
- 1DockerUI如何部署结合内网穿透实现公网环境管理本地docker容器_docker ui
- 2Machine Learning Engineering Case Studies with Python notebook
- 3无监督学习的主流算法及其优缺点
- 42024年鸿蒙最全鸿蒙HarmonyOS应用开发-自定义实现验证码框_鸿蒙开发字母验证码,2024年最新到了三面试成功率高吗_鸿蒙textinput隐藏光标
- 5数据结构——树(二叉树)的基础知识 & 堆 & 堆排序 & 时间复杂度讲解 & topk问题(详解)_二叉堆新增节点的时间复杂度
- 6国内大语言模型的相对比较:ChatGLM2-6B、BAICHUAN2-7B、通义千问-6B、ChatGPT3.5_atom-7b-chat和chatglm哪个性能好一点
- 7聆思CSK6大模型开发板视觉识别类开源SDK介绍_csk6 目标检测
- 8android自定义view_android 自定义view
- 9ad电阻原理图_105篇DIY开源资料汇总分享:原理图/PCB图/源码/BOM表/相关资料文档等...
- 10粒子群算法(Python代码实例)_假设有一个粒子群算法应用于解决优化问题,初始时有20个粒子,搜索空间是二维平面。
大数据必会面试题_大数据岗一般的面试题
赞
踩
目录
9. SecondaryNameNode是如何辅助namenode管理元数据的?
11. count(1), count(*), count(列)的区别是什么?
13. 数据仓库 和 数据库之间的区别是什么? 也可能会问: OLAP 和 OLTP之间的区别是什么?
20. cluster by, distribute by, sort by, order by这四组关键字的区别是什么?
21. full outer join 和 union all的区别?
1. 你用的IDE是什么?
核心: 版本, Integrated Development Environment(集成开发环境)
hadoop3.x、Java1.8、datagrip2023、idea2023、pycharm2023、远程连接工具
2. desc的作用是什么?
降序, 查看表结构.
3. having 和 where的区别?
1. 功能不同, 组前筛, 组后筛.
2. having后边是可以跟聚合函数.
4. 请简述你对大数据的特点的理解?
5V, 大多值快信.
大 多 值 快 信
大:数量体积大 目前 5EB 企业都达到E级了
多:种类多,结构化,半结构化,非结构化数据(从左到右,越来越乱)
来源杂。值: 大海捞针。选出优秀价值的数据。(密度低->密度高,价值低->价值高)
快:数据增长快,处理速度快。
离线分析 + 在线分析(实时分析)
信: 数据的准确性 和 可信赖度,数据质量可靠。
5. 请简述你对分布式 和 集群的理解.
分布式:
把一个大业务拆分成多个子业务,每个子业务都是一套独立的系统,子业务之间相互协作最终完成整体的大业务。
集群:把处理同一个业务的系统部署多个节点 。
把一套系统拆分成不同的子系统部署在不同服务器上,这叫分布式。
把多个相同的系统部署在不同的服务器上,这叫集群。部署在不同服务器上的相同系统必然要做“负载均衡”。
6. 请简述你对HDFS架构的理解.
NameNode,SecondaryNameNode,datanode
namenode:1.管理整个HDFS集群 2.维护和管理元数据
SecondaryNameNode:辅助节点 1.辅助namenode管理元数据
datanode:从节点 1.维护和管理源文件 2.负责数据的读写操作 3.定时向namenode报活
7.高可用模式:
1.zookeeper的作用和功能
Zookeeper 是一个开源的分布式协调服务框架,主要用于解决分布式应用程序中的一致性、可靠性和可伸缩性问题。它提供了以下几个主要的作用和功能:
配置管理:Zookeeper 可以用于存储和管理分布式应用程序的配置信息,如服务器地址、端口号、配置参数等。通过 Zookeeper,应用程序可以在启动时从 Zookeeper 获取配置信息,实现动态配置。
命名服务:Zookeeper 提供了一个全局的命名空间,应用程序可以通过在 Zookeeper 中创建节点来表示唯一的名称或标识符。其他应用程序可以通过查询 Zookeeper 来获取这些名称或标识符的对应信息。
分布式锁:Zookeeper 可以用于实现分布式锁。应用程序可以在 Zookeeper 中创建临时节点来表示锁,当一个进程获取到锁时,其他进程将无法获取相同的锁。
服务注册与发现:Zookeeper 可以用于服务注册与发现。服务提供者可以在 Zookeeper 中注册自己的服务信息,而服务消费者可以通过查询 Zookeeper 来获取可用的服务列表。
数据同步:Zookeeper 可以用于实现数据的分布式同步。应用程序可以将数据存储在 Zookeeper 中,并通过监听节点的变化来实现数据的同步。
领导者选举:Zookeeper 可以用于实现领导者选举。在分布式系统中,可以通过 Zookeeper 选举出一个领导者节点,其他节点则作为追随者。
集群管理:Zookeeper 可以用于管理分布式集群。它可以检测集群中节点的状态,并提供心跳检测、节点加入和退出等功能
2.zookeeper的集群角色 和作用
ZK的架构介绍:
Leader: 主节点
1. 管理整个ZK集群, 负责: 全局数据一致性.
