
- 1COBOL语言基础总结
- 2(阿里巴巴)中台能力引介_中台引出能力
- 3HomeAssistant添加HACS商店_homeaasistant hacs
- 4python如何下载指定版本TensorFlow_python下载tensorflow库
- 52023亚太杯数学建模B题完整原创论文讲解_2022亚太杯数学建模竞赛题目b题
- 6Tomcat调优参数配置_compressablemimetype
- 7python 字符串 f_Python格式化字符串(f,F,format,%)
- 8Open WebUI-专为 LLM 设计的WEB管理工具_openwebui 网络搜索 百度
- 9【springboot进阶】基于starter项目构建(一)父级项目_springboot父子项目的搭建
- 10音视频开发——ffmpeg解码(四)_ffmpeg video codec
anomalib实战学习记录:安装及训练官方数据_anomalib训练自己的数据集
赞
踩
我下载的版本是:anomalib-1.1.0
操作系统是:win11
代码的结构为: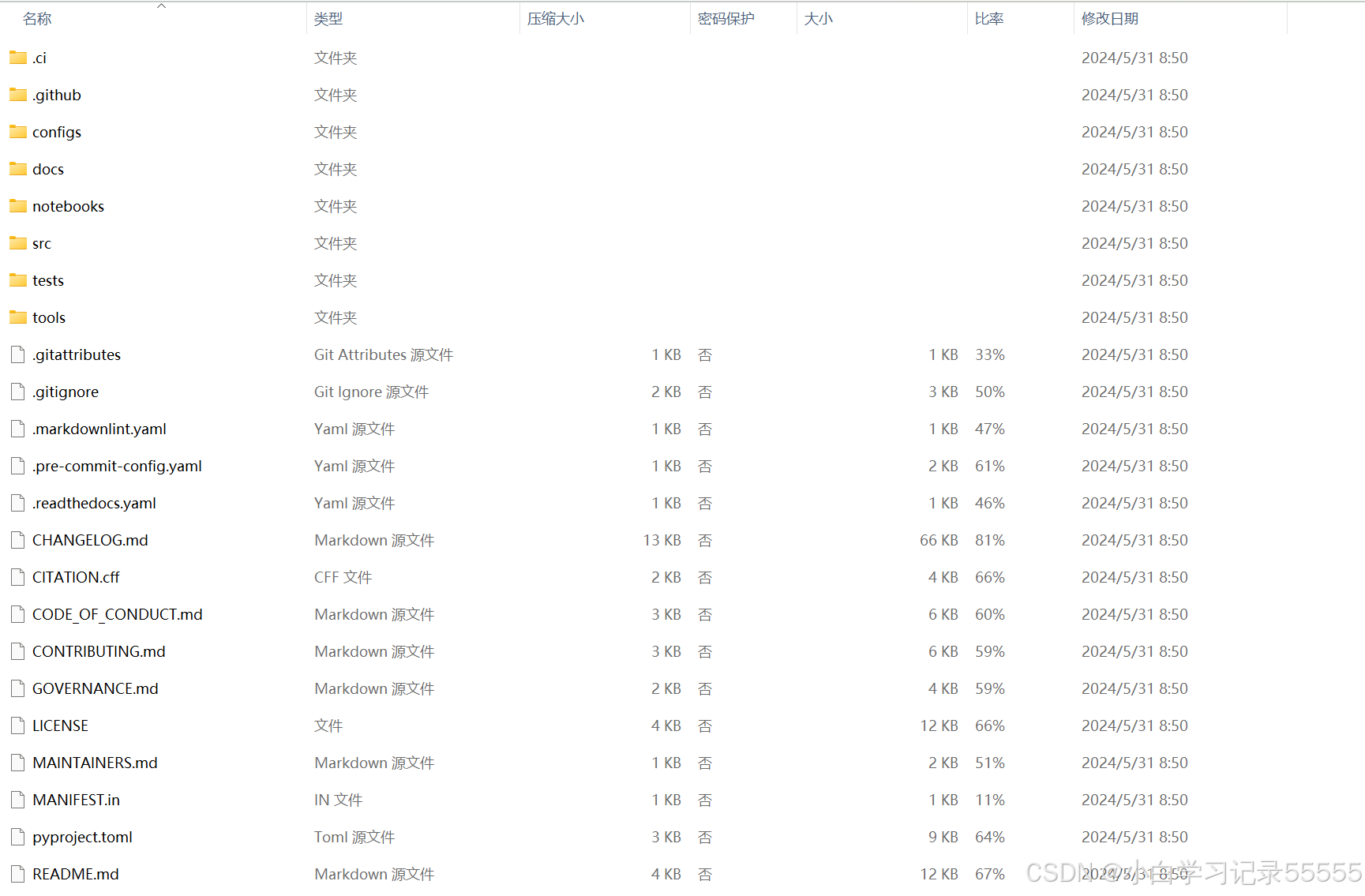 新版本的anomalib没有单独的train.py文件了,后面需要自己新建train.py文件,或者用命令行进行训练。
新版本的anomalib没有单独的train.py文件了,后面需要自己新建train.py文件,或者用命令行进行训练。
一、安装
