
- 1C++设计模式-解释器模式_c++解释器
- 2关于使用Git pull出现冲突“error: Your local changes to the following files would be overwritten by merge”解决方案
- 3基于springboot的大学生志愿者活动管理系统【数据库设计、论文、毕设源码、开题报告】_志愿者管理系统数据库设计
- 4Will not attempt to authenticate using SASL (unknown error) (org
- 5三款顶级开源RAG (检索增强生成)工具:Verba、Unstructured 和 Neum
- 6Ollama+qwen2实现开源大模型本地化部署_qwen2 57b电脑配置
- 7详解如何使用VSCode搭建TypeScript环境(适合小白)_vscode typescript
- 8动态规划——经典案例分析_processing 斐波那契数列案例
- 9C语言单链表的算法之遍历节点_c语言链表如何从首节点一直遍历到第二节
- 10IDEA中SVN 的使用_idea svn插件
Java技术栈总结:数据库MySQL篇
赞
踩
一、慢查询
1、常见情形
聚合查询
多表查询
表数据量过大查询
深度分页查询
2、定位慢查询
方案一、开源工具
- 调试工具:Arthas
- 运维工具:Prometheus、Skywalking
方案二、MySQL自带慢日志
在MySQL配置文件 /etc/my.conf 中配置:
- # 开启MySQL慢日志开关
- slow_query_log=ON
- # 设置慢日志时间2秒,超过2秒的SQL语句会被认为是慢查询,记录慢查询日志
- long_query_time=2
- # 慢日志记录文件
- slow_query_log_file =/var/lib/mysql/localhost-slow.log
重启MySQL服务器,后续可在对应日志文件中查看慢日志信息。
3、慢SQL优化
- 聚合查询,考虑增加临时表
- 多表查询,优化SQL语句
- 表数据量过大,增加索引
- 深度分页查询,
其中,聚合查询、多表查询、数据量过大的情况,均可以使用SQL执行计划分析,进行优化。使用MySQL自带命令 explain 或 desc :
EXPLAIN/DESC + 原SQL语句

字段含义
- possible_key,当前SQL可能会使用到的索引;
- key,当前SQL实际命中的索引;
- key_len,索引"key"占用空间大小;
- Extra,额外的优化建议;
- Using where;Using index:使用了索引,需要的数据在索引中都能够找到,不需要回表查询。
- Using index condition:使用了索引,但是需要回表查数据。
- type,该SQL数据访问/操作的类型,性能从好到差依次为:NULL、system、const、eq_ref、ref、range、index、all。
- ALL,扫描全部数据,MySQL将遍历全表以找到匹配的行;
- index,遍历索引,索引树扫描;
- range,索引范围查找;
- ref,使用非唯一索引查找数据;
- eq_ref,类似ref,区别是使用的索引为唯一索引,对于每个索引的键值,表中只有一条记录匹配。
- const,根据主键查询;
- system,查询mysql自带的表;
Q:某条SQL查询很慢,如何分析?
A:可以使用MySQL自带分析工具EXPLAIN。
- 通过key和key_len检查是否命中了索引(索引本身存在是否有失效的情况)
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
二、MySQL存储引擎
1、分类
存储引擎是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎基于表,而非基于数据库。
| # 特性 | MyISAM | InnoDB | MEMORY |
|---|---|---|---|
| 事务 | × | ✔ | × |
| 锁机制 | 表锁 | 表锁、行锁 | 表锁 |
| 外键 | × | ✔ | × |
在mysql中提供了很多的存储引擎,比较常见有InnoDB、MyISAM、Memory
- InnoDB存储引擎是mysql5.5之后是默认的引擎,它支持事务、外键、表级锁和行级锁
- DML操作遵循ACID模型,支持事务;
- 行级锁,提高并发性能;
- 支持外键,FOREIGN KEY 约束,保证数据的完整及正确性。
- MyISAM是早期的引擎,不支持事务、只有表级锁、也没有外键,用的不多
- Memory主要把数据存储在内存,支持表级锁,没有外键和事务,用的也不多
2、体系结构

