- 101-ChatGLM4实践—Python环境搭建_chat-glm4 python版本
- 2SwinTransformer与Vit细节总结_swin transformer和vit
- 3正点STM32F407核心板+ESP8266实现简单通信(详细讲解)_esp8266与stm32连接原理图
- 4FinnalShell高级版激活方法_finnashell
- 5链式队列(Linked Queue)
- 6Python筑基之旅-MySQL数据库(一)_mysql 8.0.37 python
- 7【Redis】—— Redis的RDB持久化机制_redis rdb
- 8python 应用 boto3操作s3服务器中文件(查看,过滤,复制,删除)_boto3 bucket 文件是否存在
- 9git checkout 远程分支_在 IntelliJ IDEA 中这样使用 Git,效率提升2倍
- 10AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.01-2024.05.10_vlsm-adapter 轻量级适配器,加速医学图像分割的视觉语言模型
Scikit-learn的六大功能_scikit-learn库的功能
赞
踩
Scikit-learn的功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。接下来通过一些例子来解释六类功能的主要作用。
1.分类
识别给定对象的类型,分类属于监督学习的范畴,最常见的应用场景包括图像识别和垃圾邮件检测。目前Scikit-learn已经实现的算法包括:支持向量机(SVM),逻辑回归,随机森林,最近邻,决策树等。