1、需要通过conda新建一个python=3.10的虚拟环境:
conda create -n anomalib_env python=3.10
2、激活环境:
conda activate anomalib_env
3、通过下载源码进行安装:
- git clone https://github.com/openvinotoolkit/anomalib.git
- cd anomalib
- pip install -e .


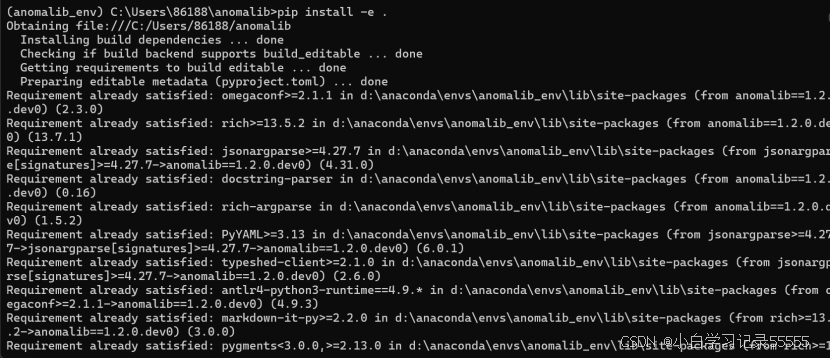
4、安装anomalib需要的相关库
- anomalib install -h
- anomalib install
- anomalib install -v
- anomalib install --option core
- anomalib install --option openvino
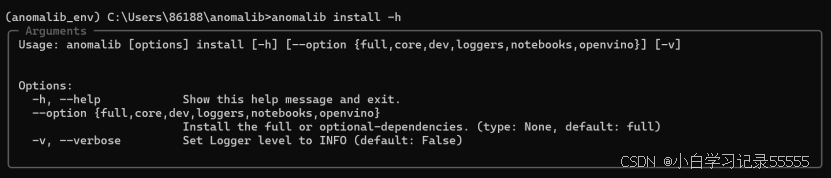
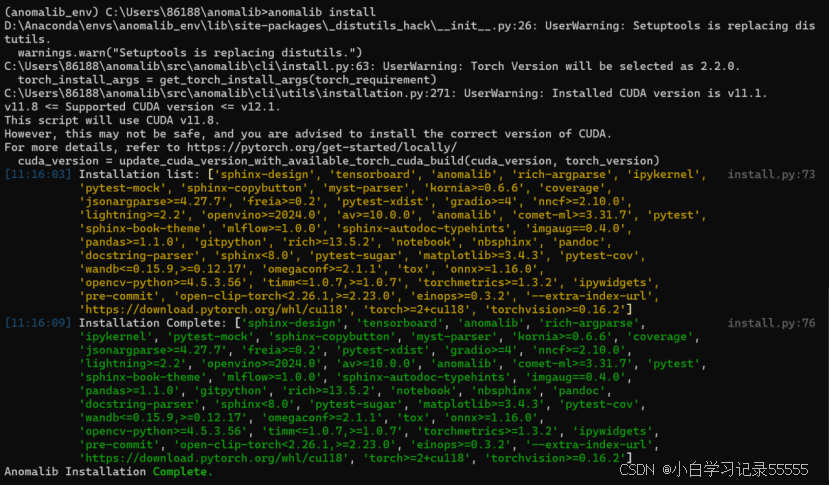
后面三个的命令我没有截图,依次安装即可。
二、训练
我是使用pycharm进行训练的。使用pycharm打开源码,新建train.py文件。train.py内容如下(来自官网):
- # Import the required modules
- from anomalib.data import MVTec
- from anomalib.models import Patchcore
