
- 1自动驾驶合集5
- 2一)Stable Diffusion使用教程:安装_stable diffusion官网
- 3【2023新书】《ChatGPT在做什么…以及它为什么好使》
- 4微信小程序保留小数点_小程序正则保留三位小数
- 5Servlet的request.getInputStream()只能读取一次问题_测试环境 mono.just() ioutils.tostring(servletrequest.g
- 6App Widgets 详解一 简单使用_小部件 appwidget_enabled
- 7maven核心,pom.xml详解
- 8项目配置集成unocss指南,配合VsCode插件太香了_vscode unocss
- 92021年熔化焊接与热切割免费试题及熔化焊接与热切割考试技巧_焊接作业最常见危害也最广泛的职业危害是什么
- 10openstack 管理 四十一 创建自己的 glance image_虚机镜像制作glance imange
假期错题-虽然没啥用_5.一棵完全二叉树上有1000个结点,则该完全二叉树中度为0的结点数为 500 ,度为1的
赞
踩
1、栈区(stack)由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap)一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事。
区别:
-
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生内存溢出。
-
空间大小:堆内存几乎是没有什么限制。栈一般都是有一定的空间大小。
-
碎片问题:对于堆来讲,频繁的new/delete会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题。
-
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。
-
分配效率:栈的效率比较高。堆的效率比栈要低得多。
-
增长方向:堆的增长方向是从程序低地址到高地址向上增长,而栈的增长方向刚好相反(实际情况可能不是这样的,与CPU的体系结构有关)
设有 6 个结点的无向图,该图至少应有 ( ) 条边才能确保是一个连通图。
正确答案: A 你的答案: B (错误)
5
6
7
8
- 1
- 2
- 3
- 4
各个点都要连接上,边数比顶点数少一个
Prim 有个点 准对点(点少边多)
Kruskal 针对边(点多边少)
在一个有向图的拓扑序列中,若顶点 a 在顶点 b 之前,则图中必有一条弧<a,b>。( )
(改为路径是对的)
正确答案: B 你的答案: A (错误)
正确
错误
- 1
- 2
选B。该题考察的是拓扑排序的概念,如果从 a 到 b 有一条有向路径,则 a 一定排在 b 之前,反过来也应该以“路径”更准确。
注意区分“路径”和“弧”:
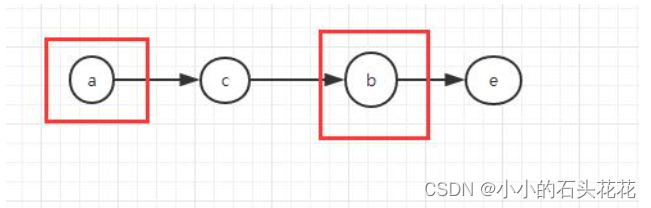
弧:指的是有向图里面的边,有明确方向的。如果是无向图的边,直接叫做“边”。比如有向图的 v1 结点到 v2 结点的弧可能是:<v1, v2>;路径:指的是图(包括有向图和无向图)里面连接两个结点之间的边的集合,也就是一个顶点序列。比如:v1 到 v3 的路径可能这样表示:<v1, v2>、<v2, v3>;如下图举例所示:顶点 a 在顶点 b 之前,但**没有弧****<a,b>,而是一条路径<a,c><c,b>
只要在无向有权图中存在1个环(回路)的权值之和为负值,我们就称此无向图存在“负权回路”下面哪个算法可以检验一个无向图是否存在负权回路?
正确答案: A 你的答案: C (错误)
最短路径 Bellman-Ford 算法
最小生成树 Kruskal 算法
最小生成树 Prim 算法
最短路径 Dijkstra 算法
- 1
- 2
- 3
- 4
B,C,D都是生成树的,自然测不出回路
用邻接矩阵法存储一个图时,在不考虑压缩存储的情况下,所占用的存储空间大小只与图中结点个数有关,而与图的边数无关,这样的说法正确吗?
