
- 1期望薪资22k,三年go好未来5轮面试经历_好未来客户端面试
- 2都2024了,还在纠结图片识别?fastapi+streamlit+langchain给你答案!_streamlit fastapi
- 3Flutter 2024 产品路线图正式公布,2024年Android开发学习路线_安卓开发roadmap
- 4Apple watch 开发指南(4) 配置你的xcode_xcode运行调试真机手表
- 5gitee(码云)和gitHub的区别_码云和github的区别
- 6Qwen-14B-Chat 非量化微调_qwen4b部署要求
- 7AI绘画工具介绍:解锁创意的新工具
- 8Jdon框架(JdonFramework)应用系统
- 9SQL server 错误代码对照表_1051 已将停止控制发送给与其他运行服务相关的服务
- 10企业员工人事管理系统(数据库课设)_数据库物理结构设计公司人事管理
阅读笔记--NLP面试基础知识总结_nlp面试0基础
赞
踩
如果我可以把今世的记忆带到以后,我会告诉我下一世的继任者去学数学。但是他可能又是一个不愿意学习的小傻瓜,或许三年级的时候还是会考各种0分。是呀,0分也是回忆,那时怎么会晓得走到现在,今后又晓得会去往何处。但是…,谁又会到全局最优解呢?我在这里,我不知道人生接下来会给我怎样的惊吓和惊喜,我现在处在的地方可能就是局部最优解吧!
一、深度学习和机器学习的区别
- 数据相关性: 深度学习与传统机器学习最重要的区别是,随着数据量的增加,其性能也随之提高。当数据很小的时候,深度学习算法并不能很好地执行,这是因为深度学习算法需要大量的数据才能完全理解它。
- 硬件支持:深度学习需要强有力的GPU或者TPU支持
- 特征工程:在机器学习中,大多数应用的特征需要由专家识别,然后根据域和数据类型手工编码。但是深度学习一般是自动抽取特征
- 执行时间:深度学习模型的执行时间很长,但是机器学习一般较短
- 可解释性:深度学习的可解释性比较差。
二、基本概念
什么是分词(Tokenization)?
什么是序列标注?
所谓的序列标注就是对输入的文本序列中的每个元素打上标签集合中的标签。例如输入的一个序列如下:
X
=
x
1
,
x
2
,
.
.
.
,
x
n
X = {x_{1}, x_{2}, ..., x_{n}}
X=x1,x2,...,xn
那么经过序列标注后每个元素对应的标签如下:
Y
=
y
1
,
y
2
,
.
.
.
,
y
n
Y = {y_{1}, y_{2}, ..., y_{n}}
Y=y1,y2,...,yn
所以,其本质上是对线性序列中每个元素根据上下文内容进行分类的问题。一般情况下,对于NLP任务来说,线性序列就是输入的文本,往往可以把一个汉字看做线性序列的一个元素,而不同任务其标签集合代表的含义可能不太相同,但是相同的问题都是:如何根据汉字的上下文给汉字打上一个合适的标签(无论是分词,还是词性标注,或者是命名实体识别,道理都是想通的)
什么是end-to-end
三、表示学习
词向量是自然语言处理任务中非常重要的一个部分,词向量的表征能力很大程度上影响了自然语言处理模型的效果。如论文中所述,词向量需要解决两个问题:
(1). 词使用的复杂特性,如句法和语法。
(2). 如何在具体的语境下使用词,比如多义词的问题。
传统的词向量比如word2vec能够解决第一类问题,但是无法解决第二类问题。比如:“12号地铁线马上就要开通了,以后我们出行就更加方便了。”和“你什么时候方便,我们一起吃个饭。”这两个句子中的“方便”用word2vec学习到的词向量就无法区分,因为word2vec学习的是一个固定的词向量,它只能用同一个词向量来表示一个词不同的语义,而elmo就能处理这种多义词的问题。
one hot 模型
词袋模型
缺点:稀疏;无序;纬度爆炸;每个向量都正交,相当于每个词都是没有关系的。
1.word2vec
在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的语言模型(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
