
- 1DApp浏览器交互环境_tp钱包中的dapp浏览器怎么和钱包交互的
- 2Linux系统下安装ElasticSearch_elasticsearch linux 安装
- 3基于SpringBoot的学生会管理系统的设计与实现 毕业设计开题报告_基于spring boot学生智能排课系统的设计与实现应收集的资料及主要参考文献有什么
- 4大模型爱好者的福音,有了它个人电脑也可以运行大模型了_gpt4all
- 5Hbase原理(底层原理,存储架构,寻址策略,读写流程,master和Regionserver的工作机制)_hbase 读写流程?hbase内部机制是什么?
- 62024-07-19 Unity插件 Odin Inspector10 —— Misc Attributes
- 7开源AI智能名片源码:数据对接引领品牌营销新纪元_数字名片链接聚合工具源码
- 8自然语言处理(NLP)实验——语言模型应用_自然语言处理实验
- 9编程新纪元:AI辅助工具豆包Marscode体验_marscode和通义灵码
- 10Vue + OpenLayers 实现 GeoJSON 文件的加载和解析,并为每个 feature 添加渐变颜色_vue+openlayers 给feature填充pattern模式颜色
三、图嵌入与所需基础知识
赞
踩
目录
一、基础
1、图嵌入目标
用低维、稠密、实值的向量表示网络中的节点。图嵌入是将属性图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息
2、图嵌入方法分类
1)基于因子分解的方法
2)基于随机游走的方法
3)基于深度学习的方法
3、参考
代码:
论文:
二、graph embedding
待补充
1、Deepwalk
1.1 核心思想
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
1.2 算法实现步骤
①输入network/graph
②进行随机游走(random walk)
③得到节点序列(representation mapping)
④放到skip-gram模型中(中间节点预测上下文节点)
⑤output: representation(中间的隐层)
2、LINE
3、node2vec