2. 负责处理 数据事务操作(增, 删, 改)
3. 负责转发 数据非事务操作(查) 给 Follower
Follower:
1. 实时和Leader同步, 保证: 全局数据一致性.
2. 负责处理 数据非事务操作(查)
3. 负责转发 数据事务操作(增, 删, 改) 给 Leader
4. 有选举权.
ObServer:
除了没有选举权, 剩下的和 Follower一样. 大公司, 大规模集群, 才会考虑部署ObServer.
3.zookeeper的集群选举机制
原则:
过半原则, 某个机器获取的票数超过集群总数的一半, 它就是Leader, 剩下的是Follower.
选举机制的方式:
新集群: 参考myid值, 优先投票给myid值大的机器.
旧集群: 参考(节点)最后一次更新的事务id, 优先投票给事务id大的节点(机器), 如果事务id一致, 则参考 myid值, 投票给myid值大的机器.
4.zookeeper的watch机制 (监听机制)
1. 先注册, 后监听.
2. 当事件触发后, 会将触发结果告知 监听者.
3. 异步发送监听结果的.
4. 监听是一次性触发, 之后在触发响应的内容, 也不会给 监听者发送消息了.问题: watch监听机制, 有什么用?
答案: 它(watch监听机制) 结合临时节点一起用, 可以实现: 主备切换.
5.NameNode主备切换流程

高可用集群:没有secondname ,两个namenode主备模式宕机一个就切换另一。

8. 请简述你对Yarn架构的理解.
ResourceManager, nodemanager

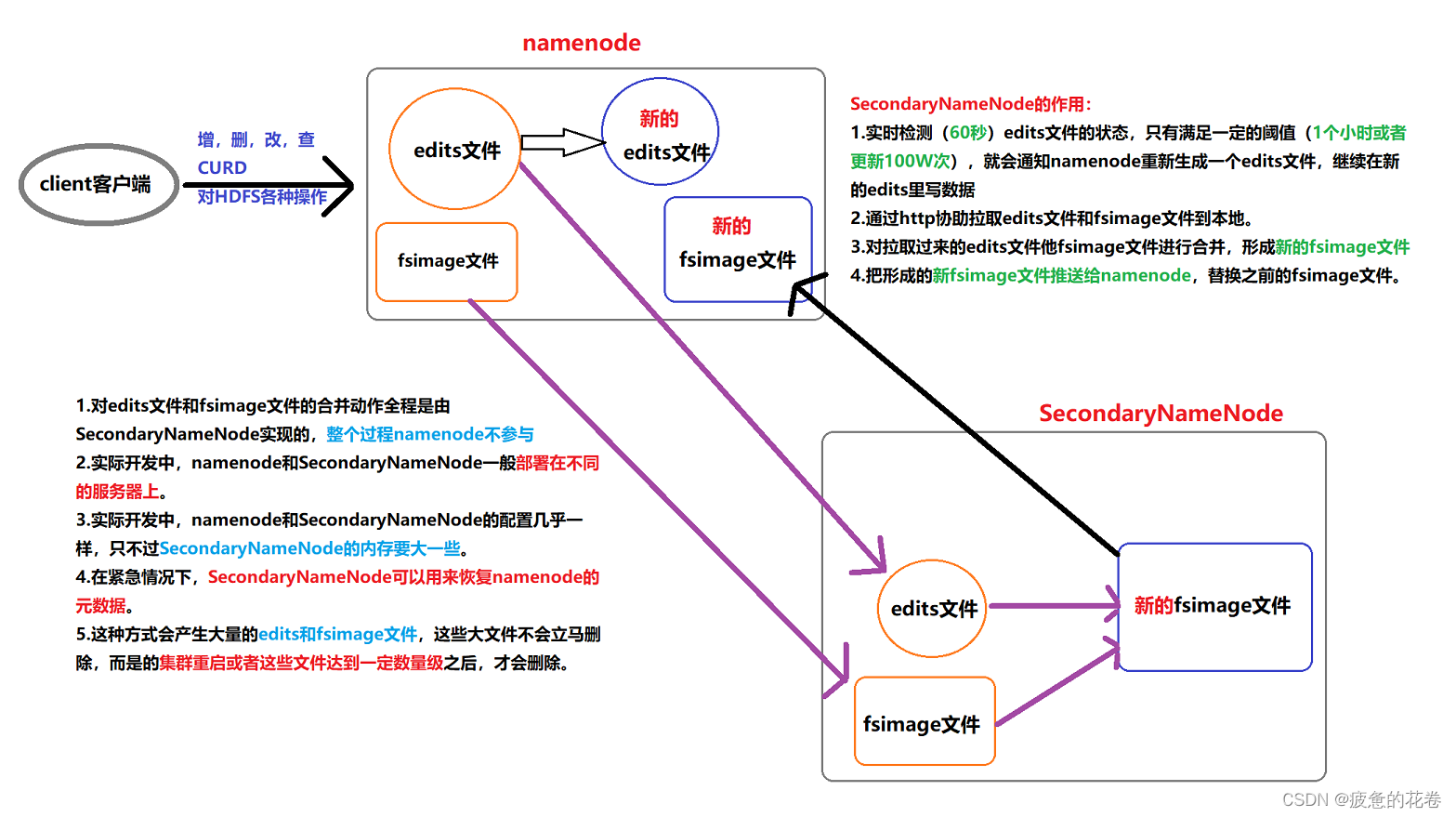
9. SecondaryNameNode是如何辅助namenode管理元数据的?
1. SecondaryNameNode会间隔60s(秒), 询问一次namenode, edits文件是否满足了阈值(1个小时, 或者100W次)
2. 如果满足条件, 就通知namenode创建新的Edits文件, 继续往里写入元数据信息.