三、索引
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构(B+树),这些数据结构以某种方式指向数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
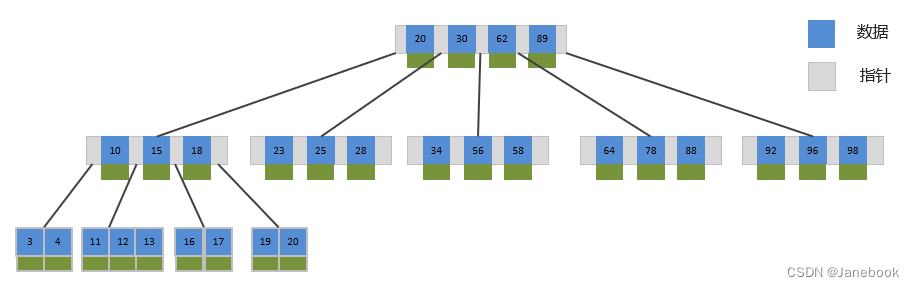
1、B树
2、B+树
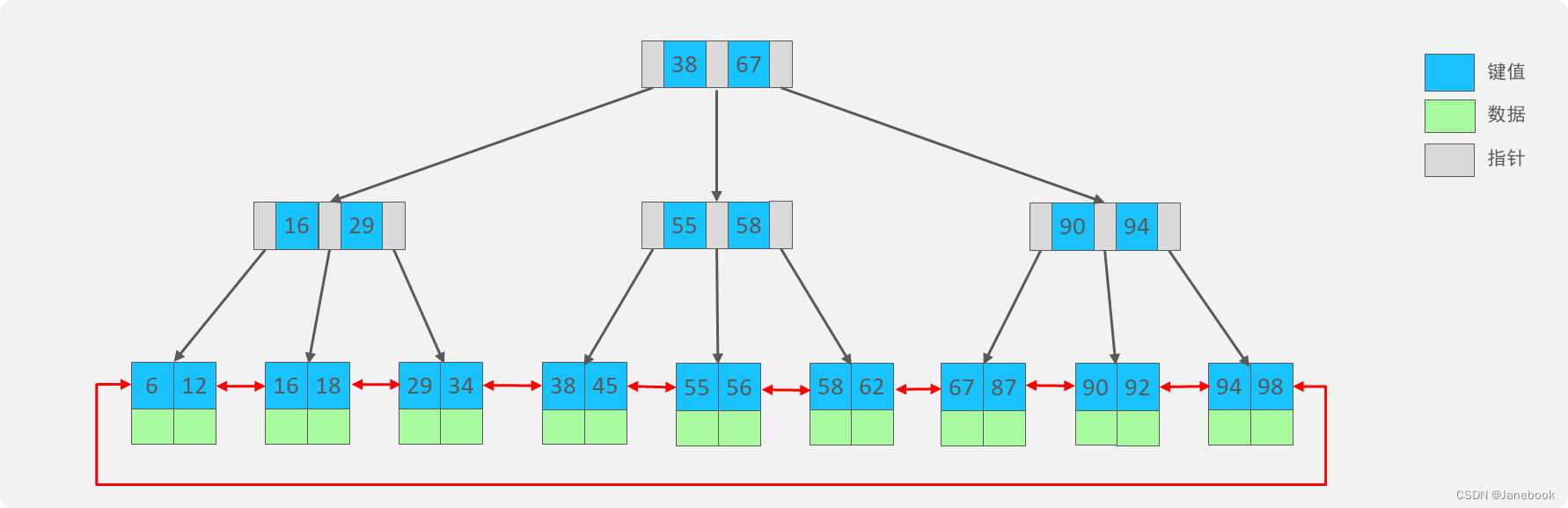
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表(叶子节点内部为单向链表)。
B树与B+树对比:
①:磁盘读写代价B+树更低;②:查询效率B+树更加稳定;③:B+树便于扫库和区间查询
3、聚簇索引与非聚簇索引
聚簇索引,数据存储和索引在一块,索引结构的叶子节点保存了行数据。聚簇索引在每张表中都有且仅有一个。
非聚簇索引(二级索引),将数据与索引分开存储,叶子节点关联的内容为对应的主键。一张表可以有多个二级索引。
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一索引(UNIQUE)作为聚集索引。
- 如果表没有主键,且没有合适的唯一索引,则 InnoDB 会自动生成一个rowid作为隐藏的聚集索引。
回表查询:通过二级索引找到对应的主键,然后根据主键值通过聚簇索引找到对应的行数据,这个查找的过程称为回表。
4、覆盖索引
覆盖索引:指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
- 使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
- 如果返回的列中没有创建索引,可能会触发回表查询,尽量避免使用 select *。
# 超大分页问题处理,
数据量较大的情况,使用 limit 分页查询,查询越靠后,查询效率越低。
优化思路:一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过 覆盖索引 + 子查询 的形式进行优化。
- select * from tb_sku t,
- (select id from tb_sku order by id limit 90000,10) a
- where t.id = a.id;
Q:超大分页怎么处理?
A:超大分页一般在数据量较大时,使用了limit分页查询,且需要对数据进行排序。这种情况下查询的效率就会比较低,可以采用覆盖索引和子查询解决。
首先,分页查询数据的主键id字段,然后用子查询来过滤,只需要查询这个id列表中的数据即可。因为查询id的时候走的是覆盖索引,所以效率会提升。
5、创建索引的原则
依次考虑:主键索引、唯一索引、复合索引(根据业务情况创建);
原则:
- 数据量较大,且查询比较频繁的表创建索引;(例,>10万条)
- 针对查询条件 where 、排序 sort by 、分组 group by 等操作的字段创建索引;
- 选择区分度高的字段作为索引,优先创建唯一索引,检索效率高;
- 字符串类型的字段,如果长度较长,可以考虑创建前缀索引;(取字段的前一部分)
- 涉及多字段作为查询条件的情况,尽量使用联合索引,减少单列索引。联合索引很多时候可以覆盖索引,可以避免回表,节省存储空间;
- 需要控制索引的数量,索引数量越多,维护索引的代价也越大,同时影响增删改的效率;
- 如果某个字段不能存储NULL值,建表语句对应该字段应当使用 NOT NULL 约束。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
6、索引失效的情况
(1)判断索引是否失效
explain 命令,例:
假设我们在student表中有一个联合索引“idx_age_name_grade (name,age, grade)”
- explain select * from student where name = "zhangsan" and age = 20 and grade = 3;
- explain select * from student where name = "zhangsan" grade = 3;
- explain select * from student where age = 20 and grade = 3;
可以通过对比上述语句的输出内容,key 、 key_len ...,查看索引的使用情况。
(2)失效的场景
- 使用聚合索引,违反最前左缀原则(如,上述student表,查询条件无name且包括age或grade的情况);
- 联合索引,查询语句使用了范围查询,右边的列索引不会生效(如,select * from student where name = "zhangsan" and age > 20 and grade = 3;范围查询“age > 20” 右侧的 grade 字段索引不生效 );
- 在索引列上进行了运算,索引会失效;
- 字符串对应的字段查询语句不加引号,出现类型转换,引起失效;
- like查询,以 % 开头的模糊查询(如果仅仅是以 % 结尾的 like 查询,索引不会失效);
- or 前后没有同时使用索引;
- 索引字段使用了 IS NULL 、IS NOT NULL、not、!= 等;
- mysql评估全表扫描比使用索引查询快
注意:联合索引的情况,如果只是查询条件里的查询顺序和索引定义的顺序不同,不影响走索引。索引优化器会对查询条件进行优化,即进行重新排序。
7、SQL优化总述
涉及方面:
- 表的设计优化
- 选用合适的字段类型
- SQL语句优化 && 索引优化:关联 “5、索引创建原则”、“6、索引失效情况”
- 尽量避免使用 select *,防回表
- Join优化:能用innerjoin 就不用left join right join,如必须使用 一定要以小表为驱动。内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join 或 right join,不会重新调整顺序。
- 主从复制、读写分离
- 分库分表
(1)主从复制
主从复制的核心为二级制日志。二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
DDL,数据定义语言,表创建语句 create table ...
DML,数据操作语言,insert、update、delete