正确答案: A 你的答案: B (错误)
正确
不正确
- 1
- 2
邻接矩阵是用一维数组存储图中顶点的信息,用矩阵表示图中顶点之间的邻接关系。都是顶点之间的关系,所以正确
KMP算法时间复杂度为O(m+n),空间复杂度为O(m)。 因为KMP算法涉及到next数组的存储,且next数组是基于模式串长度计算的。
二叉排序树的中序遍历序列是升序的有序序列。
设非空二叉树的所有子树中,其左子树上的结点值均小于根结点值,而右子树上的结点值均不小于根结点值,则称该二叉树为排序二叉树。对排序二叉树的遍历结果为有序序列的是( )。
正确答案: A 你的答案: D (错误)
中序序列
前序序列
后序序列
前序序列或后序序列
- 1
- 2
- 3
- 4
一棵完全二叉树具有1000个结点,则此完全二叉树有 ( )个度为2的结点。
正确答案: C 你的答案: D (错误)
497
498
499
500
- 1
- 2
- 3
- 4
公式1 : n0=n2+1;
公式2 :总结点=n0+n1+n2;
计算:n0+n1+n2=1000
n0=n2+1;
将公式带入 2n2+n1+1=1000
因为度为1的节点只有 0 或者1个所以。将值带入。计算得到结果。
关于哈弗曼树,下列说法错误的是?
正确答案: A 你的答案: C (错误)
为字符编码需要从叶节点开始再向上
哈弗曼树可以通过在优先级队列中的插入和移除操作来创建
最常出现的字符总是在靠近树顶附近出现
通常,信息解码需要重复的顺着根到叶的路径走
- 1
- 2
- 3
- 4
A选项写的是编码,不是构造。别看错了
在一般包含n个节点的二叉搜索树中查找的最差时间复杂度是?
正确答案: B 你的答案: B (正确)
O(log(n))
O(n)
O(n^2)
O(1)
- 1
- 2
- 3
- 4
对于二叉搜索树,当先后插入的关键字有序时,退化成链表,树的深度为n,时间复杂度等于顺序查找O(n/2)= O(n)
下面关于B和B+树的叙述中,不正确的是( )
正确答案: C 你的答案: D (错误)
B树和B+树都是平衡的多叉树。
B树和B+树都可用于文件的索引结构。
B树和B+树都能有效地支持顺序检索。
B树和B+树都能有效地支持随机检索。
- 1
- 2
- 3
- 4
B树只支持随机搜索,B+ 树支持随机和顺序搜索。
求最小生成树的普里姆(Prim)算法中边上的权可正可负。
正确答案: A 你的答案: B (错误)
正确
错误
- 1
- 2
prim算法权值是可正可负的,Dijkstra算法是不能有负的权值的。
由权值序列(5,6,2,10,9,8)构造一棵赫夫曼树,其带权路径长度WPL值是( )
正确答案: D 你的答案: C (错误)
25
68
110
100
- 1
- 2
- 3
- 4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oA4yLkkm-1665557998924)(https://uploadfiles.nowcoder.com/images/20180816/8261286_1534411288116_07F5DFABF67A4D9CF02176D655E26FE0)]](https://img-blog.csdnimg.cn/1a8b1006dbef499c85de2a2a9cc8608d.png)
(2+5)4 + 63 + (8+9+10)*2 = 100
BatchNorm 层对于 input batch 会统计出 mean 和 variance 用于计算 EMA。如果input batch 的 shape 为(B, C, H, W),统计出的 mean 和 variance 的 shape 为: ()
正确答案: B 你的答案: B (正确)
B * 1 * 1 * 1
1 * C * 1 * 1
B * C * 1 * 1
1 * 1 * 1 * 1
- 1
- 2
- 3
- 4
B代表图像的batch,即多少张图像一个batch。C代表图像的通道数。
BN是对多张图像的同一通道做Normalization
所以有多少通道就有多少个mean和variance
深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C 的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m <n < p < q,以下计算顺序效率最高的是()
正确答案: A 你的答案: A (正确)
(AB)C
AC(B)
A(BC)
所以效率都相同
- 1
- 2
- 3
- 4
维度低的先相乘效率更高
ResNet-50 有多少个卷积层? ()
正确答案: B 你的答案: C (错误)
48
49
50
51
- 1
- 2
- 3
- 4
ResNet-50就是因为它有50层网络,这50层里只有一个全连接层,剩下的都是卷积层,所以是50-1=49
防止模型过拟合:
1.引入正则化(参数范数惩罚)
2.Dropout
3.提前终止训练
4.增加样本量
5.参数绑定与参数共享
6.辅助分类节点(auxiliary classifiers)
7.Batch Normalization
深度学习中的激活函数需要具有哪些属性?()
正确答案: A B D 你的答案: A B C (错误)
计算简单
非线性
具有饱和区
几乎处处可微
- 1
- 2
- 3
- 4
使用一个长度最大为150的队列,对满二叉树进行广度优先遍历时,能够容纳的二叉树的最大深度(第一层深度为1)为()
正确答案: A 你的答案: B (错误)
8
10
9
7
- 1
- 2
- 3
- 4
满二叉树每一层的结点个数为(第一层深度为1)第n层的节点数:2^(n-1),如果使用150的队列进行广度优先遍历,
则每一层的节点数不大于150,2(n-1)≤150,27=128,2^8=256,n-1最多为7,所以最大深度n=8.