4、Struc2vec
5、SDNE
二、图嵌入基础-词嵌入
词嵌入的目标:将词语映射为一个实数向量,同时保留词语之间语义的相似性和相关性
思想:通过某种降维算法,将向量映射到低纬度空间中,相似的词语位置较近,不相似的词语位置较远
1、N-gram
N-gram(N元)模型,就是在计算概率时,忽略长度大于N的上下文词的影响,只考虑前面的N个词
基于统计的语言模型,从概率论专业角度来描述就是:为长度为m的字符串确定其概率分布P(w_1, w_2, ..., w_n),其中w_1到w_n依次表示文本中的各个词语。一般采用链式法则计算其概率值:
P(w_1, w_2, ..., w_n) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_m|w_1,w_2,...,w_{m-1})
缺陷:N值越大,保留的词序信息(上下文)越丰富,但计算量也呈指数级增长。
2、NNLM
2.1 网络结构
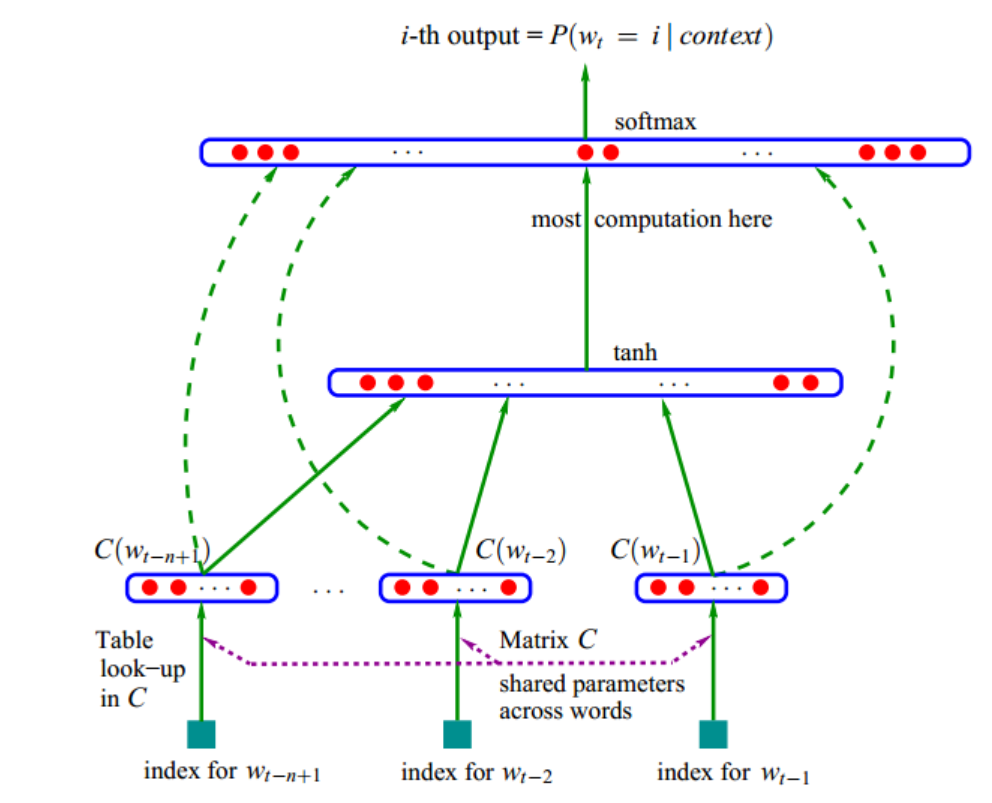
图中参数解释
look-up:查表
C(w)表示w对应的词向量
V表示语料中的总词数,m表示词向量的维度
矩阵C为 m行,|V| 列
2.2 前向传播
- 输入:前N-1个词语的向量(one-hot表示的向量)拼接,形成以一个(n-1)Xm大小的向量,记为x
- 网络的第二层(隐藏层):直接使用全连接,d+Hx
- 输出:第N个词语的一组概率,y=b+wx+Utanh(d+Hx),其中U为|V|Xh矩阵,从隐藏层到输出层的参数
2.3 目标函数
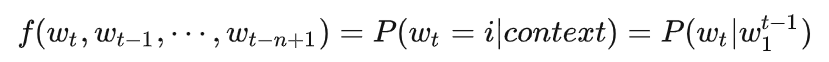
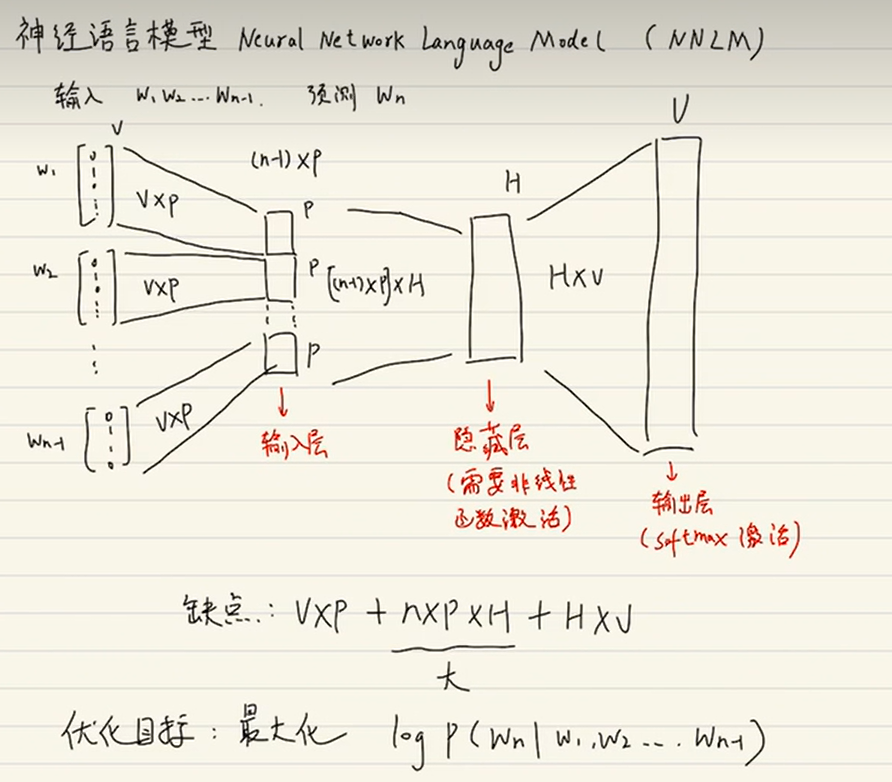
2.4 网络结构的示意图表示
2.5 示例
设词典大小为1000,向量维度为25,N=3
先将前N个词表示成独热向量
输入矩阵为:[3, 1000]
权重矩阵:[1000, 25]
隐藏层:[3, 1000] * [1000, 25] = [3, 25]
输出层权重:[25, 1000]
输出矩阵:[3, 25] * [25, 1000] = [3, 1000] ==> [1, 1000],表示预测属于1000个词的概率.
