
- 1树莓派配置环境变量,解决No such file or directory的错误提示_树莓派vncunable to open i2c device: no such file or d
- 2洛谷p3817 小A的糖果
- 3C语言easyx飞机大战源码+素材(大屏版)_易语言 飞机大战
- 4基于SpringBoot的农产品销售小程序平台的设计与实现_基于springboot粮食加工订单
- 5Word Tokenization
- 6浅析自动编码器(自编码器 Autoencoder)_深度学习 coding decoding
- 7抖音商品详情数据接口python_python 获取抖音商户信息
- 8MATLAB非线性规划优化问题_带约束的非线性优化算法代码
- 9毕业设计:基于卷积神经网络的图像分类系统 python人工智能_基于卷积神经网络的图像分类系统研究研究或设计的目的和意义:
- 10Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation 阅读笔记_dual-pool contrastive learning
pytorch-学习率调整-torch.optim.lr_scheduler_torch.optim.lr_scheduler adam
赞
踩
torch.optim.lr_scheduler
pytorch提供了以下学习率调整的方式,转自pytorch官网
Prior to PyTorch 1.1.0, the learning rate scheduler was expected to be called before the optimizer’s update; 1.1.0 changed this behavior in a BC-breaking way. If you use the learning rate scheduler (calling scheduler.step()) before the optimizer’s update (calling optimizer.step()), this will skip the first value of the learning rate schedule. If you are unable to reproduce results after upgrading to PyTorch 1.1.0, please check if you are calling scheduler.step() at the wrong time.
暗示pytorch1.1.0版本以后,schedule.step()要在optimizer.step()之后
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
Sets the learning rate of each parameter group to the initial lr times a given function. When last_epoch=-1, sets initial lr as lr. Parameters optimizer (Optimizer) – Wrapped optimizer. lr_lambda (function or list) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups. last_epoch (int) – The index of last epoch. Default: -1. Example >>> # Assuming optimizer has two groups. >>> lambda1 = lambda epoch: epoch // 30 >>> lambda2 = lambda epoch: 0.95 ** epoch >>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2]) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上面代码是每30个epoch学习率*0.95?不是这样的,看这个
应该是只能传入一个参数,计算的是一个与epoch相关的学习率乘数因子
lr = scheduler.get_lr()这个函数get√
自己测试下
from torch.optim import Adam, lr_scheduler from torchvision import models import matplotlib.pyplot as plt lambda1 = lambda epoch:epoch // 10 lambda2 = lambda epoch:0.5**epoch alexnet = models.alexnet(pretrained=True) optim = Adam(params=alexnet.parameters(), lr=0.1) scheduler = lr_scheduler.LambdaLR(optim, lr_lambda=lambda2) x = list(range(100)) y = [] for i in range(100): scheduler.step() lr = scheduler.get_lr() print(lr) y.append(lr[0]) plt.plot(x, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
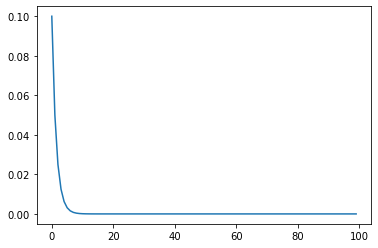
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
Sets the learning rate of each parameter group to the initial lr decayed by gamma every step_size epochs. When last_epoch=-1, sets initial lr as lr. Parameters optimizer (Optimizer) – Wrapped optimizer. step_size (int) – Period of learning rate decay. gamma (float) – Multiplicative factor of learning rate decay. Default: 0.1. last_epoch (int) – The index of last epoch. Default: -1. Example >>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 60 >>> # lr = 0.0005 if 60 <= epoch < 90 >>> # ... >>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这个比较好理解,每隔多少epoch学习率成比率下降,其实不是每个多少个epoch,你在每个batch后运行这个,他也会更新,所以是每运行多少次这个函数scheduler.step(),更新以下学习率
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
Set the learning rate of each parameter group to the initial lr decayed by gamma once the number of epoch reaches one of the milestones. When last_epoch=-1, sets initial lr as lr. Parameters optimizer (Optimizer) – Wrapped optimizer. milestones (list) – List of epoch indices. Must be increasing. gamma (float) – Multiplicative factor of learning rate decay. Default: 0.1. last_epoch (int) – The index of last epoch. Default: -1. Example >>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 80 >>> # lr = 0.0005 if epoch >= 80 >>> scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
和上面的差不多,这里是传入一个列表
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
Set the learning rate of each parameter group to the initial lr decayed by gamma every epoch. When last_epoch=-1, sets initial lr as lr.
Parameters
optimizer (Optimizer) – Wrapped optimizer.
gamma (float) – Multiplicative factor of learning rate decay.
last_epoch (int) – The index of last epoch. Default: -1.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
单纯的指数降低,是不是太快了0.0
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)

Parameters
optimizer (Optimizer) – Wrapped optimizer.
T_max (int) – Maximum number of iterations.
eta_min (float) – Minimum learning rate. Default: 0.
last_epoch (int) – The index of last epoch. Default: -1.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
还有好多没看了,用到再看吧2333
-
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08) -
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1) -
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, last_epoch=-1) -
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1)

