
热门标签
热门文章
- 1【机器学习实战-python3】缩减系数来“理解”数据_缩减系数来“ 理解”数据
- 2毕业论文开题报告生成器工具推荐三款!_开题报告生成器免费
- 32020款Macbook Pro忘了激活锁账户密码如何向苹果申请解锁(已成功解锁)_macbook pro您的账户已被锁定如何解锁
- 4江苏事业单位计算机类考试题型,2021江苏事业单位统考笔试科目考哪些?题型题量如何分布?...
- 5基于Python爬虫安徽滁州景点数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 6Python基于微博的大数据舆论,情感分析可视化系统,附源码_微博情感分析可视化
- 7【无人机编队】二阶一致性多无人机协同编队控制(考虑通信半径和碰撞半径)【含Matlab源码 4215期】
- 8白话篇:利用二叉树先序/中序/后序确定二叉树求法分析_2.假二叉树 bt 的后序遍历序列为 ao;a1,..,an-1,设计一个算法按 ax-1、
- 9Windows BAT批处理命令详解_win bat
- 10java基于SSM的宠物医院信息管理系统_宠物管理系统的国内研究动态实例
当前位置: article > 正文
mmdetection算法之DETR(1)_mmdetection实现的detr为什么norm没有add
作者:weixin_40725706 | 2024-03-29 23:09:16
赞
踩
mmdetection实现的detr为什么norm没有add
DETR里的Transformer
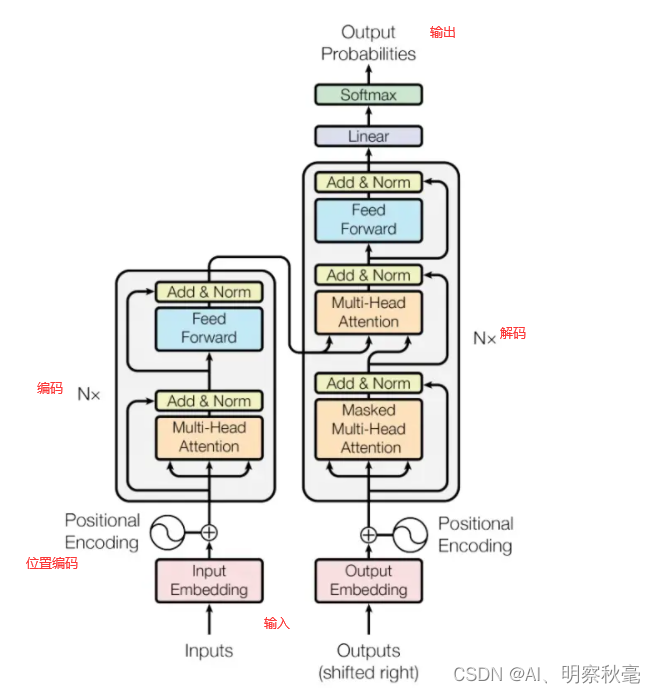
Transformer的前向操作
def forward(self, x, mask, query_embed, pos_embed): """Forward function for `Transformer`. Args: x (Tensor): Input query with shape [bs, c, h, w] where c = embed_dims. mask (Tensor): The key_padding_mask used for encoder and decoder, with shape [bs, h, w]. query_embed (Tensor): The query embedding for decoder, with shape [num_query, c]. pos_embed (Tensor): The positional encoding for encoder and decoder, with the same shape as `x`. Returns: tuple[Tensor]: results of decoder containing the following tensor. - out_dec: Output from decoder. If return_intermediate_dec \ is True output has shape [num_dec_layers, bs, num_query, embed_dims], else has shape [1, bs, \ num_query, embed_dims]. - memory: Output results from encoder, with shape \ [bs, embed_dims, h, w]. """ bs, c, h, w = x.shape # use `view` instead of `flatten` for dynamically exporting to ONNX x = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c] pos_embed = pos_embed.view(bs, c, -1).permute(2, 0, 1) query_embed = query_embed.unsqueeze(1).repeat( 1, bs, 1) # [num_query, dim] -> [num_query, bs, dim] mask = mask.view(bs, -1) # [bs, h, w] -> [bs, h*w] memory = self.encoder( # 编码 query=x, key=None, value=None, query_pos=pos_embed, query_key_padding_mask=mask) target = torch.zeros_like(query_embed) # out_dec: [num_layers, num_query, bs, dim] out_dec = self.decoder( # 解码 query=target, key=memory, value=memory, key_pos=pos_embed, query_pos=query_embed, key_padding_mask=mask) out_dec = out_dec.transpose(1, 2) memory = memory.permute(1, 2, 0).reshape(bs, c, h, w) return out_dec, memory

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
BaseTransformerLayer的前向操作
def forward(self, query, key=None, value=None, query_pos=None, key_pos=None, attn_masks=None, query_key_padding_mask=None, key_padding_mask=None, **kwargs): """Forward function for `TransformerDecoderLayer`. **kwargs contains some specific arguments of attentions. Args: query (Tensor): The input query with shape [num_queries, bs, embed_dims] if self.batch_first is False, else [bs, num_queries embed_dims]. key (Tensor): The key tensor with shape [num_keys, bs, embed_dims] if self.batch_first is False, else [bs, num_keys, embed_dims] . value (Tensor): The value tensor with same shape as `key`. query_pos (Tensor): The positional encoding for `query`. Default: None. key_pos (Tensor): The positional encoding for `key`. Default: None. attn_masks (List[Tensor] | None): 2D Tensor used in calculation of corresponding attention. The length of it should equal to the number of `attention` in `operation_order`. Default: None. query_key_padding_mask (Tensor): ByteTensor for `query`, with shape [bs, num_queries]. Only used in `self_attn` layer. Defaults to None. key_padding_mask (Tensor): ByteTensor for `query`, with shape [bs, num_keys]. Default: None. Returns: Tensor: forwarded results with shape [num_queries, bs, embed_dims]. """ norm_index = 0 attn_index = 0 ffn_index = 0 identity = query # [100,bs,256] if attn_masks is None: attn_masks = [None for _ in range(self.num_attn)] elif isinstance(attn_masks, torch.Tensor): attn_masks = [ copy.deepcopy(attn_masks) for _ in range(self.num_attn) ] warnings.warn(f'Use same attn_mask in all attentions in ' f'{self.