请求URL的, 并且访问该URL可以从服务器获取相应资源的都能可以进行爬取.
6.数据的解析
请求服务器获取到的数据往往不全都是我们的目标数据, 一般是包含了目标数据的大量数据, 这是我们需要从中提取出目标数据, 并对提取出的目标数据进行处理, 取出目标数据中一部分不合格的数据,才能拿到合格的目标数据. 从大量数据中提取出目标数据就是所谓的数据解析, 对目标数据进行处理就是所谓的数据清洗.
数据解析的方式方法:
1).直接处理: 如果获取到的数据比较简单, 不需要使用解析库进行解析, 可以直接处理.
2).Json解析: 如果请求到的是Json数据, 可以将Json字符串序列化后操作数据提取目标数据
3).BeautifulSoup解析库, xpath, PyQuery: 通过解析库对网页数据进行解析, 基本思路是定位目标数据所在的标签, 通过解析库提供的方法获取已定位到的标签的文本内容或属性值.
4).正则表达式: 诶呀妈呀!!! 脑瓜儿疼…谁用谁疼. 正则表达式适合处理文本型数据, 如获取的HTML页面, 可以使用正则表达式匹配文本中的目标数据, 但要求开发者能够熟练掌握正则表达式的基础和编写技巧(反正我比较菜, 不喜欢用, 解析库能解决的事情, 干嘛搞自己呢?)

7.为什么抓取到的数据与浏览器显示的不一样
这要追溯到网页数据的加载方式了, 网络上一部分网页是事先工程师已写好的HTML, 直接传输给浏览器客户端, 浏览器解析后就可以正常显示了. 但有一部分网页是工程师搭的一个骨架, 内部的内容是通过JavaScript语言动态生成的, 对于这种情况往往我们通过程序简单的请求服务器是无法获取目标数据的, 别担心有办法的, 继续向下看吧!
8.如何解决JavaScript渲染的问题
1).分析Ajax请求, 通过模拟发送Ajax请求获取动态加载数据.
2).借助selenium工具获取动态加载数据.
3).使用splash库获取
4).其他的PyV8, Ghost.py等的使用

9.数据持久化
所谓数据持久化即将爬取到的数据解析后经过清洗得到合格的数据存储起来, 数据持久化存储的方式很多, 针对不同的数据类型由不同的存储方式, 即使是相同的数据类型也可以根据不同的技术栈要求选择不同的持久化方式.如下:
1).文本形式存储: 对于纯文本, Json, xml等数据类型, 可以选择文本的形式保存, 但我不喜欢这种方式, 毕竟操作文件有点low, 读写文件的IO较高, 效率低.
2).关系型数据库: 可以选择MySQL, Oracle, SQL Server等关系型数据库存储结构化数据.
3).非关系型数据库: 常见的非关系型数据库有Redis, MongoDB等.
4).二进制文件: 对于图片, 视频, 音频等格式的文件, 因为爬取到的数据往往是二进制流, 我们可以选择将二进制流写入文件, 给文件相应的扩展名而将爬取到的数据存储下来. 其实也不限于图片, 视频, 音频等格式, 只要是二进制流都可以. 比如我爬过的一个网站, 正常下载数据是rar的压缩包, 程序中测试服务器返回的是二进制流, 所以我就将二进制流写入文件, 文件扩展名为.rar, 就批量的爬取(下载)了指定的数据.