对于以下用数组存储的二叉树A B C D E采用中序和前序遍历的结果是()
正确答案: A C 你的答案: A (错误)
A B D E C
D E B C A
D B E A C
C E D B A
- 1
- 2
- 3
- 4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wb03yT5G-1665557998926)(http://uploadfiles.nowcoder.com/images/20160307/921406_1457331553548_ABA607D7F02855BAC42088561F7C2F6E)]](https://img-blog.csdnimg.cn/b506bf17b6724a50a153f371c92a2629.png)
以数组存储,是按照层次序来保存的。所以A在第一层BC在第二层DE在第三层。
查找哈希表,解决冲突的方法包括()
正确答案: A D 你的答案: A C D (错误)
链地址法
除留余数法
直接地址法
线性探测再散列法
- 1
- 2
- 3
- 4
表达式"X=A+B*(C-D)/E"的后缀表示形式可以是()
正确答案: C 你的答案: A (错误)
XAB+CDE/-*=
XA+BC-DE/*=
XABCD-*E/+=
XABCDE+*/=
- 1
- 2
- 3
- 4
选 c
人工实现转换
这里我给出一个中缀表达式:a+b*c-(d+e)
第一步:按照运算符的优先级对所有的运算单位加括号:式子变成了:((a+(b*c))-(d+e))
第二步:转换后缀表达式
后缀:把运算符号移动到对应的括号后面
则变成了:((a(bc)* )+ (de)+ )-
把括号去掉:abc*+de± 后缀式子出现
STL中的优先队列是采用什么数据结构来实现的?()
正确答案: A 你的答案: C (错误)
堆
队列
栈
图
- 1
- 2
- 3
- 4
最大容量为n的循环队列,队尾指针是rear,队头是front,则队空的条件是()
正确答案: B 你的答案: B (正确)
(rear+1) MOD n=front
rear=front
rear+1=front
(rear-1) MOD n=front
- 1
- 2
- 3
- 4
循环队列的相关条件和公式:
1.队空条件:rear==front
2.队满条件:(rear+1) %QueueSIze==front,其中QueueSize为循环队列的最大长度
3.计算队列长度:(rear-front+QueueSize)%QueueSize
4.入队:(rear+1)%QueueSize
5.出队:(front+1)%QueueSize
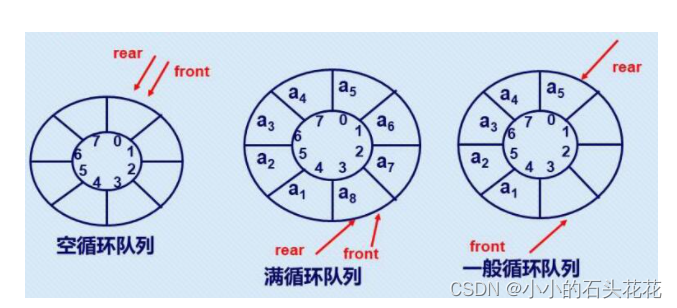
- 队列属于逻辑结构的概念,它们的物理存储既可以利用数组也可以利用链表完成,所以循环队列属于逻辑上首尾相接的抽象圆环,如上图所示。A错误。
- 空队列头尾指针指向同一个区域(0区域),所以F==R;满队列是随着元素的入队,尾指针逐渐加1,直到从0区域加到****SIZE-1区域,这时尾指针指向SIZE-1区域,头指针指向0区域。判断队满的条件是尾指针再加1(由于是循环)所以头尾指针重合在0区域,(R+1)%SIZE==F