__class__.__name__} ') else: assert len(attn_masks) == self.num_attn, f'The length of ' \ f'attn_masks {len(attn_masks)} must be equal ' \ f'to the number of attention in ' \ f'operation_order {self.num_attn}' for layer in self.operation_order: if layer == 'self_attn': # 编码的时候用这个 temp_key = temp_value = query # x[100,bs,256],这里 query = self.attentions[attn_index]( query, temp_key, temp_value, identity if self.pre_norm else None, query_pos=query_pos, key_pos=query_pos, attn_mask=attn_masks[attn_index], key_padding_mask=query_key_padding_mask, **kwargs) # [bs,100,256] attn_index += 1 # identity = query elif layer == 'norm': query = self.norms[norm_index](query) norm_index += 1 elif layer == 'cross_attn': query = self.attentions[attn_index]( query, # x key, # None value, # None identity if self.pre_norm else None, query_pos=query_pos, key_pos=key_pos, attn_mask=attn_masks[attn_index], # None key_padding_mask=key_padding_mask, # 注意 **kwargs) attn_index += 1 identity = query elif layer == 'ffn': query = self.ffns[ffn_index]( query, identity if self.pre_norm else None) ffn_index += 1 return query
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
编码
memory = self.encoder( # 编码
query=x,
key=None,
value=None,
query_pos=pos_embed,
query_key_padding_mask=mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 编码里,输入的q,k,v,其中q是x(shape[H*W,bs,256]),k=v=q。这里开始要注意输入输出的shape
- attn_mask = None
- key_padding_mask=key_padding_mask(上面传入的=query_key_padding_mask=mask)
编码部分就是使用self_atten
def forward(self, query, key=None, value=None, identity=None, query_pos=None, key_pos=None, attn_mask=None, key_padding_mask=None, **kwargs): """Forward function for `MultiheadAttention`. **kwargs allow passing a more general data flow when combining with other operations in `transformerlayer`. Args: query (Tensor): The input query with shape [num_queries, bs, embed_dims] if self.batch_first is False, else [bs, num_queries embed_dims]. key (Tensor): The key tensor with shape [num_keys, bs, embed_dims] if self.batch_first is False, else [bs, num_keys, embed_dims] . If None, the ``query`` will be used. Defaults to None. value (Tensor): The value tensor with same shape as `key`. Same in `nn.MultiheadAttention.forward`. Defaults to None. If None, the `key` will be used. identity (Tensor): This tensor, with the same shape as x, will be used for the identity link. If None, `x` will be used. Defaults to None. query_pos (Tensor): The positional encoding for query, with the same shape as `x`. If not None, it will be added to `x` before forward function. Defaults to None. key_pos (Tensor): The positional encoding for `key`, with the same shape as `key`. Defaults to None. If not None, it will be added to `key` before forward function. If None, and `query_pos` has the same shape as `key`, then `query_pos` will be used for `key_pos`. Defaults to None. attn_mask (Tensor): ByteTensor mask with shape [num_queries, num_keys]. Same in `nn.MultiheadAttention.forward`. Defaults to None. key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys]. Defaults to None. Returns: Tensor: forwarded results with shape [num_queries, bs, embed_dims] if self.batch_first is False, else [bs, num_queries embed_dims]. """ if key is None: key = query if value is None: value = key if identity is None: identity = query if key_pos is None: if query_pos is not None: # use query_pos if key_pos is not available if query_pos.shape == key.shape: key_pos = query_pos else: warnings.warn(f'position encoding of key is' f'missing in {self.