1.1 CBoW模型
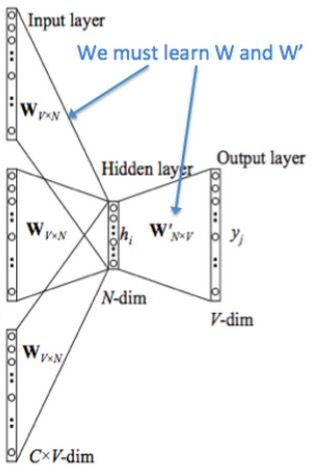
CBoW模型等价于一个词袋模型的向量乘以一个Embedding矩阵,从而得到一个连续的embedding向量。
CBoW前向计算过程
词向量最简单的方式是one-hot方式。one-hot就是从很大的词库corpus里选V个频率最高的词(忽略其他的) ,V一般比较大,比如V=10W,固定这些词的顺序,然后每个词就可以用一个V维的稀疏向量表示了,这个向量只有一个位置的元素是1,其他位置的元素都是0。在上图中,
- Input layer (输入层):是上下文单词的one hot。假设单词向量空间的维度为V,即整个词库corpus大小为V,上下文单词窗口的大小为C。
- 假设最终词向量的维度大小为N,则图中的权值共享矩阵为W。W的大小为 V ∗ N V * N V∗N,并且初始化。
- 假设语料中有一句话"我爱你"。如果我们现在关注"爱"这个词,令C=2,则其上下文为"我",“你”。模型把"我" "你"的onehot形式作为输入。易知其大小为 1 ∗ V 1*V 1∗V。C 个 1 ∗ V 1*V 1∗V大小的向量分别跟同一个 V ∗ N V * N V∗N 大小的权值共享矩阵W相乘,得到的是C个 1 ∗ N 1*N 1∗N 大小的隐层hidden layer。
- C 个 1 ∗ N 1*N 1∗N 大小的hidden layer取平均,得到一个 1 ∗ N 1*N 1∗N 大小的向量,即图中的Hidden layer。
- 输出权重矩阵 W ′ W^{'} W′ 为 N ∗ V N*V N∗V,并进行相应的初始化工作。
- 将得到的Hidden layer向量 1 ∗ N 1*N 1∗N 与W’相乘,并且用softmax处理,得到 $ 1*V $ 的向量,此向量的每一维代表corpus中的一个单词。概率中最大的index所代表的单词为预测出的中间词。
- 与groud truth中的one hot比较,求loss function的的极小值。
具体计算过程
- 从input -> hidden: W T ∗ x W^{T} ∗x WT∗x, W W W为 V ∗ N V*N V∗N矩阵, x x x为 V ∗ 1 V * 1 V∗1向量,最终隐层的结果为 N ∗ 1 N * 1 N∗1
- 从hidden -> output: x T ∗ W ′ x^T∗W^′ xT∗W′,其中 x x x为 N ∗ 1 N * 1 N∗1向量, W ′ W^{'} W′ 为 V ∗ N V * N V∗N,最终结果为 1 ∗ V 1 * V 1∗V

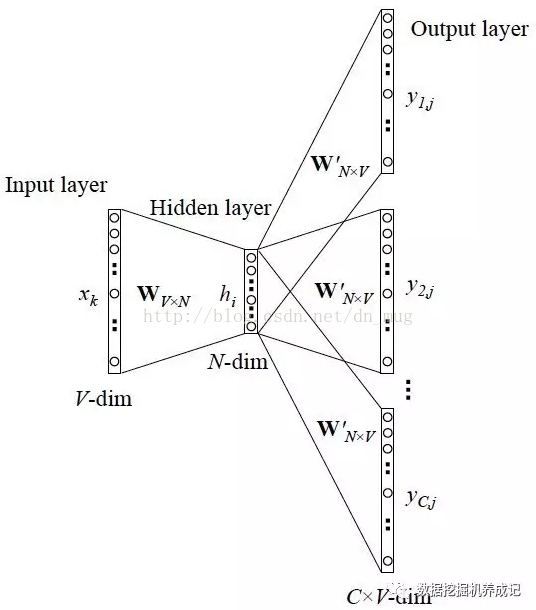
1.2 Skip-gram模型
1.3 Tricks(层次softmax和负采样)
因为权值矩阵是一个非常大的矩阵,比如词典是10000,期望的词向量维度是300,那么这个矩阵就有300万参数,而这对于最后一层的softmax和反向传播都会带来极低的效率。因此以下两个技巧都是为了提升模型的速度。
1. 层softmax技巧(hierarchical softmax)
解释一: 最后预测输出向量时候,大小是1*V的向量,本质上是个多分类的问题。通过hierarchical softmax的技巧,把V分类的问题变成了log(V)次二分类。
解释二: 层次softmax的技巧是来对需要训练的参数的数目进行降低。所谓层次softmax实际上是在构建一个哈夫曼树,这里的哈夫曼树具体来说就是对于词频较高的词汇,它的树的深度就较浅,对于词频较低的单词的它的树深度就较大。
总结: 层次softmax就是利用一颗哈夫曼树来简化原来的softmax的计算量。具体来说就是对词频较高的单词,他在哈夫曼树上的位置就比较浅,而词频较低的位置就在树上的位置比较深。
2. 负采样(negative sampling)
解释一: 本质上是对训练集进行了采样,从而减小了训练集的大小。每个词
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