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xcSWDhtw-1665557998927)(https://uploadfiles.nowcoder.com/images/20190422/242025553_1555930910796_48295BE4A697ABC49160FE4FD64D4DA9)]](https://img-blog.csdnimg.cn/5b97fd938bf64b3e81fe024b98b7b1bb.png)
便于插入和删除的容器是()
正确答案: A C D 你的答案: C (错误)
list
vector
map
set
- 1
- 2
- 3
- 4
在快速排序中,要使最坏情况的空间复杂度为O(log2n )则要对快速排序作( )修改。
正确答案: A 你的答案: B (错误)
划分元素为三者取中
采用表排序
先排最小集合
先排大集合
- 1
- 2
- 3
- 4
选A。
快速排序的思想:
- 先从数列中取出一个数作为基准数
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边
- 再对左右区间重复第二步,直到各区间只有一个数
最优的情况下空间复杂度为:O(log2n) ;每一次都平分数组的情况,基准数尽量为中间数。
下面哪种排序的平均比较次数最少()
正确答案: D 你的答案: B (错误)
插入排序
选择排序
堆排序
快速排序
- 1
- 2
- 3
- 4
上图。虽然平均情况下快排和堆排时间复杂度都为O(nlogn),甚至堆排序的最坏情况下时间复杂度和辅助空间都优于快排。但是不能否认的是,虽然都是O(nlogn)级别,但是快排的常数因子要小于堆排序。实验可验。
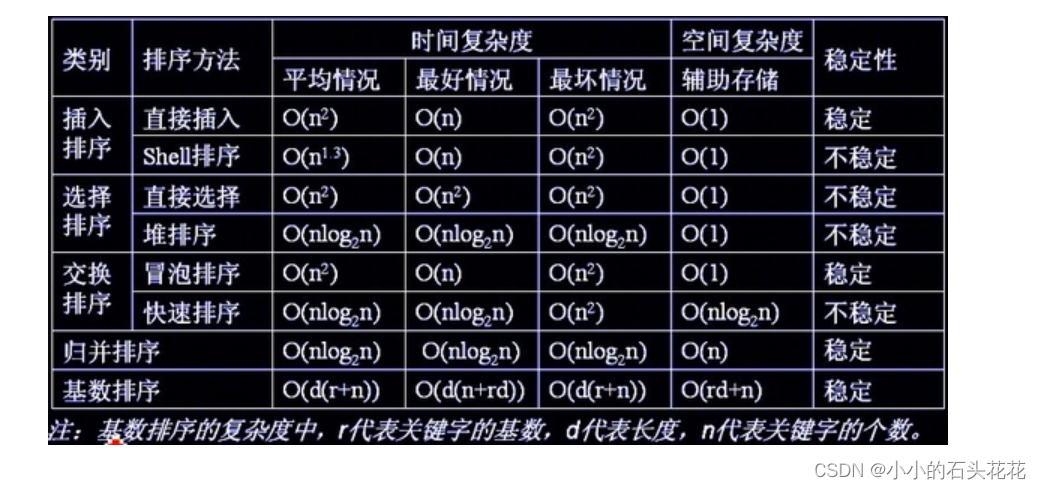
下列排序方法中,稳定的排序方法是()
正确答案: A B E 你的答案: E (错误)
//直接插入排序
//归并排序
希尔排序
快速排序
//基数排序
- 1
- 2
- 3
- 4
- 5
不稳定: 快(快速)些(shell 希尔)选(选择)队(堆)
关于数据结构,下面叙述中正确的是()
正确答案: B D 你的答案: B C (错误)
直接选择排序是一种稳定的排序方法
//哈弗曼树带权路径长度最短的树,路径上权值较大的结点离根较近
拓扑排序是指结点值得有序排序
//当从一个最小堆中删除一个元素时,需要把堆尾元素填补到堆顶位置,然后再按条件把它逐层向下调整到合适位置
- 1
- 2
- 3
- 4
A:直接选择排序中存在着不相邻元素之间的互换,因此,直接选择排序是一种不稳定的排序方法。 A错
B:哈夫曼树定义 给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。B对
C:我查找资料说有序指的是 不是结点的值有序,是结点的逻辑先后关系保持有序 C错
D:属于堆排序过程 D对
京东商城plus会员的消费记录金额分别为900,512,613,700,810,若采用选择排序算法对其进行从小到大的排序,第三趟排序结果为:()
正确答案: C 你的答案: 空 (错误)
900512613700810
512900613700810
512613700900810
512613700810900
- 1
- 2
- 3
- 4
***选择排序*的工作原理是每一次从待排序的数据元素中选出最小( 或最大)的一个元素,存放在序列的起始位置,在剩余的未排序的元素中继续重复上述操作,直至全部待排序的元素排完。所以本题的解题过程:
第一趟排序:512 900 613 700 810
第二趟排序:512 613 900 700 810
第三趟排序:512 613 700 900 810