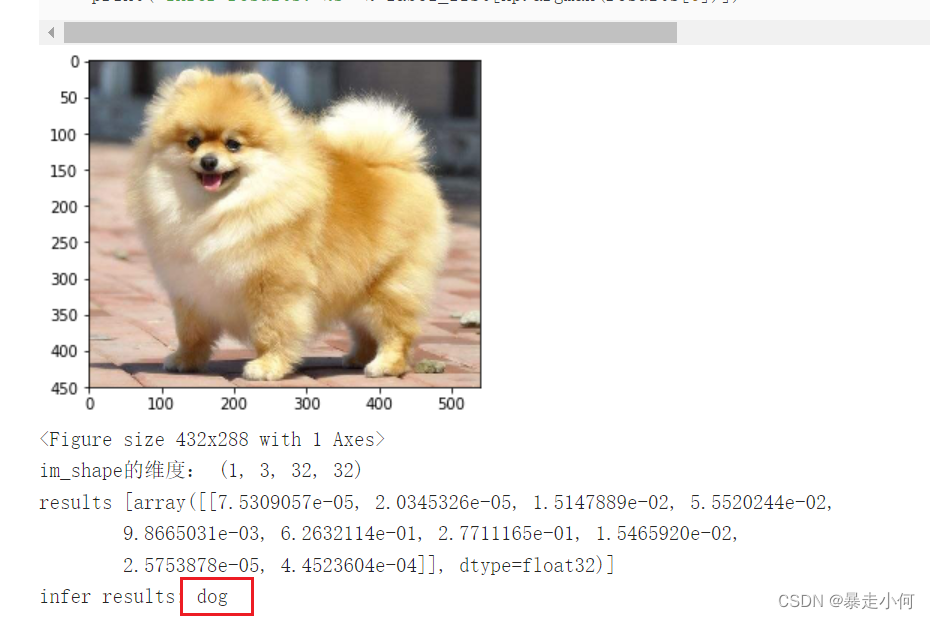
例1:猫狗识别
例2:中文垃圾邮件分类

2.回归
是指预测与给定对象相关联的连续值属性,最常见的应用场景包括预测股票价格和预测药物反应等。目前Scikit-learn 已经实现的算法包括:支持向量回归(SVR),弹性网络(Elastic Net),最小角回归(LARS ),贝叶斯回归等。
例3:特斯拉近10年股票价格分析预测
3.聚类
是指自动识别具有相似属性的对象,并将其分组为多个集合,属于无监督学习的范畴,最常见的应用场景包括顾客细分和试验结果分组。目前Scikit-learn已经实现的算法包括:K-均值聚类,谱聚类,均值偏移,分层聚类等。
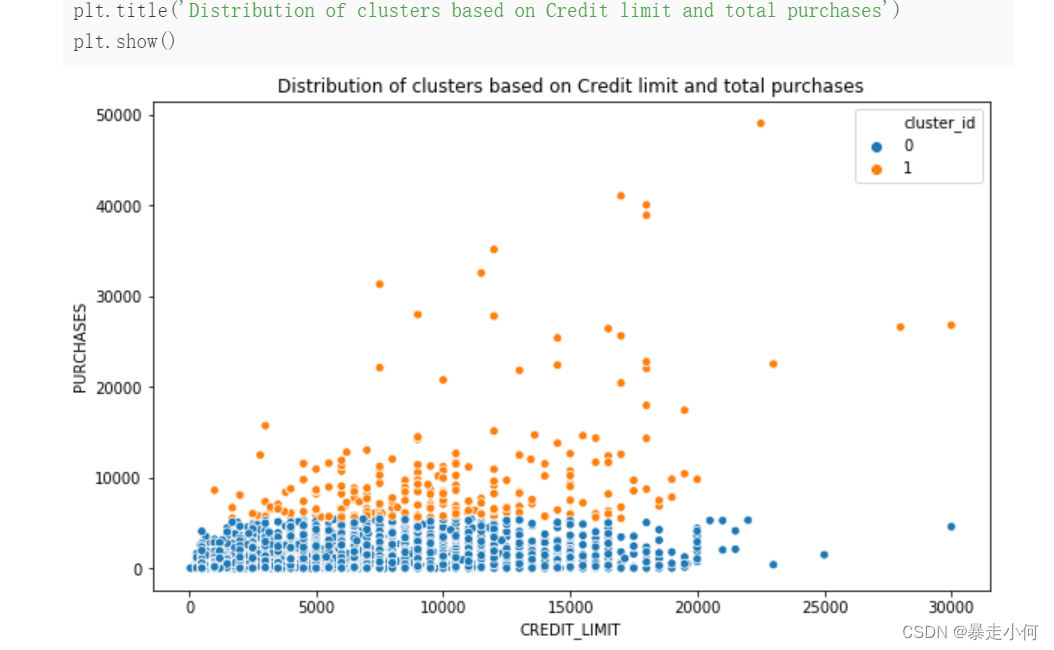
例4:信用卡客户划分
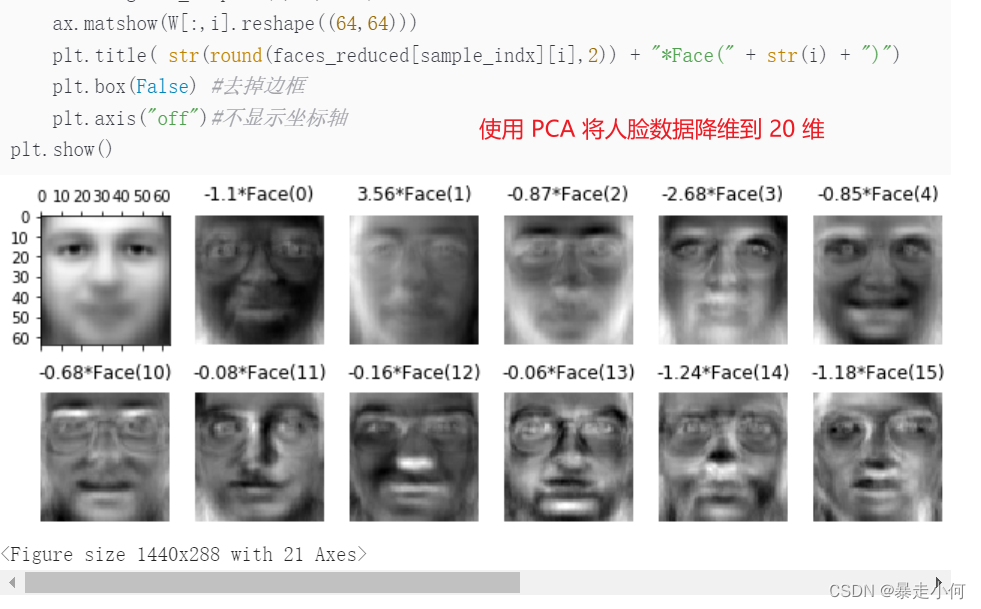
4.数据降维
是指使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
例5:PCA数据降维
5.模型选择
是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:格点搜索,交叉验证等。
例6:模型选择(评估方法)

6.数据预处理
是指数据的特征提取和归一化,是机器学习过程中的第一个也是最重要的一个环节。这里归一化是指将输入数据转换为具有零均值和单位权方差的新变量,但因为大多数时候都做不到精确等于零,因此会设置一个可接受的范围,一般都要求落在0-1之间。而特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。
例7:恶意代码静态特征提取