主从复制流程:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中;
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log;
- 从库slave重做中继日志中的事件(读取replay log 文件日志,执行语句),将改变反映它自己的数据。
(2)分库分表
【分库分表的时机】:
- 项目业务数据逐渐增多,或业务发展比较迅速;例:单表数据量达到了1000万,或20GB。
- 优化已解决不了性能问题(主从读写分离、查询索引…);
- IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多);
1)拆分策略
垂直拆分:垂直分库,垂直分表;
水平拆分:水平分库,水平分表。
【垂直分库】
以表为依据,根据业务将表拆分到不同的库中。
例如,将用户信息相关的表和订单相关的表分别放到不同的库中。
特点:
- 按业务对数据分级管理、维护、监控、扩展;
- 在高并发下,提高磁盘IO和数据量连接数。
【垂直分表】
以字段为依据,根据字段属性将不同字段拆分到不同表中。
例如,将商品的id、名称等放到一张表;详细描述信息等放到另外一张表。用户查看详情时,对应点击页面详情按钮,再查询详细描述等信息。
特点:
- 冷热数据分离;
- 减少IO过渡争抢,两表互不影响。
【水平分库】
将一个库的数据拆分到多个库中。
特点:
- 解决了单库大数量,高并发的性能瓶颈问题;
- 提高了系统的稳定性和可用性。