3. 根据http协议, 从namenode上把要合并的edits文件 和 fsimage文件拉取到本地进行合并.
4. 将合并后的新的FSImage文件推送给namenode, 用来替换之前旧的FsImage文件.
细节: 旧的FSImage文件并不会被立即删除, 而是达到一定的阈值后, 才会被删除.
5. 对于Edits文件和FSImage文件的合并操作, 是由SecondaryNameNode独立完成的, 全程namenode不参与.
6. 实际开发中, namenode 和 SecondaryNameNode会被部署到不同的服务器上, 配置几乎一致, 只不过SecondaryNameNode的内存要稍大一些.
7. 在紧急情况下, SecondaryNameNode可以用来恢复namenode的元数据.
 10. MR计算圆周率的原理是什么?
10. MR计算圆周率的原理是什么?
蒙特卡洛算法.

11. count(1), count(*), count(列)的区别是什么?
1. 是否统计null值.
count(*), count(1): 统计null值.
count(列): 只统计该列的非空值.2. 效率的区别.
上述的几种写法, 效率从高到低分别是: count(主键列) > count(1) > count(普通列) > count(*)
12. 请简述你对Hive架构的理解.
Hive的客户端:命令行接口、支持的远程服务、WebUI接口
SQL解析器:检查SQL语法,把HiveSQL转换为MR任务,优化MR任务步骤,执行MR任务
元数据管理服务:负责存储Hive元数据

13. 数据仓库 和 数据库之间的区别是什么? 也可能会问: OLAP 和 OLTP之间的区别是什么?
-- 因为: Hive是数仓开发工具.
-- 面向**, 处理**数据, 进行**操作, 数据量**, 时效性事务性***...
数据仓库是面向主题设计的,而数据库是面向事务设计的。 数据仓库一般存储历史数据,而数据库一般存储在线交易数据。 数据仓库主要用于支持企业的决策分析和业务统计等方面,而数据库主要用于支撑业务系统的日常操作和数据增删改查等方面。
14. 请简述你对数仓分层的理解.