- from anomalib.engine import Engine
-
- # Initialize the datamodule, model and engine
- datamodule = MVTec()
- model = Patchcore()
- engine = Engine()
-
- # Train the model
- engine.train(datamodule=datamodule, model=model)
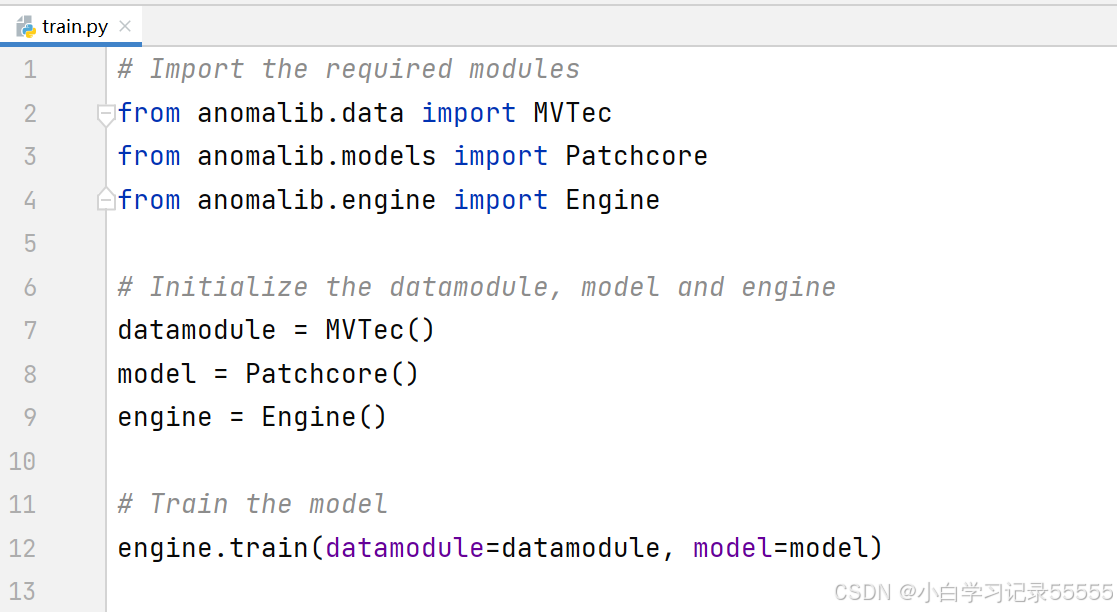
开始训练即可。刚开始训练的时候,会下载MVTec数据集,可能会下载不下来,可以在报错信息里面复制下载链接,自行下载,下载好了之后,放在对应的文件夹中。
我在训练的过程中,报错如下:
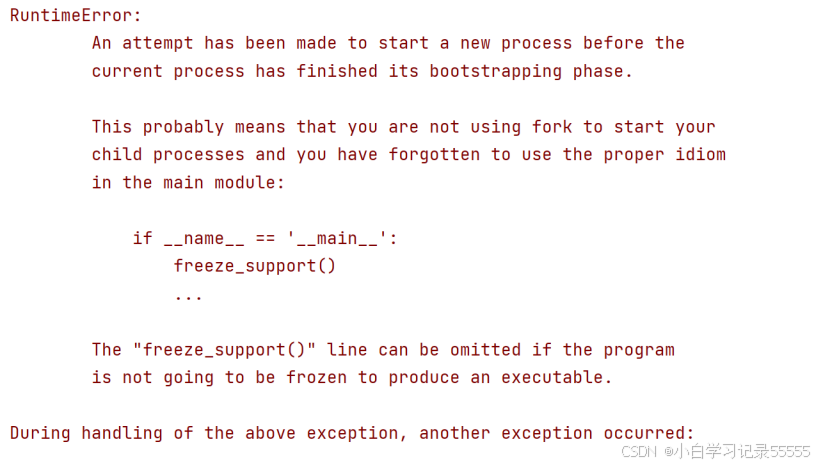
修改train.py:
- datamodule = MVTec()
- # 修改为:
- datamodule = MVTec(num_workers=0)
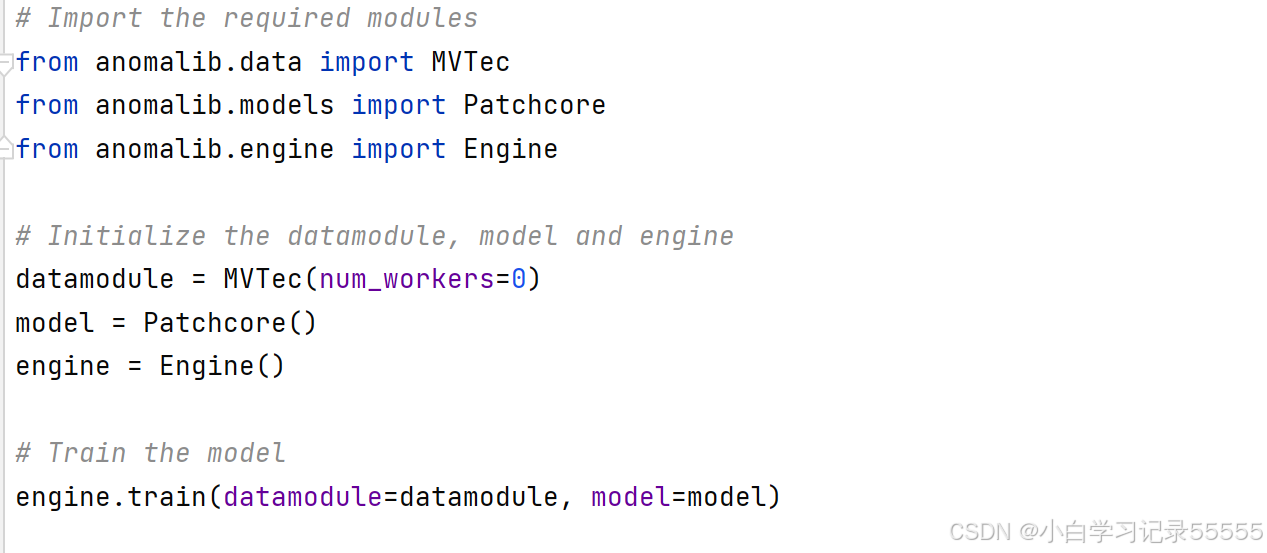
然后就可以训练了。
三、推理
- predictions = engine.predict(
- datamodule=datamodule,
- model=model,
- ckpt_path="model.ckpt", #修改成自己训练生成的model.ckpt文件路径
- )