其中,将[3,1000]转化过程可用求和、求均值、权重相加等方法,变成【1,1000】
3、Word2vec
目标:学习一个从高维稀疏离散向量到低维稠密连续向量的映射。
特点:近义词向量的欧氏距离比较小,词向量之间的加减法有实际物理意义。
Word2Vec由两部分组成:CBOW和Skip-Gram
3.1 CBOW
训练目标是最大化给定上下文时中心单词出现的概率
与NNLM区别:
将中间的隐藏层去掉。同时,用来预测object word的context word的词向量不再合并, 而是求平均
3.2 Skip-gram
4、共现矩阵
定义:共现(co-occurrence)矩阵指通过统计一个事先指定大小的窗口内的词语共现次数,以词语周边的共现词的次数做为当前词语的向量
主要用于发现主题,解决词向量相近关系的表示。将共现矩阵行(列)作为词向量
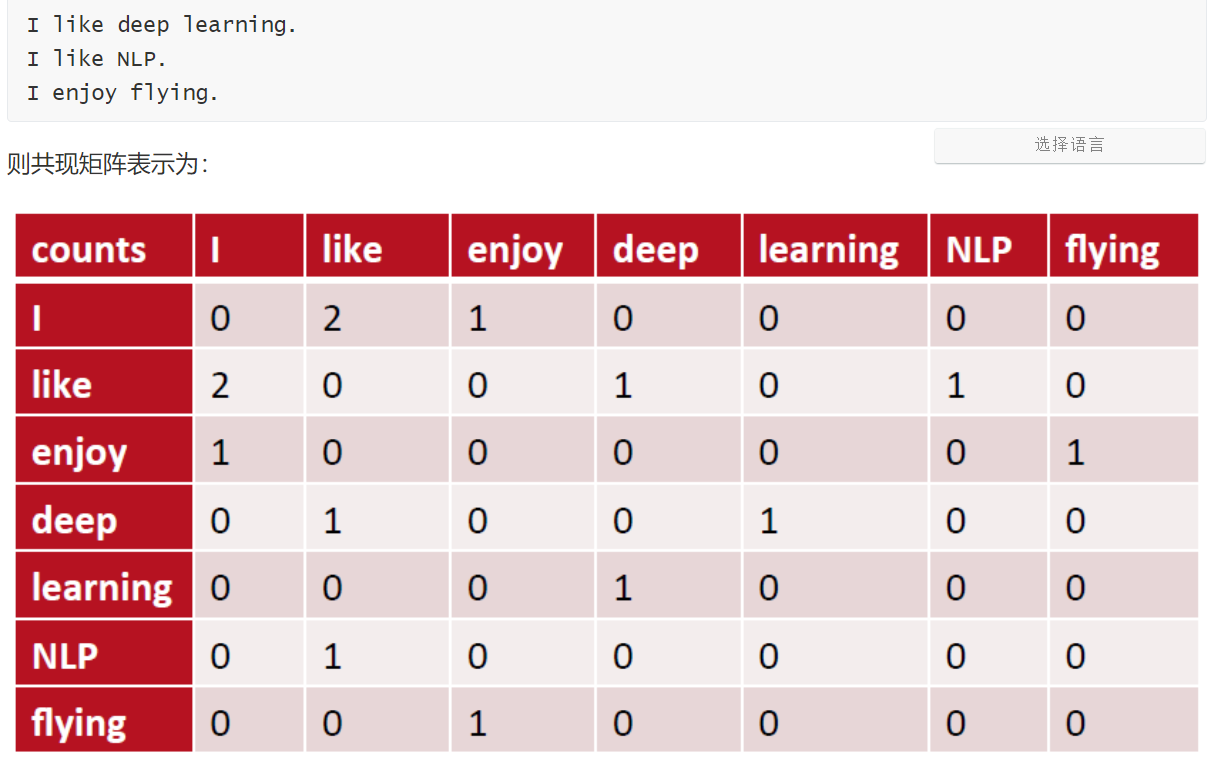
共现矩阵的不足
面临稀疏性问题、向量维数随着词典大小线性增长
解决:SVD、PCA降维,但是计算量大
5、随机游走-Random walk(RW)
5.1 概述
类似于布朗运动,是布朗运动的理想状态,任何无规则行走所带的守恒量都各自对应着一个扩散运输定律。
每过一个单位时间,游走者从x出发以固定概率随机移动一个单位。