最终目的: 为了更好的分析数据.
你可以说经典的三层: ODS, DW, DA.. 但是建议你讲: 你项目的分层.
15. 请简述数仓的特点?
1. 面向主题.
2. 集成性.
3. 非易失性.
4. 时变性.
16. ETL 和 ELT的区别是什么?
先存后处理, 还是先处理后存的问题.
抽取(extract)、转换(transform)、加载(load)
17. 分区表和分桶表的区别是什么?
不同点:
1. 作用不同.
分区 = 分文件夹.
分桶 = 分文件.
2. 字段要求不同.
分区字段必须是表中没有的字段.
分桶字段必须是表中已有的字段.
3. 本质不同.
分区 = 避免全表扫描, 降低扫描次数, 提高查询效率. 分文件夹也便于维护管理.
分桶 = 减少join次数, 提高查询效率. 另一个角度是: 方便我们进行数据采样.
相同点:
殊途同归, 最终目的都是为了提高 查询效率.
18. 内部表和外部表的区别是什么?
1. 建表格式不同.
2. 删表时, 是否会同步删除源文件.
19. 分桶表默认的分桶规则是什么?
-- 哈希取模分桶法, 即: 先计算分桶字段的哈希值, 然后和桶的个数取余即可, 余数为几, 就进哪个桶.
-- select abs(hash('分桶字段值')) % 桶的个数; -- 1
20. cluster by, distribute by, sort by, order by这四组关键字的区别是什么?
用select查询是逻辑上分桶
cluster by 分桶字段 asc|desc :同一个字段又分桶又排序,桶内排序
distributed by 分桶字段 sort by 排序字段 :可以做到不同字段分桶排序,桶内排序
order by 整个查询结果进行全局排序
21. full outer join 和 union all的区别?
列合并 和 行合并 的区别?
- union distinct --distinct可以省略,纵向合并,并去重
- union all --合并 不去重
- 用法
- select * from student
- union all
- select * from student_s;
- full outer join --满外连接 outer可以省略 查询结果为:左表全集+右表全集+两表交际
- 用法
- select * from employee e1 full outer join employee_address e2 on e1.id=e2.id;
22. 四舍五入的原理是什么?
floor(x+0.5)
23. 请手写一个Hive行列转换的代码.
行转列: concat(), concat_ws() 拼接函数 + collect_list(), collect_set() 采集函数
列转行: explode(爆炸函数) + lateral view(侧视图)
- 行转列
- select col1,col2,
- concat_ws('-',collect_list(cast(col3 as string))) as col3,
- concat_ws('-',collect_set(cast(col3 as string))) as col4,
- from row2col2 group by col1,col2;
- 列转行
- select a.team_name,b.champion_year from
- nba a
- lateral view explode(champion_year) b as champion_year;
24. 行存储 和 列存储的区别?
行存储:
优点: select * 效率高.
缺点: select 列 效率低, 每列数据类型不一致, 密集度较低, 占用资源较多(CPU, 磁盘, 内存)
列存储:
优点: select 列 效率高, 每列数据类型一致, 密集度较高, 占用资源较少(CPU, 磁盘, 内存)
缺点: select * 效率低.
结论:
以后建表, 不知道具体如何选择的时候, 推荐: orc(列存储) + snappy(压缩协议)
25. 请简述你对Hive调优的理解?
存储方式(行, 列)
压缩协议(snappy, 压缩比, 解压速度, 压缩速度)
join优化(小表 join 大表, 大表 join 大表)???
groupby数据倾斜问题 => 开启负载均衡.
26. namenode是如何管理元数据的?
1. namenode是通过一批Edits(小) 和 1个FSImage(大)两类文件来维护和管理元数据的.
2. Edits文件相对较小, 操作起来速度相对较快, 它只记录HDFS最近一段状态的元数据信息.
阈值: 1个小时 或者 100W次
3. FSImage文件相对较大, 操作起来速度相对较慢, 它记录的是HDFS集群除最近状态外, 其它所有的元数据信息.
4. HDFS集群启动的时候, 会自动加载FSImage文件 和 最新的Edits文件进内存, 用于记录元数据.
整个过程称为HDFS的自检动作, 此状态下, HDFS集群会强制进入到安全模式, 只能读, 不能写.
