
热门标签
热门文章
- 1合合信息大模型加速器亮相WAIC大会:文档解析与文本识别新突破
- 2Python NumPy库详解:高效处理数组的利器
- 3使用Drozer对Android四大组件进行测试_run app.activity.start --component
- 4centos/ubuntu—yum/apt-get软件安装_yum安装apt-get
- 5设置Linux时区和时间_linux 修改时区为北京
- 6Visual Studio显示C4996错误,建议使用scanf_s函数
- 7css3 做成的音频波动效果_css 仿siri音频波纹
- 8代码随想录算法训练营第七天 | 454.四数相加II | 383. 赎金信 |15. 三数之和 |18.四数之和
- 9机器学习——房屋价格预测【回归问题】_使用多个特征作为输入完成房价预测问题,计算模型在十折交叉验证上mae和rmse的值,
- 10配置SQLServer,允许远程连接,将自己的sqlserver设为服务器,允许别人访问_sql server 的配置正确,允许链接外部数据源,并且允许使用 ole db 访问接口。
当前位置: article > 正文
李沐深度学习-ch02_正向累积和反向累积哪个内存高
作者:代码探险家 | 2024-08-06 20:09:52
赞
踩
正向累积和反向累积哪个内存高
数据操作:
N维数组是机器学习和神经网络的主要数据结构
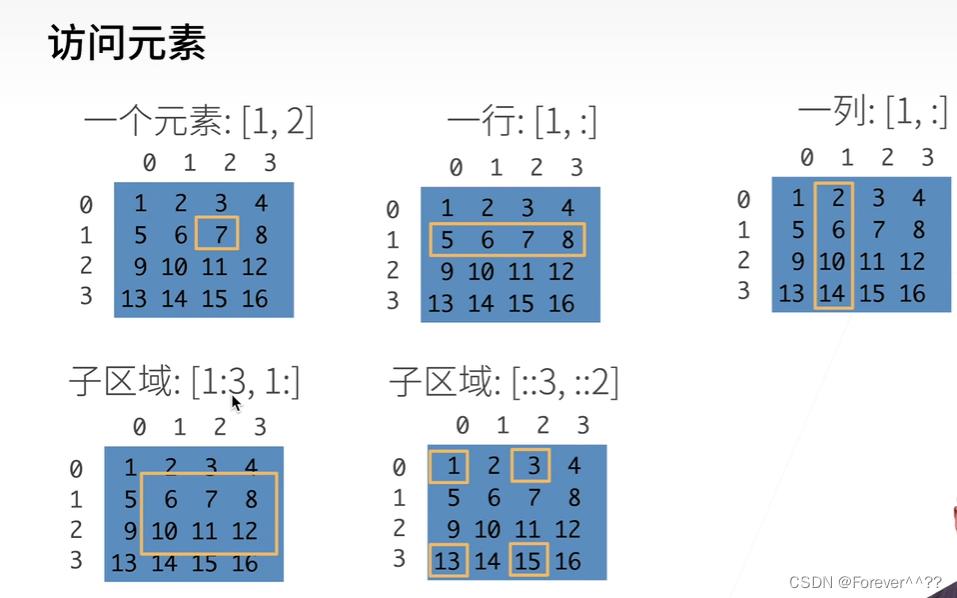
最后一个子区域代表::3为每三行选1个。::2为每2列选1个
矩阵计算:
1、首先将导数拓展到向量
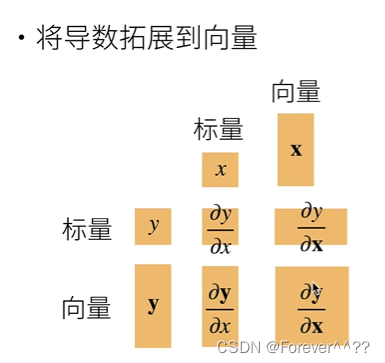
1.x和y都是标量,最终结果也是标量