训练的时候,会生成一个results文件夹,model.ckpt文件就在results文件夹里面。推理的代码可以直接放在train.py文件的最下面,即engine.train(datamodule=datamodule, model=model)后面。
四、数据集的划分
官方教程:
Custom Data — Anomalib 2022 documentation![]() https://anomalib.readthedocs.io/en/latest/markdown/guides/how_to/data/custom_data.html通过官网给的链接,下载hazelnut_toy数据集放在datasets文件夹里面:
https://anomalib.readthedocs.io/en/latest/markdown/guides/how_to/data/custom_data.html通过官网给的链接,下载hazelnut_toy数据集放在datasets文件夹里面:
可以重新建一个train_toy.py
内容如下:
- from anomalib.models import Patchcore
- from anomalib.engine import Engine
- from anomalib.data import Folder
-
- # Create the datamodule
- datamodule = Folder(
- name="hazelnut_toy",
- root="datasets/hazelnut_toy",
- normal_dir="good",
- abnormal_dir="colour",
- task="classification",
- num_workers=0,
- image_size=[256,256],
- val_split_ratio=0.5,
- )
-
- # Setup the datamodule
- datamodule.setup()
-
- i, train_data = next(enumerate(datamodule.train_dataloader()))
- print(train_data.keys())
-
- i, val_data = next(enumerate(datamodule.val_dataloader()))
- print(val_data.keys())
-
- i, test_data = next(enumerate(datamodule.test_dataloader()))
- print(test_data.keys())
-
- model = Patchcore()
- engine = Engine(task="classification")
- engine.train(datamodule=datamodule, model=model)

推理的代码为:
- predictions = engine.predict(
- datamodule=datamodule,
- model=model,