在一棵二叉排序树上查找值为35的数据,以下比较的数据序列正确的为
正确答案: D 你的答案: D (正确)
28、36、18、46、35
18、36、28、46、35
46、28、18、36、35
46、36、18、28、35
- 1
- 2
- 3
- 4
选D
A.【28,?】→【28,36】→18不在这个区间,错误
B.【18,?】→【18,36】→【28,36】→46不在这个区间,错误
C.【?,46】→【28,46】→18不在这个区间,错误
D.【?,46】→【?,36】→【18,36】→【28,36】→找到35
如果待排序的数组近似递减排序,则此时使用快排算法进行递增排序的时间复杂度为()
正确答案: B 你的答案: C (错误)
O(n)
O(n^2)
O(nlogn)
O((n^2)*logn
- 1
- 2
- 3
- 4
退化为了冒泡排序,而冒泡排序的时间复杂度为O(n2)。
某种排序方法对关键字序列(33,12,44,10,6,8,17)进行排序时,前三趟排序的结果如下:
6,12,44,10,33,8,17
6,8,44,10,33,12,17
6,8,10,44,33,12,17
则采用的排序方法是()
正确答案: D 你的答案: A (错误)
希尔排序
归并排序
快速排序
选择排序
- 1
- 2
- 3
- 4
首先观察排序的特点:会发现,最小的数值会被依次挪到最前面,一看就可以知道:选择排序。
选择排序:就是从待排序数中找出最小的数,然后将最小的数字所在的位置和第一位数进行交换即可,之后找出次小的数字,同样交换位置即可。
采用递归方式对顺序表进行快速排序,下列关于递归次数的叙述中,正确的是()
正确答案: D 你的答案: D (正确)
递归次数与初始数据的排列次序无关
每次划分后,先处理较长的分区可以减少递归次数
每次划分后,先处理较短的分区可以减少递归次数
递归次数与每次划分后得到的分区处理顺序无关
- 1
- 2
- 3
- 4
递归次数,取决于递归树,而递归树取决于轴枢的选择。树越平衡,递归次数越少。
而对分区的长短处理顺序,影响的是递归时对栈的使用内存,而不是递归次数
关于排序算法的以下说法,正确的是?
正确答案: C 你的答案: C (正确)
快速排序的平均时间复杂度为O(nlogn),最坏时间复杂度为O(nlogn)
堆排序的平均时间复杂度为O(nlogn),最坏时间复杂度为O(n^2)
冒泡排序的平均时间复杂度为O(n^2),最坏时间复杂度为O(n^2)
归并排序的平均时间复杂度为O(nlogn),最坏时间复杂度为O(n^2)
- 1
- 2
- 3
- 4
C
A,快速排序最坏时间复杂度为O(n^2)
B,堆排序最坏为O(nlogn)
C,正确
D,归并排序,最坏时间复杂度O(nlogn)
完全二叉树中的叶子结点只可能在最后两层中出现。( )
正确答案: A 你的答案: B (错误)
正确
错误
- 1
- 2
关于二叉树,下面说法正确的是()
正确答案: B D 你的答案: A B D (错误)
A 二叉树中至少有一个节点的度为2
B 一个具有1025个节点的二叉树,其高度范围在11到1025之间
C 对于n个节点的二叉树,其高度为n*log(n)
D 二叉树的先序遍历是EFHIGJK,中序遍历为HFIEJKG,该二叉树的右子树的根为G
- 1
- 2
- 3
- 4
二叉树可以是空树,所以可以没有节点的度为2
(4)具有n个结点的完全二叉树的深度为
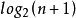
基于哈希的索引和基于树的索引有什么区别?