2.x标量,y向量,最终结果是向量(若y是行向量,则求导结果是行向量。否则是列向量)
3.x向量,y标量,最终结果是向量(若x是行向量,则求导结果是列向量。否则是行向量)
4.x和y都是向量,最终结果也是矩阵(先将y向量拆解,最后将拆解的内容按照原来y的排列生成一个矩阵)
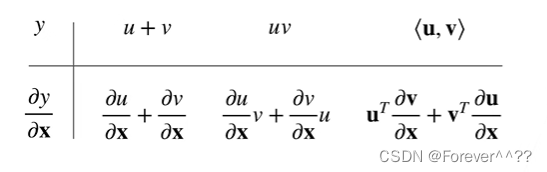
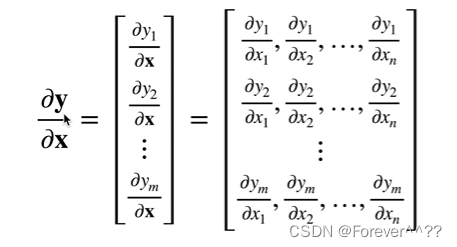
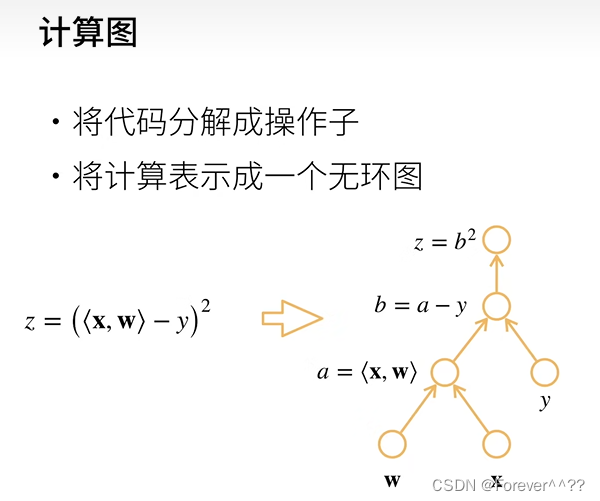
7.自动求导
自动求导计算一个函数再指定值上的导数。与符号求导和数值求导有区别
向量的链式法则:
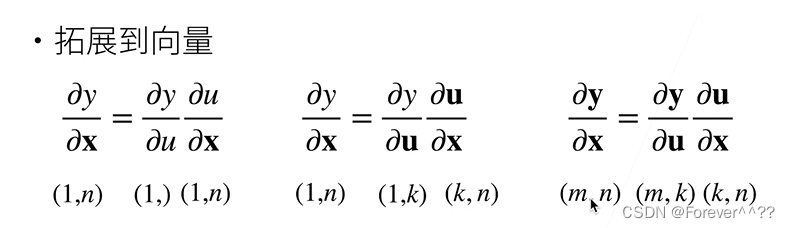
由于深度学习的神经网络普遍几百层,一层层使用链式求导很复杂,则获得自动求导方法:
具体针对具体值的求导:
自动求导的两种模式:
正向累积和反向传递

反向传递过程需要使用到正向累计中计算结果。当反向传播时,有些结点的值是不需要计算的。
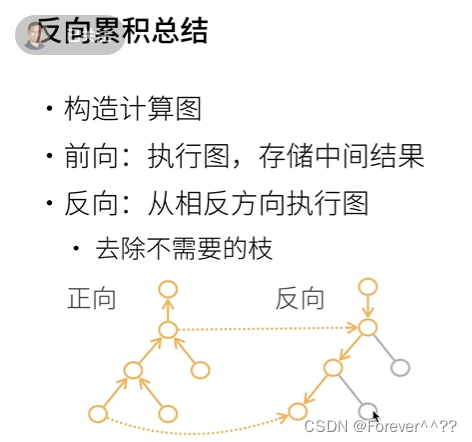
反向累积前,需要先正着来一遍计算复杂度0(n),然后反向累积的计算复杂度O(n)。(正向+反向)
反向累积内存复杂度高O(n),因为需要把正向的中间结果储存下。所以深度神经网络很耗GPU资源。
下图中,上面的正向只反向的第一步,下面的正向指正向累积。
正向累积的好处是,内存复杂度O(1),不管多深,不用存储中间结果,但是缺点是,每计算一个变量的梯度需要扫一遍O(n)。所以神经网络中不太用,因为神经网络需要对每一层算梯度,正向累积计算复杂度太高。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/939102
推荐阅读
相关标签