5. 我们HDFS集群的Edits文件和FSImage文件存储在: /export/data/hadoop/dfs/name/current

27. HDFS的读数据流程.
1. Client(客户端)请求namenode, 读取文件.
2. namenode校验该客户端是否有读权限, 及该文件是否存在, 校验成功后, 会返回给客户端该文件的块信息.
例如:
block1: node1, node2, node5
block2: node3, node6, node8
block3: node2, node5, node6 这些地址都是鲜活的.
......
3. Client(客户端)会连接上述的机器(节点), 并行的从中读取块的数据.
4. Client(客户端)读取完毕后, 会循环namenode获取剩下所有的(或者部分的块信息), 并行读取, 直至所有数据读取完毕.
5. Client(客户端)根据Block块编号, 把多个Block块数据合并成最终文件即可.

28. HDFS的写数据流程.
1. Client(客户端)请求namenode, 上传文件.
2. namenode接收到客户端请求后, 会校验权限, 并告知客户端是否可以上传.
校验: 客户端是否有写的权限, 及文件是否存在.
3. 如果可以上传, 客户端会按照128MB(默认)对文件进行切块.
4. Client(客户端)再次请求namenode, 第1个Block块的上传位置.
5. namenode会根据副本机制, 负载均衡, 机架感知原理及网络拓扑图, 返回给客户端存储该Block块的DataNode列表.
例如: node1, node2, node3
6. Client(客户端)会先连接就近的datanode机器, 然后依次和其他的datanode进行连接, 形成: 传输管道(Pipeline)
7. 采用数据报包(DataPacket)的形式传输数据, 每个包的大小不超过: 64KB, 并建立: 反向应答机制(ACK机制)
8. 具体的上传动作: node1 -> node2 -> node3, ACK反向应答机制: node3 => node2 => node1
9. 重复上述的步骤, 直至第1个Block块上传完毕.
10. 返回第4步, 客户端(Client)重新请求第2个Block的上传位置, 重复上述动作, 直至所有的Block块传输完毕.
至此, HDFS写数据流程结束.
核心词: 请求, 校验权限, 切块, Pipeline(传输管道), ACK反向应答机制(ACK确认机制), 数据报包(64KB), 重复至完成.

29.HDFS的三大机制及副本存储
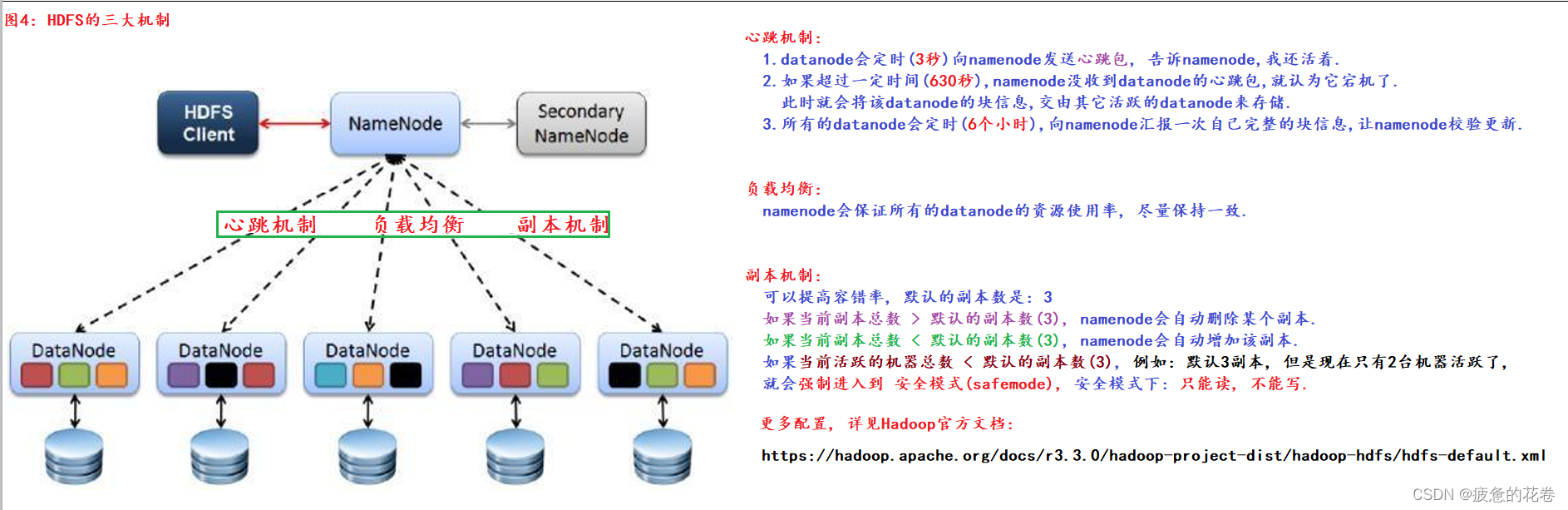
三大机制:
副本机制: 默认是3, 可以提高容错率, 但是磁盘的利用率降低.