- ckpt_path="model.ckpt", # 存放model.ckpt文件的路径,需要对应修改
- )
结果如下:

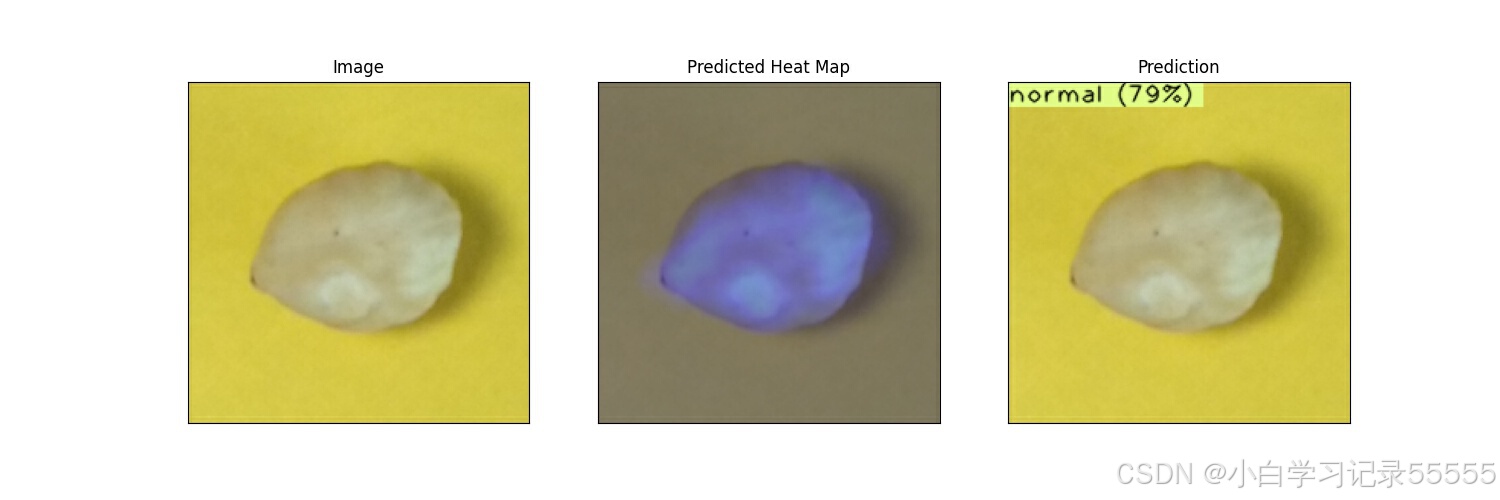
五、onnx模型导出
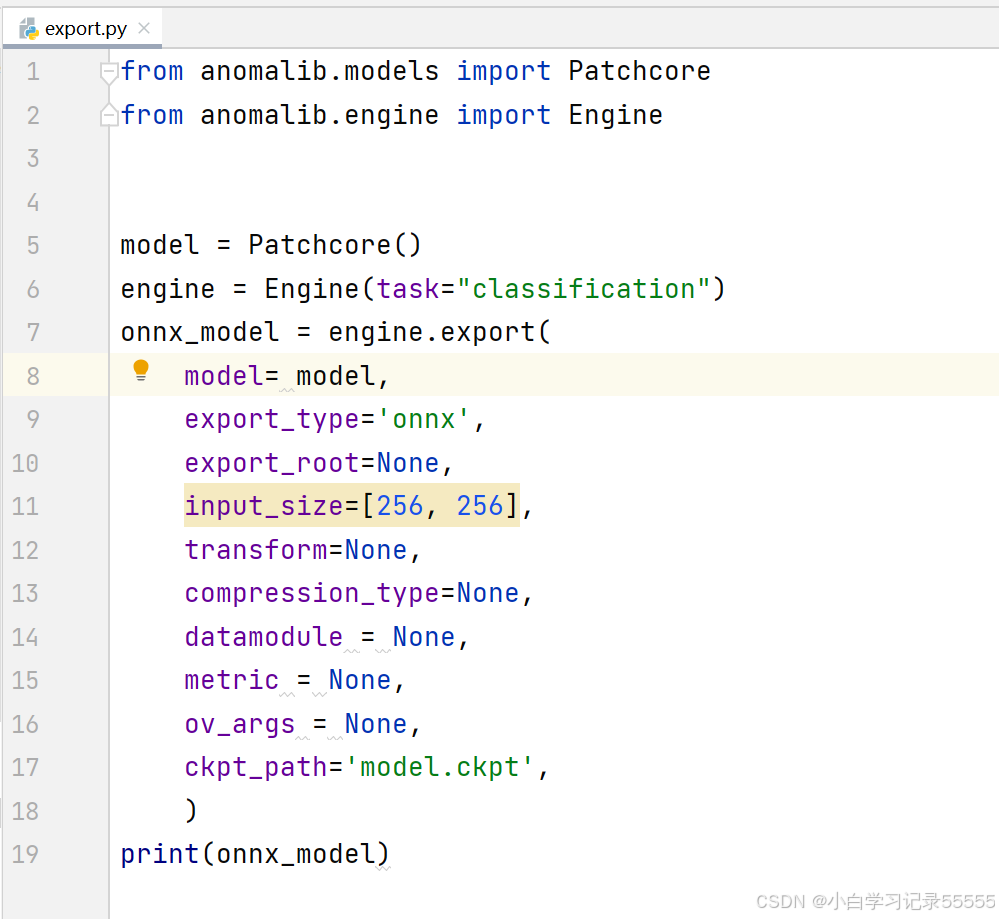
新建export.py文件,内容如下:
- from anomalib.models import Patchcore
- from anomalib.engine import Engine
-
-
- model = Patchcore()
- engine = Engine(task="classification")
- onnx_model = engine.export(
- model= model,
- export_type='onnx',
- export_root=None,
- input_size=[256, 256],
- transform=None,
- compression_type=None,
- datamodule = None,
- metric = None,
- ov_args = None,
- ckpt_path='model.ckpt', # 存放model.ckpt文件的路径,需要对应修改
- )
- print(onnx_model)
可以导出onnx模型,具体细节可以研究一下engine.py文件里面的export部分,有比较详细的说明。