正确答案: A B C D 你的答案: B C (错误)
hash索引仅满足“=”、“IN”和“<=>”查询,不能使用范围查询
hash索引无法被用来进行数据的排序操作
对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用
Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高
- 1
- 2
- 3
- 4
1、hash索引仅满足“=”、“IN”和“<=>”查询,不能使用范围查询
因为hash索引比较的是经常hash运算之后的hash值,因此只能进行等值的过滤,不能基于范围的查找,因为经过hash算法处理后的hash值的大小关系,并不能保证与处理前的hash大小关系对应。
2、hash索引无法被用来进行数据的排序操作
由于hash索引中存放的都是经过hash计算之后的值,而hash值的大小关系不一定与hash计算之前的值一样,所以数据库无法利用hash索引中的值进行排序操作。
3、对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
4、Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
排序的方法有很多种,()法是基于选择排序的一种方法,是完全二叉树结构的一个重要应用。
正确答案: E 你的答案: C (错误)
快速排序
插入排序
归并排序
选择排序
堆排序
- 1
- 2
- 3
- 4
- 5
E
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n个元素中次小(或次大)的元素。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。称这个过程为堆排序。
已知一棵树的先序序列和后序序列,一定能构造出该树,这种说法()
正确答案: A 你的答案: B (错误)
正确
错误
- 1
- 2
如果是二叉树,那么必须要先序+中序,或者中序+后序,但是题目中说的是树,树的先序(根)== 二叉树的先序,树的后序(根)== 二叉树的中序,所以是一定可以构造出来的。
现有一棵无重复关键字的平衡二叉树(AVL 树),对其进行中序遍历可得到一个降序序列。下列关于该平衡二叉树的叙述中,正确的是 () 。
正确答案: D 你的答案: A (错误)
根结点的度一定为 2
树中最小元素一定是叶结点
最后插入的元素一定是叶结点
树中最大元素一定是无左子树
- 1
- 2
- 3
- 4
只有两个结 点 的平衡二叉树的 根 结点的度 为 1 , A 错误。 中序遍历 后可以得到一个降序序列 ,树中最小元素一定无左子树 (可能有右子树),因此不一定是叶结点, B 错误。最后插入的结点可能会导致 平衡 调整,而不一定是叶结 点 , C 错误 。
根据邻接表和邻接矩阵的结构特性可知,当图为稀疏图、顶点较多,即图结构比较大时,更适宜选择邻接表作为存储结构。当图为稠密图、顶点较少时,或者不需要记录图中边的权值时,使用邻接矩阵作为存储结构较为合适。
1)联系:邻接表中每个链头后的所有边表结点对应邻接矩阵中的每一行,邻接表中的每个边表结点对应邻接矩阵该行的一个非零元素。
(2)区别:
①对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)。
②邻接矩阵的空间复杂度为0(n2),而邻接表的空间复杂度为0(n+e)。
③在邻接表上容易找到任意一顶点的第一个邻接点和下一个邻接点,但要判定任意两个顶点(vi,vj)之间是否有边或弧相连,则需搜索第i个或第j个链表,还不及邻接矩阵方便。
④邻接矩阵多用于稠密图的存储(e接近n(n-1)/2),而邻接表多用于稀疏图的存储(e<<n2)。
邻接矩阵
有向图、无向图和网对应的邻接矩阵如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JzfJDIjv-1665557998930)(假期错题.assets/image-20220706182642776.png)]
图的邻接表存储方式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3c2OPrsF-1665557998931)(假期错题.assets/image-20220706182705817.png)]
1、请问你了解原码、反码和补码么,能不能简单概述一下?声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/337004?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