负载均衡: namenode尽量保证多台datanode资源使用率一致.
心跳机制: 3秒, 630秒, 6个小时.
副本如何存储:
根据副本机制, 负载均衡, 机架感知原理, 网络拓扑图(寻找最近机架)进行计算, 并存储, 结论如下:
第1副本: 优先本机, 否则就近随机.
第2副本: 第1副本所在机架, 就近的某个机架的随机的服务器上.
第3副本: 和第2副本同一机架的不同服务器上.
如果不满足, 则: 随机存储.
30.简述MR的执行流程
核心词: 切片, MapTask(分), 环形缓冲区(100MB, 0.8), ReduceTask(合), 结果文件.
1. MR任务分为MapTask任务 和 ReduceTask任务两部分, 其中: MapTask任务负责: 分,
ReduceTask任务负责: 合.
一、Map阶段
Map负责分
1-1 MapTask阶段
1个切片(默认128MB) = 1个MapTask任务 = 1个分好区, 排好序, 规好约的磁盘文件.
1个分区 = 1个ReduceTask任务 = 1个结果文件.
2. 先切片, 每个切片对应1个MapTask任务, 任务内部会逐行读取数据, 交由MapTask任务来处理.(MapTask中的Mapper会将K1,V1变成K2,V2,然后进入shuffle阶段(Map段的shuffle))
1-2 Map端Shuffle
3. MapTask对数据进行分区,排序,规约处理后, 会将数据放到1个 环形缓冲区中(默认大小: 100MB, 溢写比: 0.8), 达到80MB就会触发溢写线程.
4. 溢写线程会将环形缓冲区中的结果写到磁盘的小文件中, 当MapTask任务结束的时候, 会对所有的小文件(10个/次)合并, 形成1个大的磁盘文件.
1个切片(默认128MB) = 1个MapTask任务 = 1个分好区, 排好序, 规好约的磁盘文件.二、Reduce阶段
Reduce负责合。
2-1 分组(Reduce端Shuffle)
5. ReduceTask任务会开启拷贝线程, 从上述的各个结果文件中, 拉取属于自己分区的数据, 进行: 分组, 统计, 聚合.(会根据归并排序将相同Key的value放入同一组,生成K2[V2])
2-2 ReduceTask
6. ReduceTask将处理后的结果, 写到 结果文件中.
1个分区 = 1个ReduceTask任务 = 1个结果文件.(会将生成好的K2[V2]根据业务需求变成K3,V3。K3,V3会输出到结果文件(有可能是空文件)。生成文件后,整个MapReuce执行过程就结束了。)


31.简述Yarn调度job流程
Yarn调度job流程? RM: ResourceManager(主节点), NM: nodemanager(从节点)
答案:
1. 客户端提交 计算任务给Yarn(ResourceManager: 主节点).
2. RM接收到客户端请求后, 会根据负载均衡等找一台相对空闲的机器(NM), 创建APPMaster进程, 负责该计算任务的监控和执行.
1个计算任务 = 1个AppMaster进程.
3. AppMaster创建成功后, 要和RM建立心跳机制, 并通过心跳包的方式, 从RM中获取该计算任务的相关信息.
4. APPMaster找RM申请执行该计算任务所需的资源, RM会找一些NM创建Container资源容器, 来"占用"该计算任务所需的资源.
5. APPMaster找到Container资源容器所在的NM(从节点).
6. 通过NM, APPMaster建立了和Container资源容器的连接.
7. 具体的计算过程, APPMaster会实时监控计算任务的执行情况, 并及时调度(如资源不够, 立马像RM申请).