路由规则:
- 根据id节点取模
- 按id也就是范围路由,节点1(1-100万),节点2(100万-200万)
- …
【水平分表】
将一个表的数据拆分到多个表中(可以在同一个库内)。
特点:
- 优化单一表数据量过大而产生的性能问题;
- 避免IO争抢并减少锁表的几率。

2)水平拆分问题与策略
水平分库之后的问题:
- 分布式事务一致性问题
- 跨节点关联查询
- 跨节点分页、排序函数
- 主键避重(每个表id自增)

分库分表中间件:
- sharding-sphere
- mycat
Q:项目用过分库分表吗
A:
业务介绍:
1,数据量较大业务(请求数多或业务累积大);
2,达到了什么样的量级(单表1000万或超过20GB)。
拆分策略介绍:
1,水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题;
2,水平分表,解决单表存储和性能的问题;
3,垂直分库,根据业务进行拆分,高并发下提高磁盘IO和网络连接数;
4,垂直分表,冷热数据分离,多表互不影响。
注:水平分库 及 水平分表,涉及中间件 sharding-sphere、mycat
四、事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
1、事务的特性ACID
- 原子性 Automaticity:事务是不可分割的工作单位,要么全部成功,要么全部失败;
- 一致性 Consistency:事务将数据库从一种状态转变为下一种一致的状态;
- 隔离性 Isolation:不受并发操作的影响,事务提交前对其他事务不可见;
- 持久性 Durability:事务一旦提交,其结果就是永久性的。即使发生宕机等故障,数据库也能将数据恢复。
例:A向B操作转账100元,
原子性:A扣除100,B增加100,要么都成功要么都失败;
一致性:数据在事务执行前后一致(转账前后),A扣除了100,B必须增加100;
隔离性:A向B转账,不受其他事务的影响;
持久性:事务提价后,需要将数据持久化(落盘操作)。
2、并发问题
脏读、不可重复读、幻读
- 脏读:一个事务读取了另一个事务还没有提交的内容;
- 不可重复读:一个事务,前后读取同一条记录,获取到的数据内容不同(原因是查询的过程中其他事务做了更新操作);
- 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”(原因是查询过程中其他事务做了添加操作)。
3、事务隔离级别
解决并发事务问题的方案:对事务进行隔离。
(1)四种隔离级别
1)READ UNCOMMITTED(读未提交)
事务中最低的级别,该级别下的事务可以读取到另一个事务中未提交的数据,也被称为脏读( Dirty Read)。
2)READ COMMITTED(读提交)
大多数数据库管理系统的默认隔离级别,例如Oracle。
该级别下,事务只能读其他事务已经提交的内容,可以避免脏读,但不能避免重复读、幻读的情况。
3)REPEATABLE READ(可重复读)
MySQL默认的事务隔离级别,可以避免脏读、不可重复读的问题,确保同一个事务的多个实例在开发并发读取数据时,会看到同样的数据行。该级别在理论上会出现幻读的情况,但MySQL的存储引擎通过多版本并发控制(MVCC)解决了该问题。
4)SERIALIZABLE(串行化)
事务的最高隔离级别,强制对事务进行排序,使事务之间不会发生冲突,从而解决脏读、幻读、重复读的问题。事务串行执行,效率较低,一般不采用。
(2)各隔离级别可能出现的问题
事务的隔离级别越高,数据约安全,但同时性能也越低。
| # 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | ✔ | ✔ | ✔ |
| 读已提交 | / | ✔ | ✔ |
| 可重复读 | / | / | ✔ |
| 串行化 | / | / | / |
4、undo log && redo log