__class__.__name__}.') if query_pos is not None: query = query + query_pos # 加位置编码 if key_pos is not None: key = key + key_pos # 加位置编码 # Because the dataflow('key', 'query', 'value') of # ``torch.nn.MultiheadAttention`` is (num_query, batch, # embed_dims), We should adjust the shape of dataflow from # batch_first (batch, num_query, embed_dims) to num_query_first # (num_query ,batch, embed_dims), and recover ``attn_output`` # from num_query_first to batch_first. if self.batch_first: query = query.transpose(0, 1) key = key.transpose(0, 1) value = value.transpose(0, 1) out = self.attn( # 进入多头注意力机制,分了8个,256/8=32,后面会cat回去 query=query, # 这个就是transformer的常规操作,就不进入去看了 key=key, # 就是计算自注意力,注意输出就行 value=value, attn_mask=attn_mask, key_padding_mask=key_padding_mask)[0] # 返回[bs,h*w,c] if self.batch_first: out = out.transpose(0, 1) # 转换维度,[h*w,bs,c] return identity + self.dropout_layer(self.proj_drop(out)) # 残差,要dropout,可能数据量太大了吧,也可以防止过拟合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
解码
target = torch.zeros_like(query_embed)
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder( # 解码
query=target, # [num_query, dim]
key=memory, # [h*w,bs,c]
value=memory, # [h*w,bs,c]
key_pos=pos_embed, # [num_query, bs, dim]
query_pos=query_embed, # [num_query, bs, dim]
key_padding_mask=mask) # [bs, h*w]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 解码看图第一个部分是self_attn, 输入q=target,k=v=q,返回q[num_query, bs, dim]
- 第二部分是cross_attn,输入是q[num_query, bs, dim], key=value=memory, # [h*w,bs,c]我们主要看看cross_attn部分。shape不同,是怎么进行自注意力的
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query, # [num_query, dim]
key, # [h*w,bs,c]
value, # [h*w,bs,c]
identity if self.pre_norm else None,
query_pos=query_pos, # [num_query, bs, dim]
key_pos=key_pos, # [num_query, bs, dim]
attn_mask=attn_masks[attn_index], #none
key_padding_mask=key_padding_mask, # [bs, h*w]
**kwargs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
进入一个函数,原理应该和自注意力差不多。想仔细看的话在:open-mmlab2/lib/python3.7/site-packages/torch/nn/functional.py文件夹的multi_head_attention_forward函数里
- q:[100,1,256]-[100,8,256/8]-[8,100,32]
- k:[hw,1,256]-[hw,1,256/8]-[8,h*w,32]
- v:[hw,1,256]-[hw,1,256/8]-[8,h*w,32]
- 进行公式的自注意力操作
# 这只是为了方便理解,我截取的公式那部分代码,不是完整的,原理就是这样 attn_output_weights = torch.bmm(q, k.transpose(1, 2)) #[8,100,32]@[8,32,h*w] = [8,100,h*w] assert list(attn_output_weights.size()) == [bsz * num_heads, tgt_len, src_len] if attn_mask is not None: if attn_mask.dtype == torch.bool: attn_output_weights.masked_fill_(attn_mask, float('-inf')) else: attn_output_weights += attn_mask if key_padding_mask is not None: # attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len) #[b,8,100,h*w] attn_output_weights = attn_output_weights.masked_fill( key_padding_mask.unsqueeze(1).unsqueeze(2), float('-inf'), ) attn_output_weights = attn_output_weights.view(bsz * num_heads, tgt_len, src_len) attn_output_weights = softmax( # softmax attn_output_weights, dim=-1) attn_output_weights = dropout(attn_output_weights, p=dropout_p, training=training) #使用了dropout attn_output = torch.bmm(attn_output_weights, v) #[8,100,h*w]@[8,h*w,32] = [8,100,32] assert list(attn_output.size()) == [bsz * num_heads, tgt_len, head_dim] attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim) # 最后转换维度展平成[100,1,256] attn_output = linear(attn_output, out_proj_weight, out_proj_bias)# 后面还要经过个线性层,计算y = xA^T + b if need_weights: # average attention weights over heads attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len) return attn_output, attn_output_weights.sum(dim=1) / num_heads
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/337865
推荐阅读
相关标签