8. 计算任务执行结束后, APPMaster将执行结果发送给RM, 并启动自毁, 告知Yarn(RM), 可以回收该任务所占用的资源了(Container资源容器).问题4: Yarn是1个统一的任务接收 `和 资源调度器, 资源就是: CPU, 内存等, 调度就是: 如何分配资源(调度算法, 策略), 那如何理解: 统一呢?
答案:
Yarn是负责任务接收 和 资源调度的, 至于是什么计算任务, Yarn根本不关心, 只要符合Yarn的规范即可.
即: Yarn不仅能调度MR计算任务, 还能调度Spark计算任务, Flink计算任务等...
32.简述Yarn的三大调度策略
问题5: 请简述你对Yarn的三大调度策略(调度器)的理解?
答案:
FIFO(先进先出): 目前几乎已经没有人使用了.
类似于: 单行道.
好处:
每个计算任务能独享集群100%的资源.
弊端:
不能并行执行, 如果大任务过多, 会导致小任务执行时间过长.Capacity(容量调度): 我们用的Apache Hadoop(社区版Hadoop), Yarn的底层默认用的就是这种调度器.
类似于: 多车道.
好处:
1. 可以当多任务, 并行执行, 提高计算效率.
2. 可以借调资源.
弊端:
1. 每个计算任务不能独享集群100%的资源, 存在着资源闲置(浪费)的情况.
2. 如果出现了资源借调的情况, 可能也会出现无法"及时"归还资源的情况.Fair(公平调度): FaceBook推出的, 后续要用的CDH(Cloudera公司提供的Hadoop, 商业版)的Yarn调度器就是这个.
类似于: 潮汐车道.
好处:
1. 多任务可以并行执行, 提高计算效率.
2. 如果只要1个任务, 则它可以共享集群100%的资源.
弊端:
每个任务获取集群的资源, 都是公平的, 均分的, 例如: 1个任务, 就占用 100%资源,
2个任务, 各占50%的资源
3个任务, 各占33.3333....%的资源
.......
如果小任务过多, 会导致大任务迟迟无法执行结束的问题.


33.hdfs为什么不适合存储小文件
hdfs中是按照block进行存储的,每个block默认是128M,即使该文件没有达到128M也会占用128M
的空间
34.mr为什么执行效率低
mr在shuffler阶段进行了大量的磁盘内存交互
35.reduce数量受什么影响? mr任务写入hdfs的文件数受什么影响?
受数据量,和map任务影响,(如果map任务超过一定数量也会新开一个reduce任务)
有几个reduce任务就有几个hdfs文件
36.map数量和reduce数量是越多越好么?
如果map数量过多,那么我们需要处理的数据就变少了,那么此时我们初始化启动map任务的时间就会大于 数据的逻辑处理时间,得不偿失
如果reduce过多会形成过多小文件,消耗磁盘空间,如果此结果要作为下一个计算的数据那么又会形成多个map 任务
37.yarn为什么可以作为公共资源调度平台
YARN(Yet Another Resource Negotiator)是 Hadoop 生态系统中的资源管理器,它可以作为公共资源调度平台的原因有以下几个方面:
- 灵活性:YARN 支持多种应用程序,包括 MapReduce、Spark、Hive 等,它可以根据不同的应用程序需求分配资源。
- 可扩展性:YARN 可以轻松地扩展到大规模集群,支持数千个节点和数万个任务。
- 资源隔离:YARN 提供了资源隔离机制,可以确保不同的应用程序之间不会相互干扰。
- 可靠性:YARN 具有高可靠性和容错性,可以确保集群的稳定运行。
- 开放性:YARN 是一个开放的平台,可以与其他开源框架和工具集成。
总之,YARN 具有灵活性、可扩展性、资源隔离、可靠性和开放性等优点,因此可以作为公共资源调度平台,为各种应用程序提供资源管理和调度服务。
38.yarn的容器机制
YARN 支持两种类型的容器:Map 容器和 Reduce 容器。Map 容器用于执行 Map 任务,而 Reduce 容器用于执行 Reduce 任务。每个容器都有一个唯一的标识,YARN 可以通过该标识来跟踪容器的状态和资源使用情况。
YARN 的容器机制可以提高应用程序的可靠性和可扩展性。通过容器隔离,不同的应用程序可以在同一台机器上安全地运行,而不会相互干扰。同时,YARN 可以根据应用程序的需求动态地分配资源,从而提高了集群的资源利用率。

