
- 1编程学单词:delta(希腊字母Δ/δ),差值表示
- 2防火墙的安全策略_防火墙没做策略无法访问
- 3修改域管理员密码
- 4(18-4-06)Agents(智能代理): ReAct代理_react agent
- 5【Java-TesseractOCR】通过Java实现OCR_tesseract ocr java
- 6FPGA入门教程之Quartus软件新建工程步骤(超详细)_quartus新建工程
- 7【Linux】ss命令详解
- 8微分方程(Differential Equation)_differential equation in normal form
- 9Kafka报错org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
- 10CrossOver软件2023官方破解版本下载
Pytorch学习(八)——kaggle泰坦尼克数据集_titanic dataset
赞
踩
数据集来源:Titanic - Machine Learning from Disaster | Kaggle
参考学习:kaggle泰坦尼克号数据集——数据分析全流程 - 知乎 (zhihu.com)
目录
1.数据处理
1.1数据集导入查看数据量和缺失情况
train_data: 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object
test_data: 0 PassengerId 418 non-null int64 1 Pclass 418 non-null int64 2 Name 418 non-null object 3 Sex 418 non-null object 4 Age 332 non-null float64 5 SibSp 418 non-null int64 6 Parch 418 non-null int64 7 Ticket 418 non-null object 8 Fare 417 non-null float64 9 Cabin 91 non-null object 10 Embarked 418 non-null object
1.2数据缺失处理
可以看出Age、Cabin、Fare和Embarked数据存在缺失。
Age:与存活与否有关系,需要考虑到,所以选择以平均值的方法将空缺的数据填补,也可以采用中位数、均值或者一些算法进行填补;
Cabin:船舱属性,缺失较为严重,所以不考虑这条因素;
Embarked:登船港口属性,仅仅缺失部分,所以直接将缺失的删除
Fare:票价属性,缺失部分,删除缺失部分
代码为:
- #年龄以平均值填补缺失部分
- data_train.loc[(data_train.Age.isnull()),'Age'] = data_train.Age.mean()
- data_test.loc[(data_test.Age.isnull()),'Age'] = data_test.Age.mean()
-
- #训练集登录港口缺失的样本因为较少,直接删除样本
- data_train = data_train.drop(data_train[data_train.Embarked.isnull()].index)
-
- #测试集Fare缺失样本为一个,同删除样本
- data_test = data_test.drop(data_test[data_test.Fare.isnull()].index)
1.3选择需要考虑的属性
因为Cabin缺失较为严重所以不考虑,Ticket也不考虑,kaggle泰坦尼克号数据集——数据分析全流程 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/342552186所以删除以下属性PassengerId、Name 、Ticket、 Cabin
https://zhuanlan.zhihu.com/p/342552186所以删除以下属性PassengerId、Name 、Ticket、 Cabin
代码为:
- data_train = data_train.drop(labels=['PassengerId','Name','Ticket','Cabin'],axis = 1)
- data_test = data_test.drop(labels=['PassengerId','Name','Ticket','Cabin'],axis = 1)
1.4数据类型的转换
数据中Sex和Embarked属性中数据类型为object,将数据转换方便后续模型训练
Sex中male改为1,female改为0
Embarked中S改为0,C改为1,Q改为2
代码:
- #将Sex 和Embarked 数据类型转换
- data_train['Sex'] = data_train.Sex.map(lambda x: 1 if x =='male' else 0)
- data_test['Sex'] = data_test.Sex.map(lambda x: 1 if x =='male' else 0)
-
- data_train['Embarked'] = data_train.Embarked.map(lambda x: 0 if x == 'S' else 1 if x == 'C' else 2 )
- data_test['Embarked'] = data_test.Embarked.map(lambda x: 0 if x == 'S' else 1 if x == 'C' else 2 )
最后方便处理,将训练集中存活属性放到最后一列,导出新的表格保存
- data_train.insert(7,'Survived',data_train.pop('Survived'))
-
- outputpath_train = './data/train_after.csv'
- data_train.to_csv(outputpath_train,sep=',',index=False,header=False)
- outputpath_test = './data/test_after.csv'
- data_test.to_csv(outputpath_test,sep=',',index=False,header=False)
- #不保存索引、列表名
2.模型训练
代码与上一篇文章里基本一致Pytorch学习(八)——数据集加载_土名什么的比较好的博客-CSDN博客
2.1代码
- import numpy as np
- import torch
- from torch.utils.data import Dataset
- from torch.utils.data import DataLoader
- import matplotlib.pyplot as plt
-
- class TitanicDataset(Dataset):
- def __init__(self, filepath):
- xy = np.loadtxt(filepath, delimiter = ',',dtype = np.float32)
- self.len = xy.shape[0]
- self.x_data = torch.from_numpy(xy[:,:-1])
- self.y_data = torch.from_numpy(xy[:,[-1]])
-
- def __getitem__(self, index):
- return self.x_data[index],self.y_data[index]
- def __len__(self):
- return self.len
-
- dataset = TitanicDataset('train_after.csv')
- train_loader = DataLoader(dataset = dataset, batch_size=32, shuffle=True, num_workers=0)
-
- class Model(torch.nn.Module):
- def __init__(self):
- super(Model,self).__init__()
- self.linear1 = torch.nn.Linear(7,4)
- self.linear2 = torch.nn.Linear(4,2)
- self.linear3 = torch.nn.Linear(2,1)
- self.activate = torch.nn.Sigmoid()
- def forward(self, x):
- x = self.activate(self.linear1(x))
- x = self.activate(self.linear2(x))
- x = self.activate(self.linear3(x))
- return x
-
- model = Model()
- criterion = torch.nn.BCELoss(reduction='mean')#返回loss均值
- optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
-
- for epoch in range(100):
- for i,(inputs,labels) in enumerate(train_loader,0):
- y_pred = model(inputs)
- loss = criterion(y_pred,labels)
- print(epoch,i,loss.item())
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- #预测
- xt = np.loadtxt('test_after.csv', delimiter = ',',dtype = np.float32)
- x_test = torch.from_numpy(xt[:,:])
- y_test = model(x_test)
- y = y_test.data.numpy()
- plt.plot(y)
- plt.grid()
- plt.show()

2.2结果
训练结果loss范围在0.56~0.71
预测结果是存活概率均不过0.5(
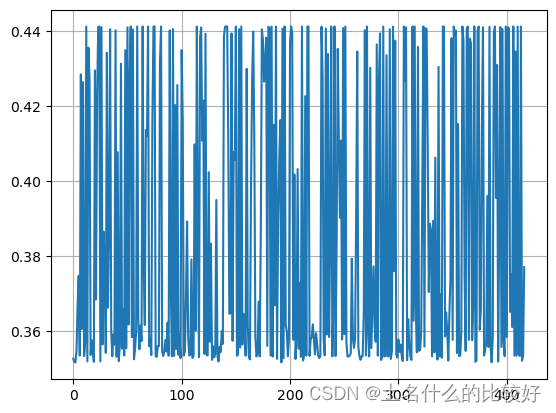
3.感悟
在处理数据时学习了很多处理方法及函数:df.loc、map函数、lambda函数等等,模型训练部分作为课后作业训练没有进行太多的优化处理,只是更加熟悉这一套流程:准备数据集—设计模型—构造loss、优化器—写训练周期