数据写入过程:
- 缓冲池(buffer pool): 主内存中的一个区域,里面可以缓存磁盘上经常操作的数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度;
- 数据页(page): InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。页中存储的是行数据。
(1)redo log
redo log 包括两个部分,一是内存中的重做日志缓冲(redo log buffer),这部分是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘异常时,做数据恢复使用。从而实现数据的持久性(Durability)。

(2)undo log
回滚日志,记录的内容为数据被修改前的信息(所需的操作),作用包括:提供回滚和MCC的功能支持。redo log 记录的为物理日志;undo log 记录的为逻辑日志,即,用来回滚记录到某个版本的日志。
例如,对某条数据执行了delete操作,undo log中就会记录恢复删除操作前的数据状态相对应的insert语句。
undo log 可以实现事务的一致性和原子性。
在 insert、update、delete 的时候会产生数据回滚的日志,
- insert 操作,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除;
- update、delete 的时候,产生的undo log日志不仅在回滚时需要,mvcc版本访问也需要,不会立即被删除。
(3)区别
- redo log:记录的是数据页的物理变化,服务宕机可用来同步数据。
- undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据。
- redo log 保证了事务的持久性,undo log保证了事务的原子性和一致性。
事务隔离性的保证:
排他锁 + MVCC(多版本并发控制)。
排他锁:如果一个事务获取了一个数据行的排他锁,其他事务就不能获取该行的其他锁(包括排他锁)。
5、MVCC
MVCC多版本并发控制(Multi-Version Concurrency Control)
维护一个数据的多个版本,使得读写操作没有冲突。MVCC的具体实现,主要依赖于数据库记录中的隐式字段、undo log日志、readView。
(1)数据库表隐藏字段
- DB_TRX_ID,最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID;
- DB_ROLL_PTR,回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本;
- DB_ROW_ID,隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。
(2)undo log 版本链
示例假定,事务2 的ID为2,记录的undo log 日志版本号为 "0x00001";事务3、事务4、事务5 类似。开启事务,分别执行不同的操作,表格水平位置前后,代表执行时间的前后关系。

- 存储老版本数据;
- 多个版本并行操作某一行记录时,进行记录不同事务修改的版本,通过回滚指针roll_pointer形成一个链表。
(3)ReadView
ReadView(读视图)是 快照读 SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
当前读:读取的是记录的最新版本,读取时需要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。例如:select ... lock in share mode(共享锁),select ... for update、update、insert、delete(排他锁)都属于当前读。
快照读:
简单的select(不加锁)操作就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
- 读已提交 Read Committed:每次select,都生成一个快照读。
- 可重复读 Repeatable Read(InnoDB默认级别):开启事务后的第一个select语句处是快照读的地方。仅在事务第一次执行快照读时生成ReadView,后续复用该ReadView。
【ReadView】的4个关键属性:
- m_ids:在生成 ReadView 时,系统中活跃的事务id集合;
- min_trx_id:在生成 ReadView 时,系统中活跃的事务中的最小事务id,即 m_ids 中的最小值;
- max_trx_id:在生成 ReadView 时,系统分配给下一个事务的id值,即全局事务id,该id不是 m_ids 中的最大值;
- creator_trx_id:生成当前事务的事务id,即生成该 ReadView 的事务的事务id。
【版本链数据访问规则】:
trx_id,代表待判断是否可访问的事务的事务ID。
①. trx_id == creator_trx_id ? 可以访问该版本。对应为当前事务。
②. trx_id < min_trx_id ? 可以访问该版本。说明该事务在当前事务开启前已提交。
③. trx_id > max_trx_id ? 不可以访问该版本。说明该事务在当前事务【ReadView】生成后才开启。
④. min_trx_id <= trx_id <= max_trx_id ? 如果trx_id不在m_ids中,说明该事务已提交,是可以访问该版本的。否则,不可访问。
具体实现:Undo 版本链 + ReadView 机制
(1)当前事务只读的情况:
查询操作获取的为 undo 版本链上的一个快照版本,称为“快照读”或“一致性非锁定读”。
在可重复读(Repeatable Read)隔离级别下,只在第一次查询时生成了一个 ReadView,之后的查询都复用这个 ReadView。别的事务未提交、已提交、新插入的修改都读取不到,从而解决了脏读、不可重复读、幻读的可能问题。
(2)当前事务涉及修改的情况:
执行“Insert、Delete、Update”操作,能够读取到别的事务已经提交的修改,为“当前读”。
参考内容:

