
热门标签
热门文章
- 1Spark面试题
- 2【Android】Android Studio报错Unable to start the daemon process. The project uses Gradle 4.4 which is i_java gradle unable to start the
- 3人工智能法律搭建:从法律数据标准化到智能化处理
- 4网络安全单兵工具 -- Yakit的简介和安装
- 56.17--day002
- 6Java反序列化之CC1链分析_java反序列化cc1链分析
- 7Java后端开发面试题之MySQL上篇(含答案)_mysql后端面试题
- 8浅谈人工智能_人工智能可以探索人类未知的问题吗
- 9Docker 部署 PostgreSQL 主从_docker postgresql 主从
- 10Java课程实验报告实验二——一维数组_java一维数组实训报告
当前位置: article > 正文
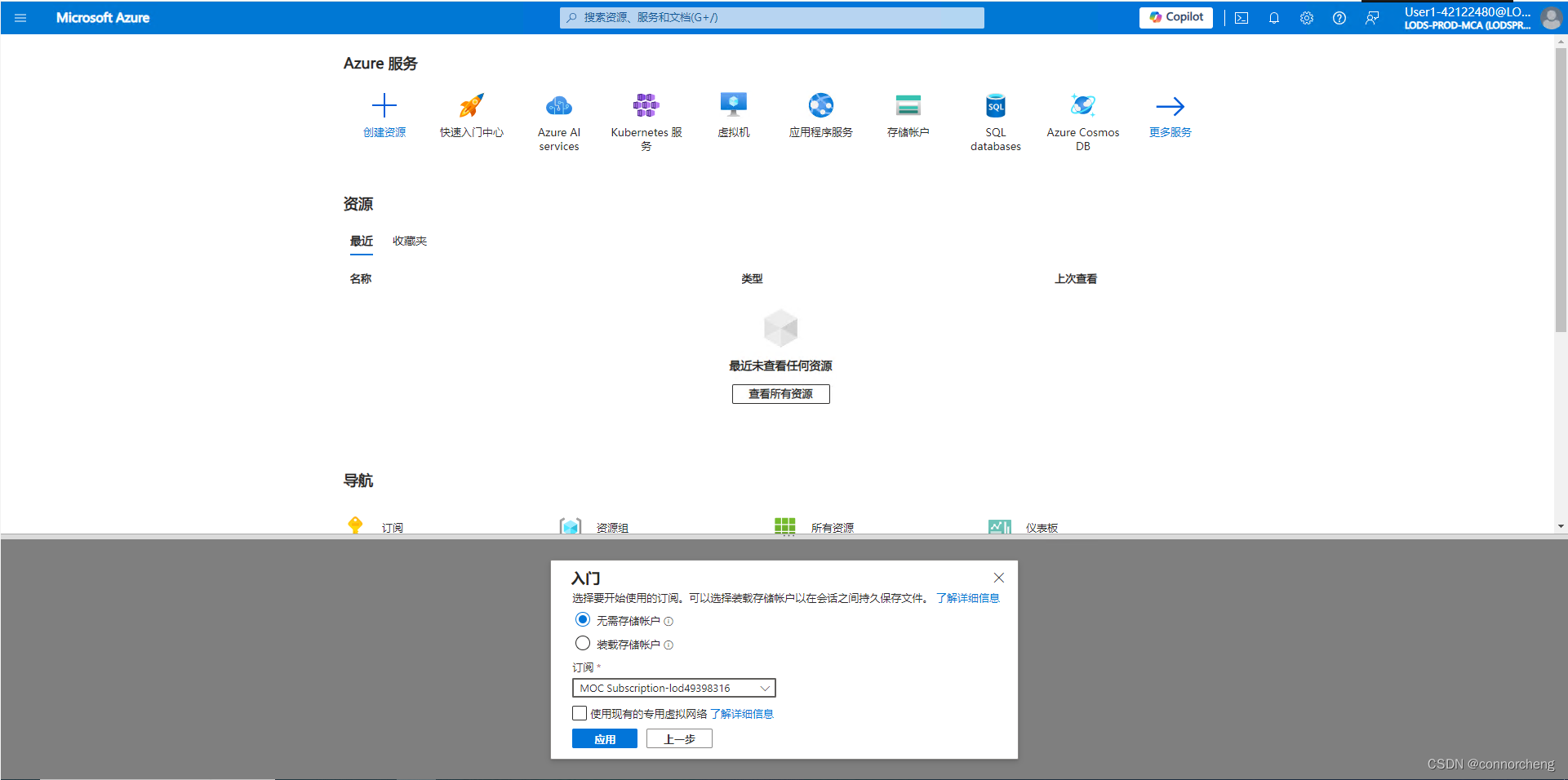
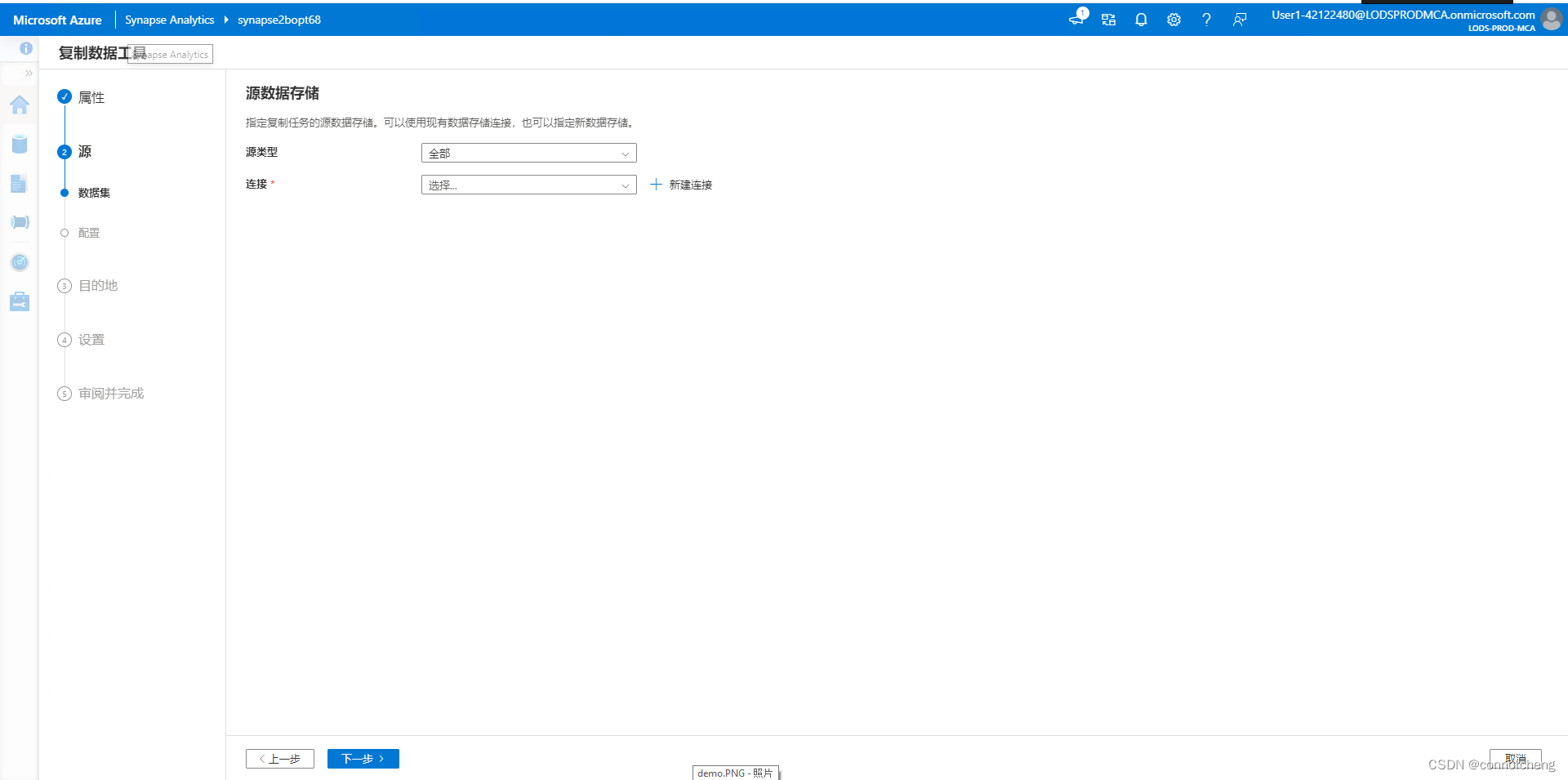
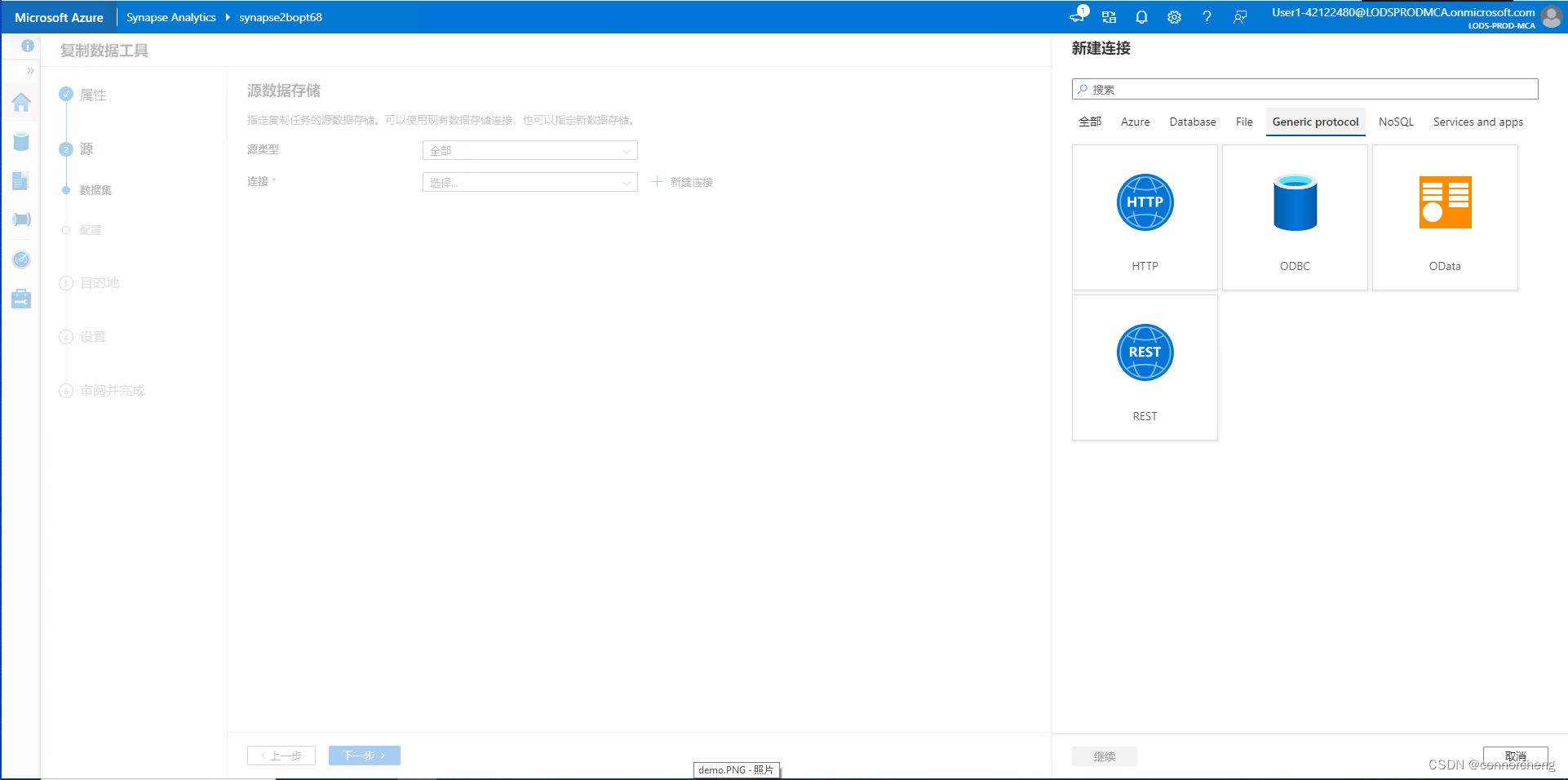
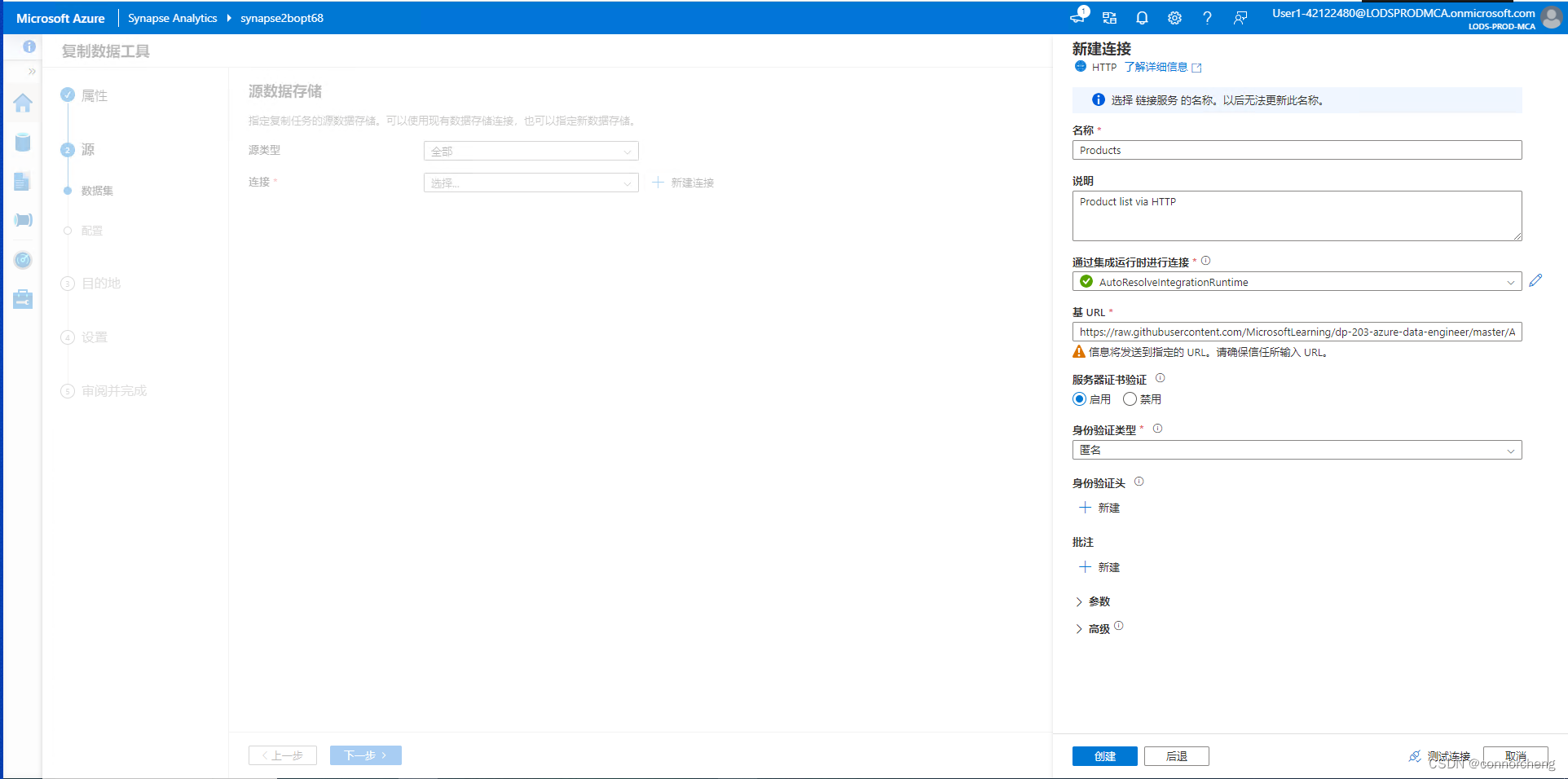
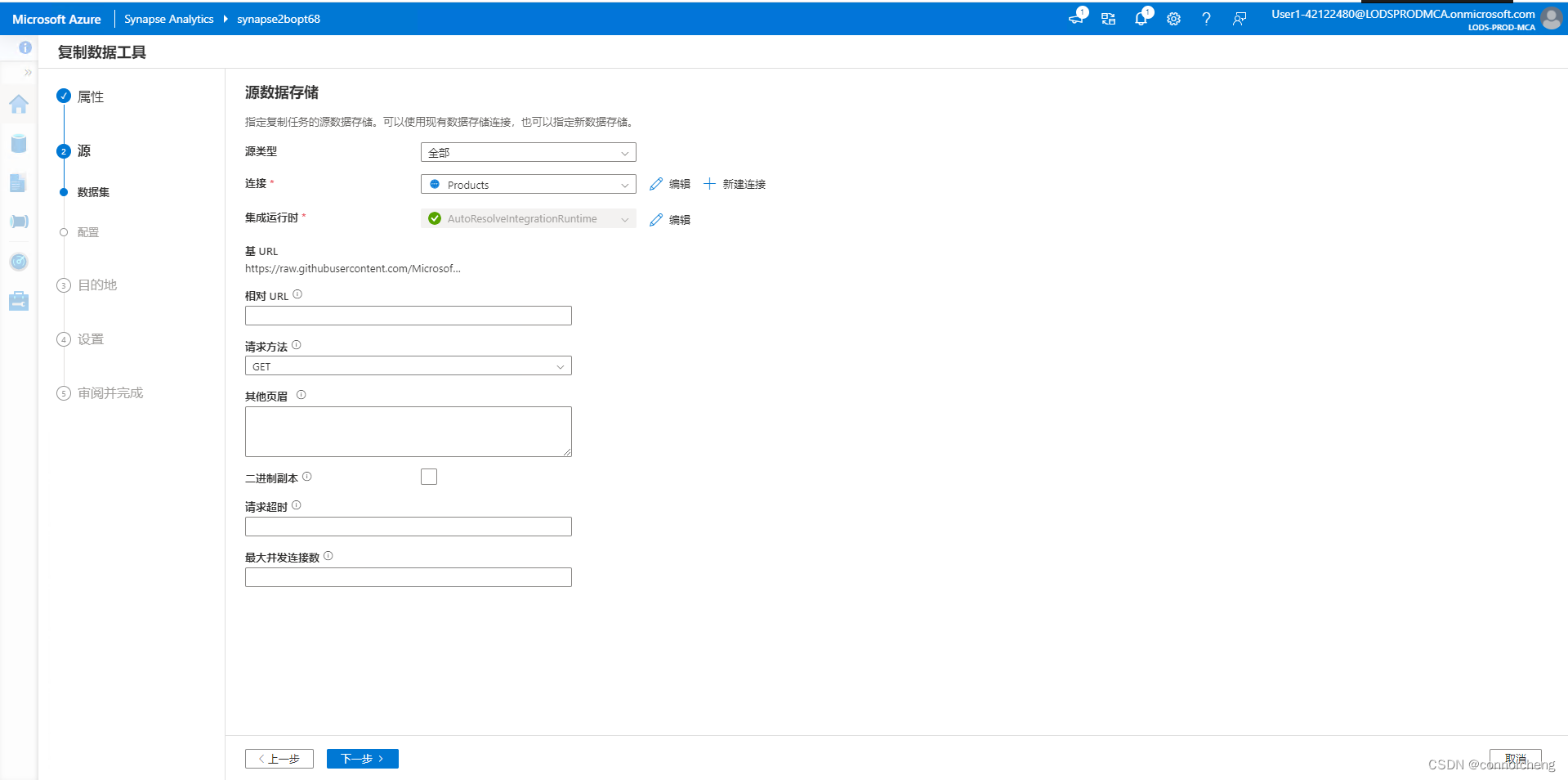
Explore Synapse
作者:从前慢现在也慢 | 2024-07-07 18:15:45
赞
踩
Explore Synapse
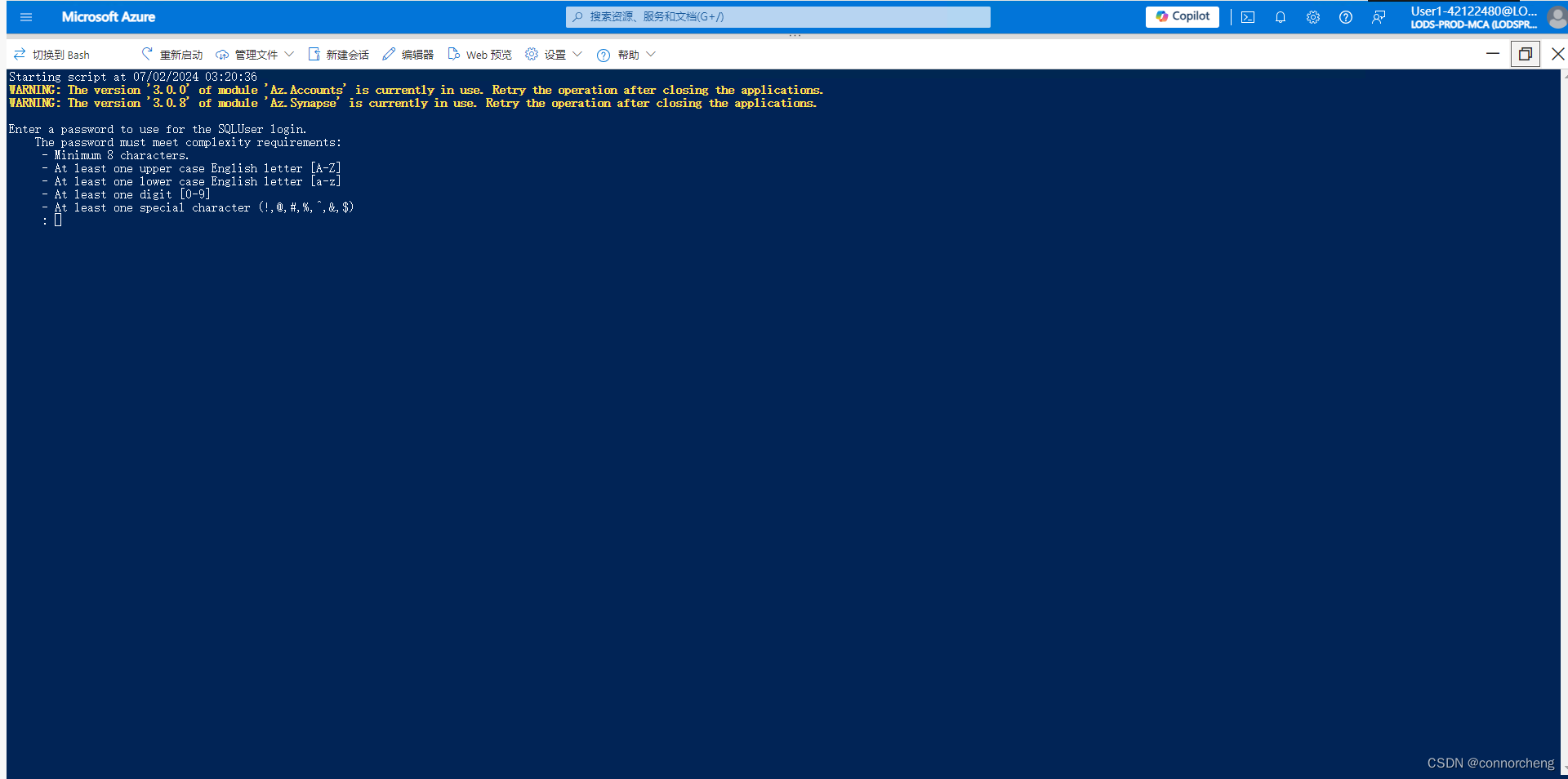
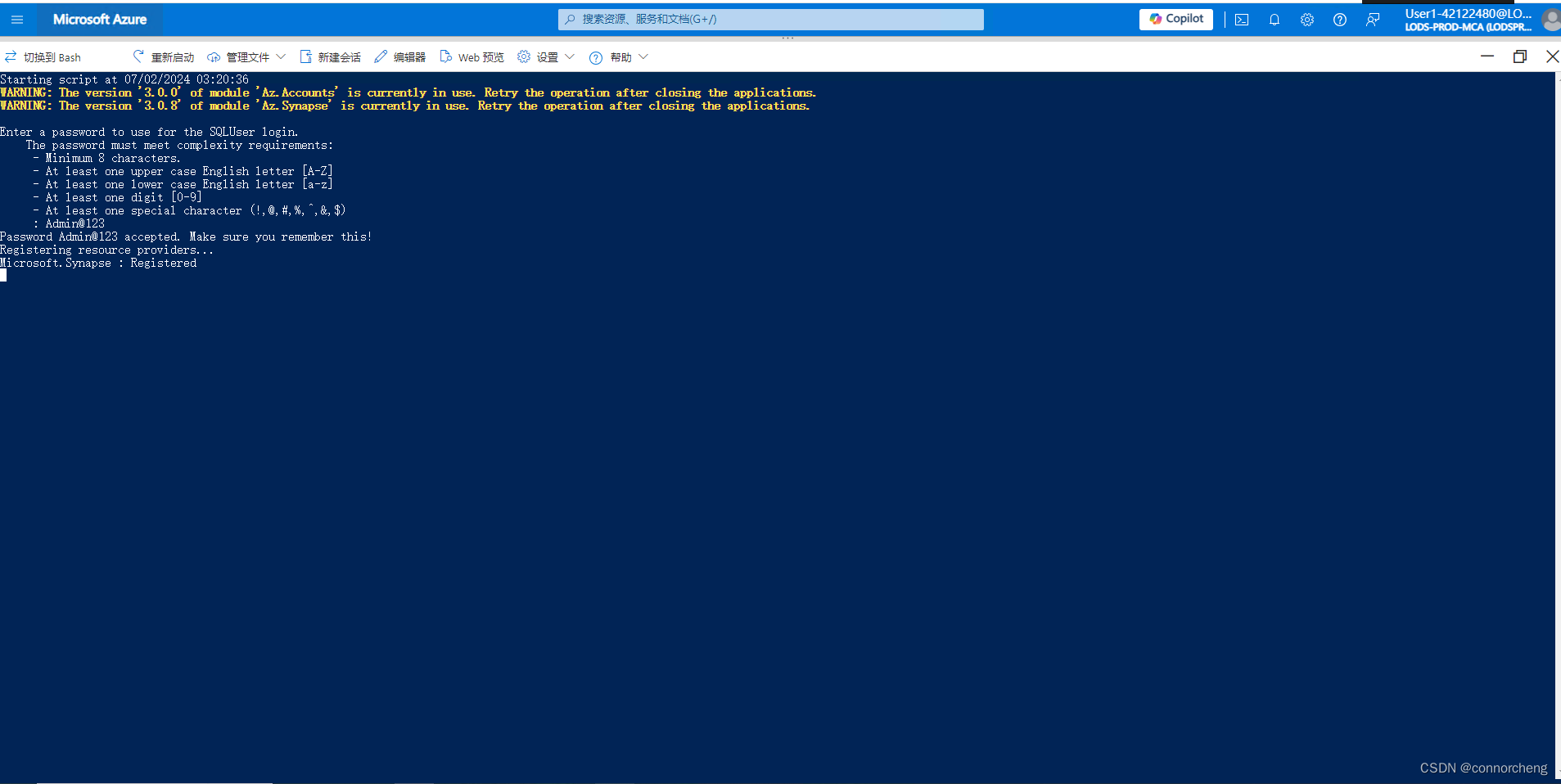
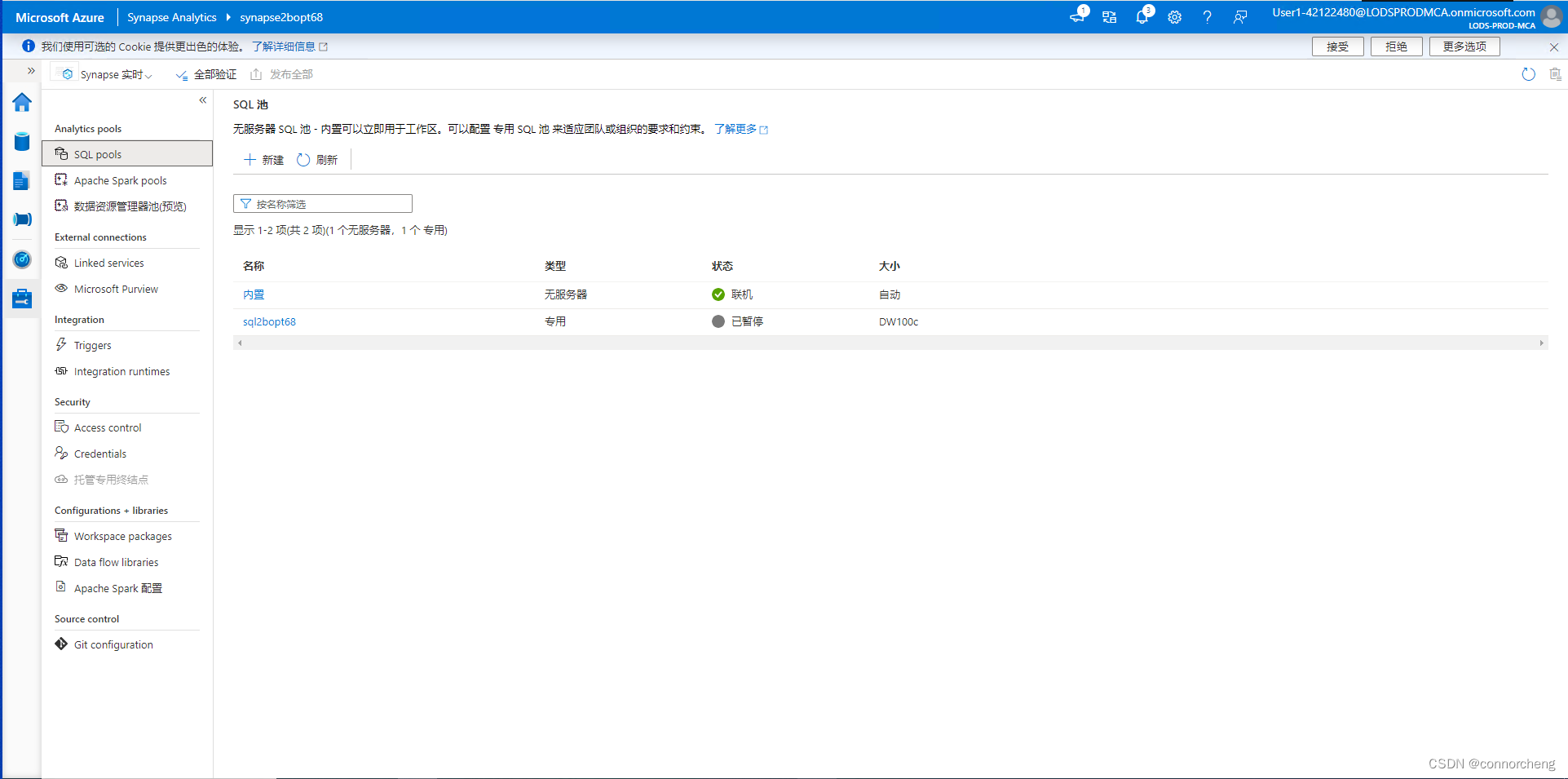
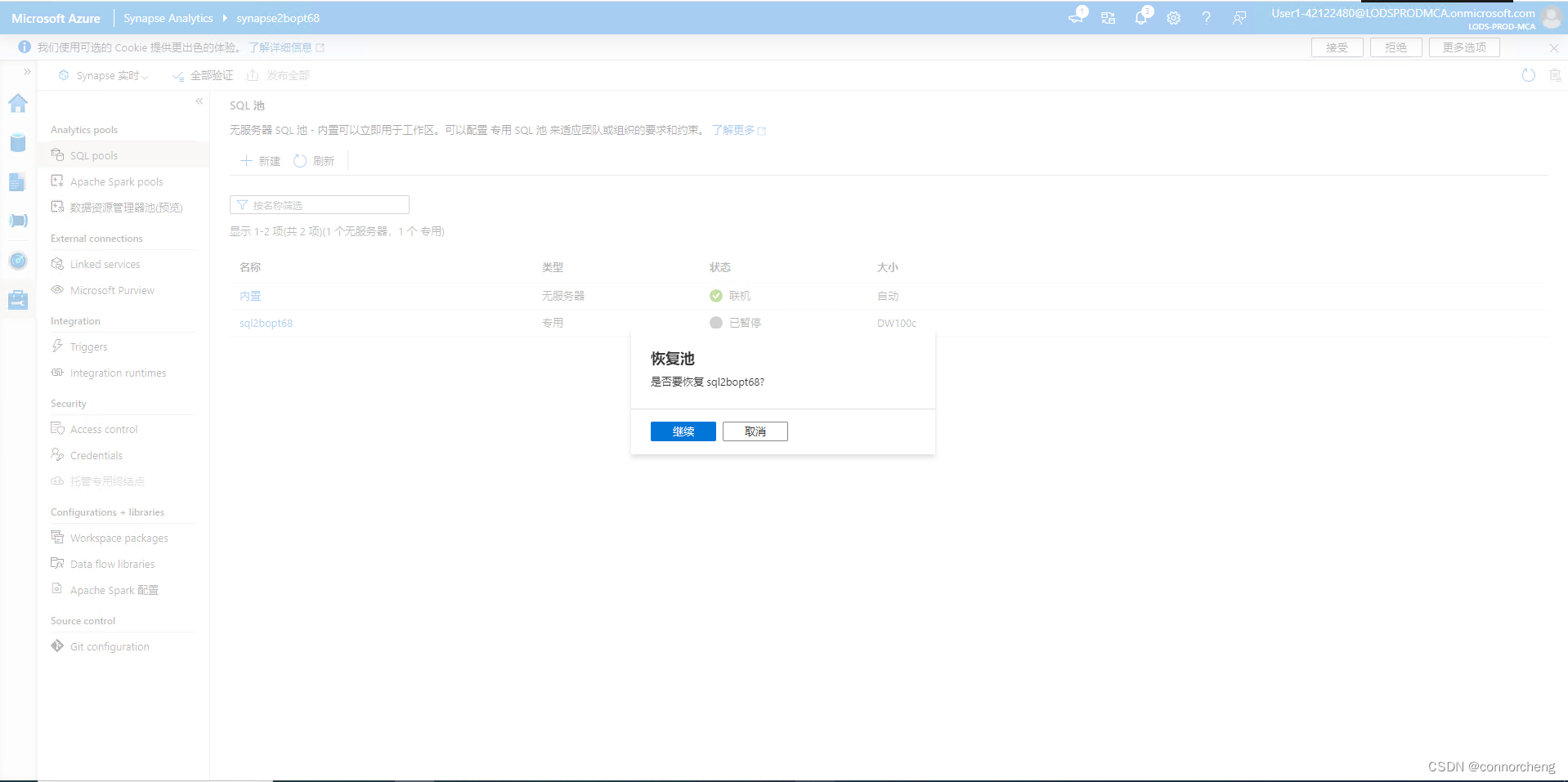
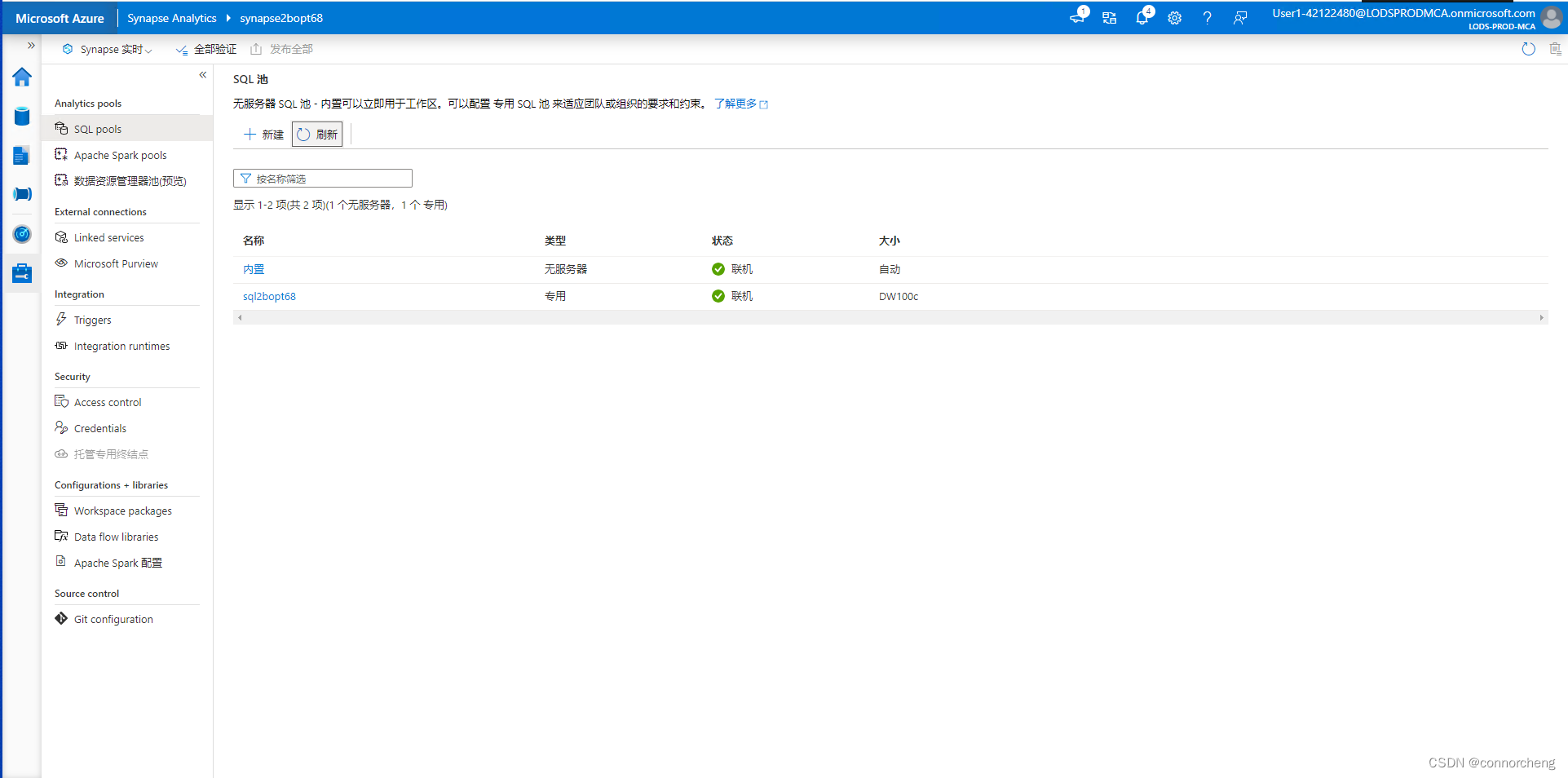
rm -r dp-203 -f
git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203

cd dp-203/Allfiles/labs/01
./setup.ps1
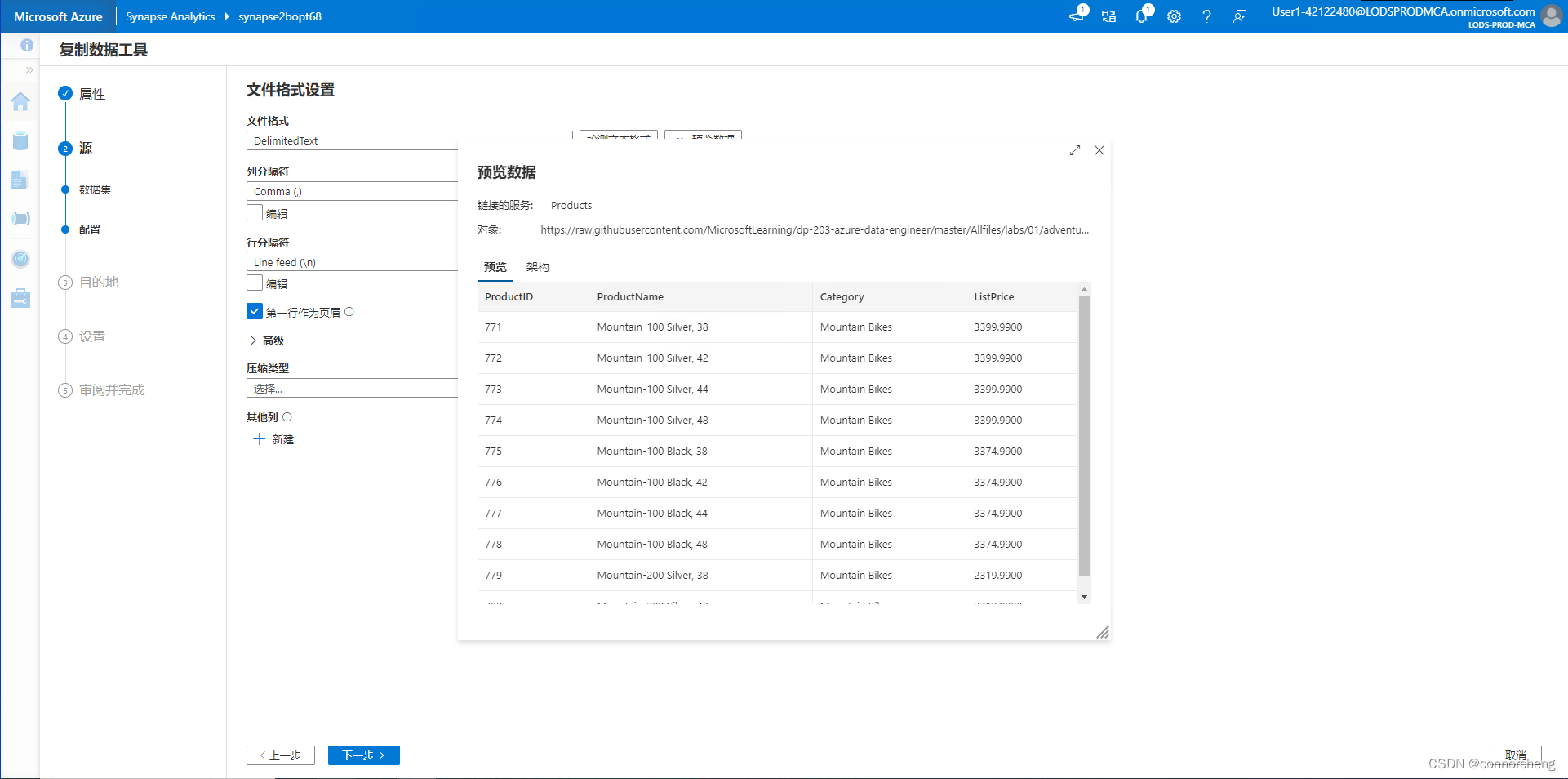

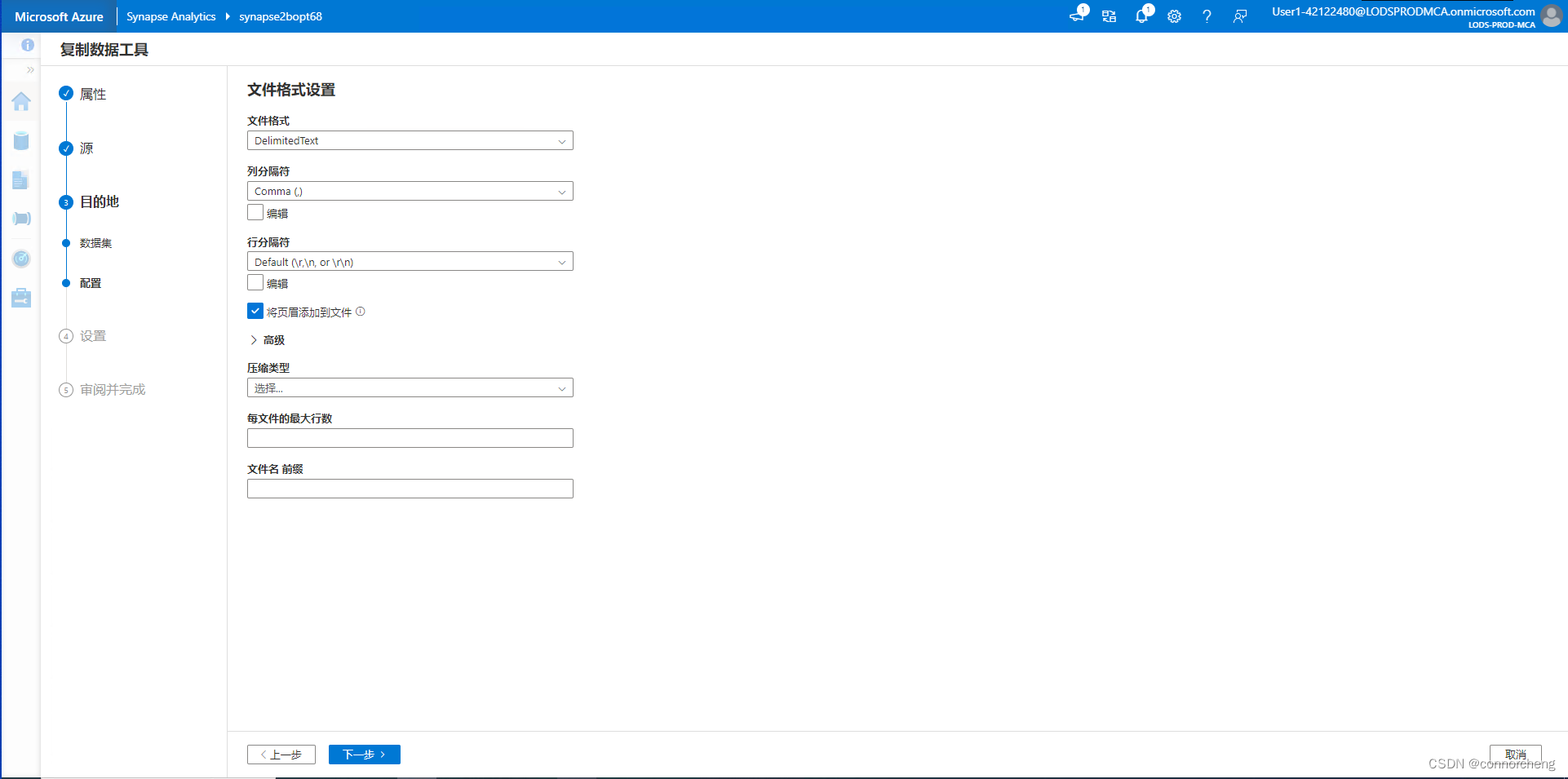
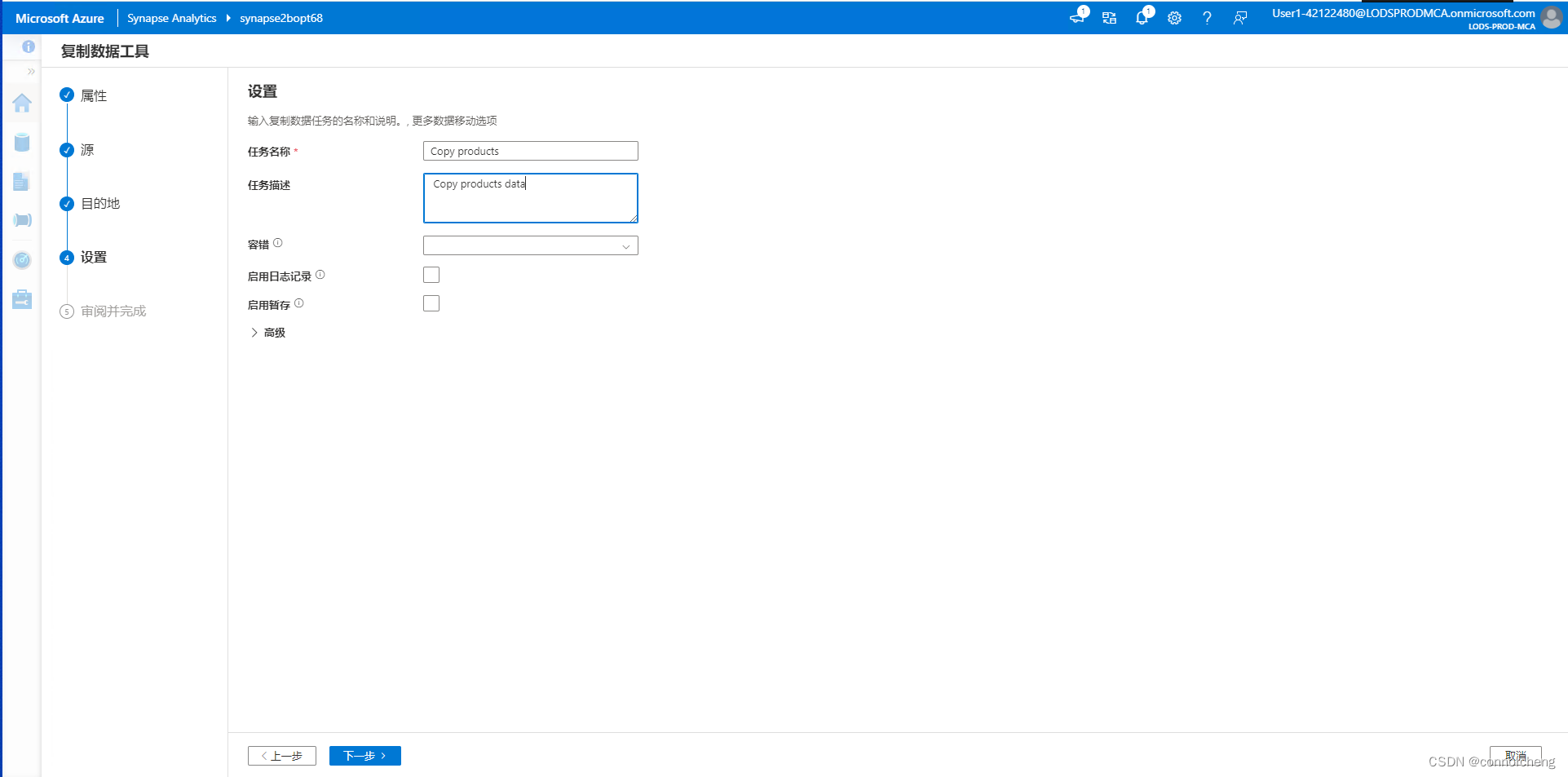
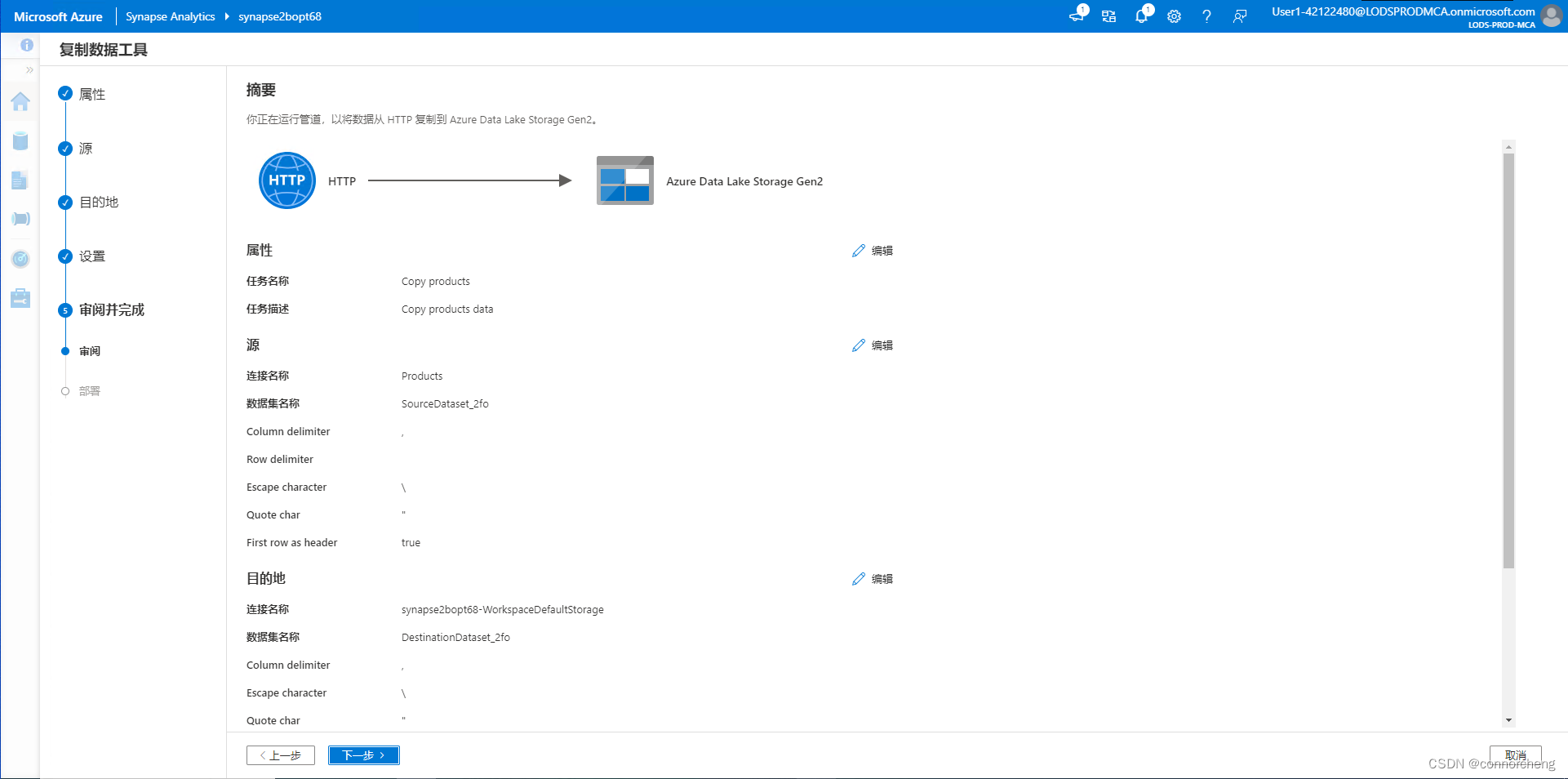
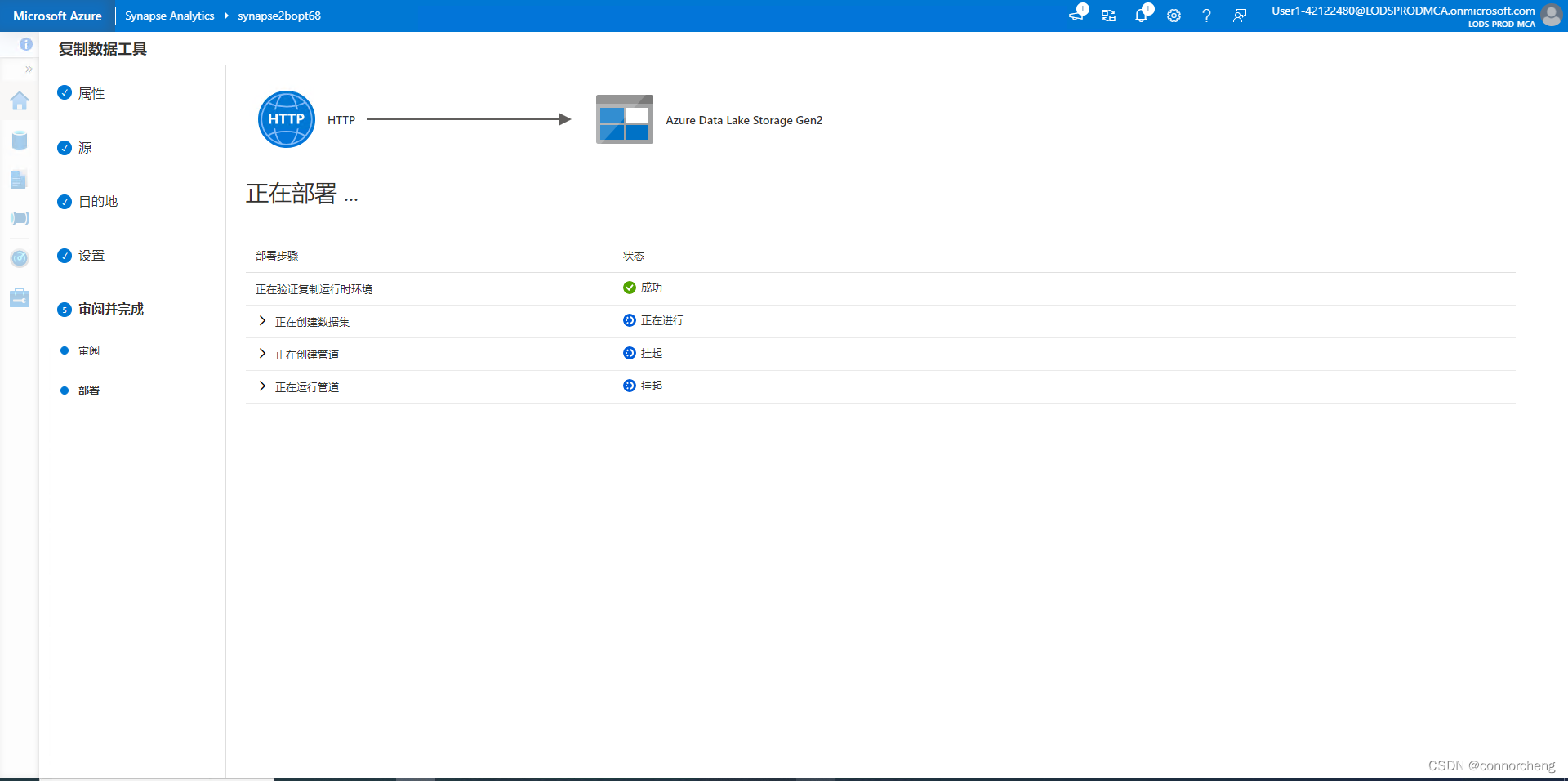
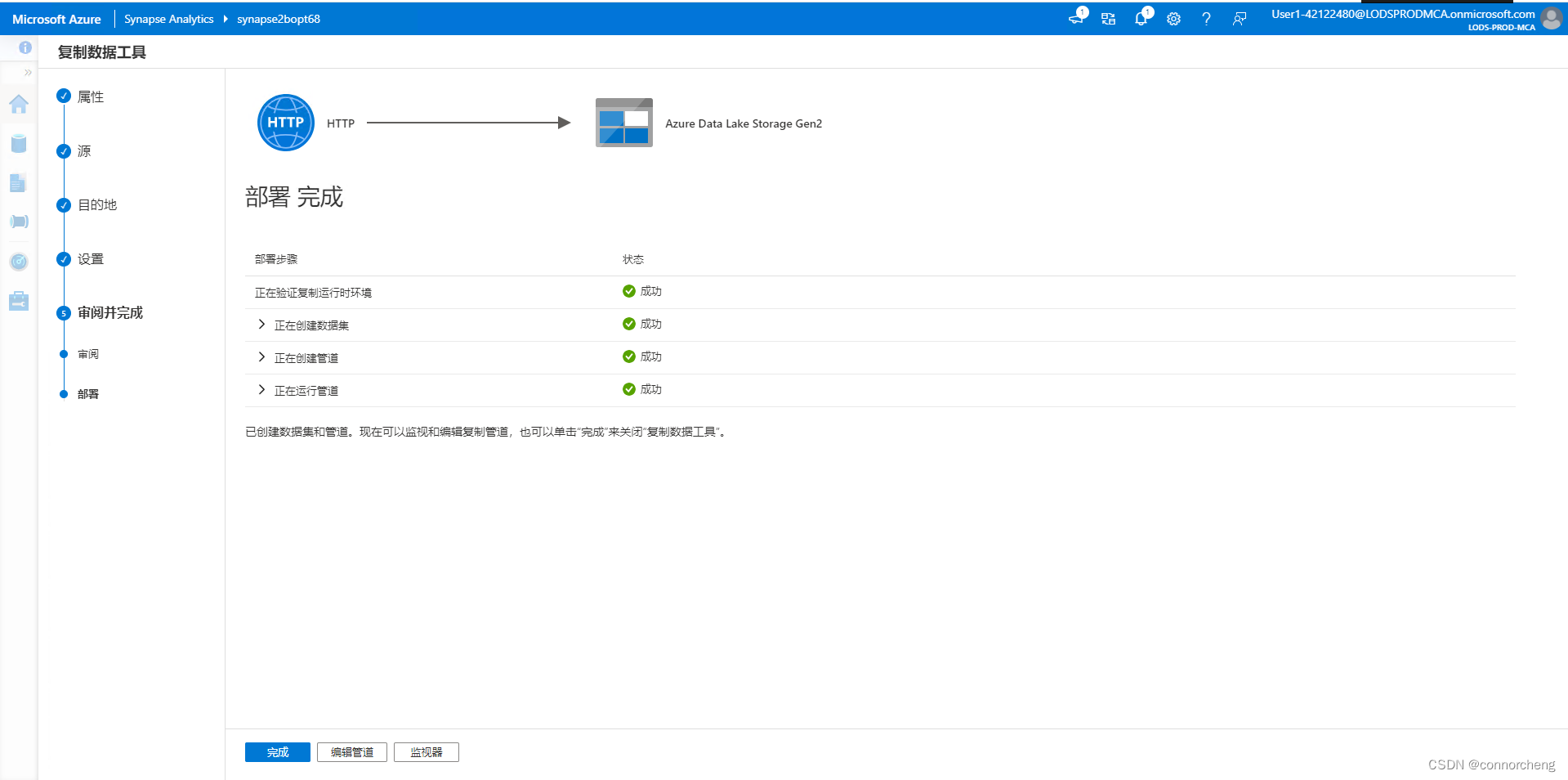
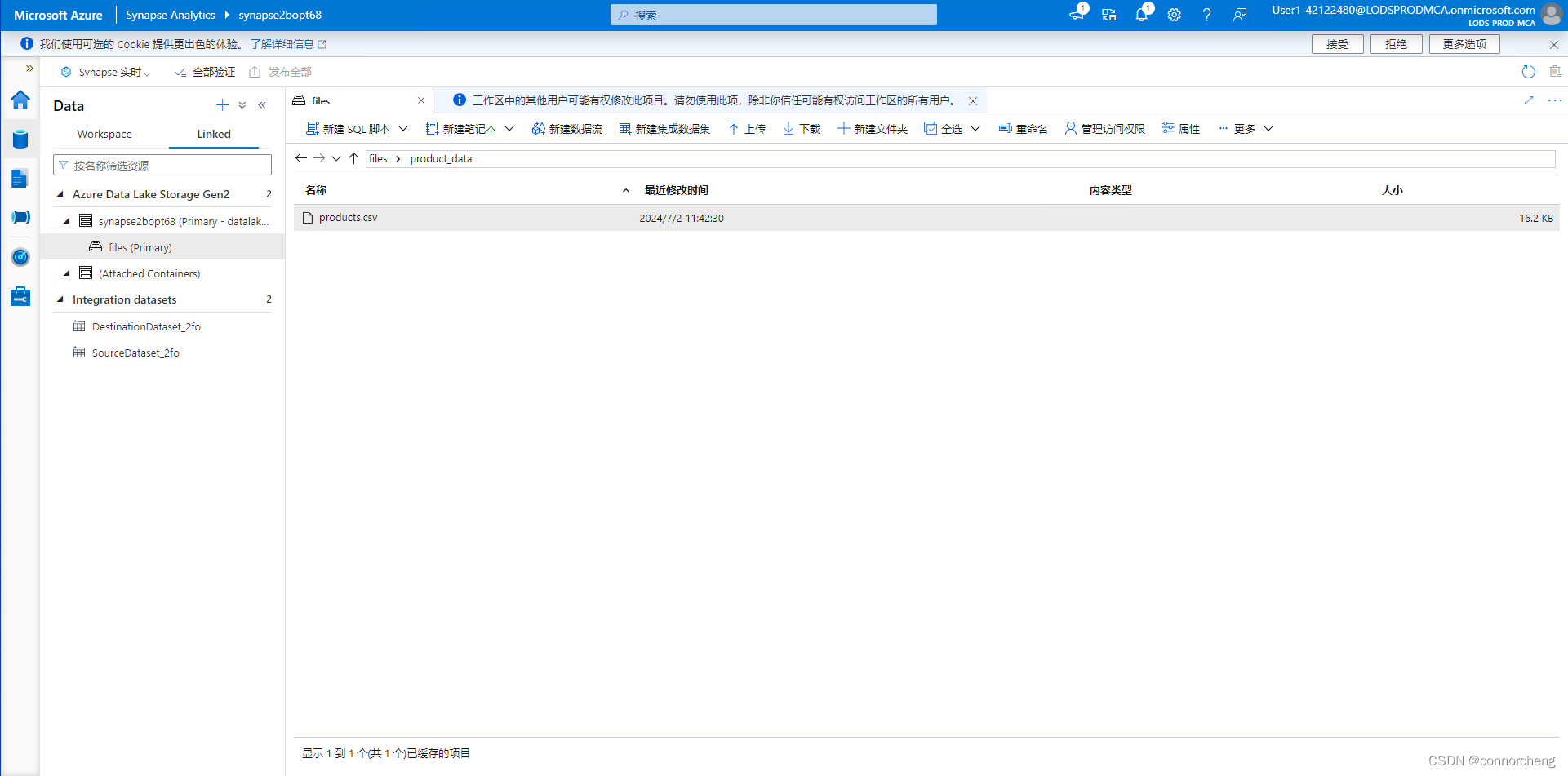
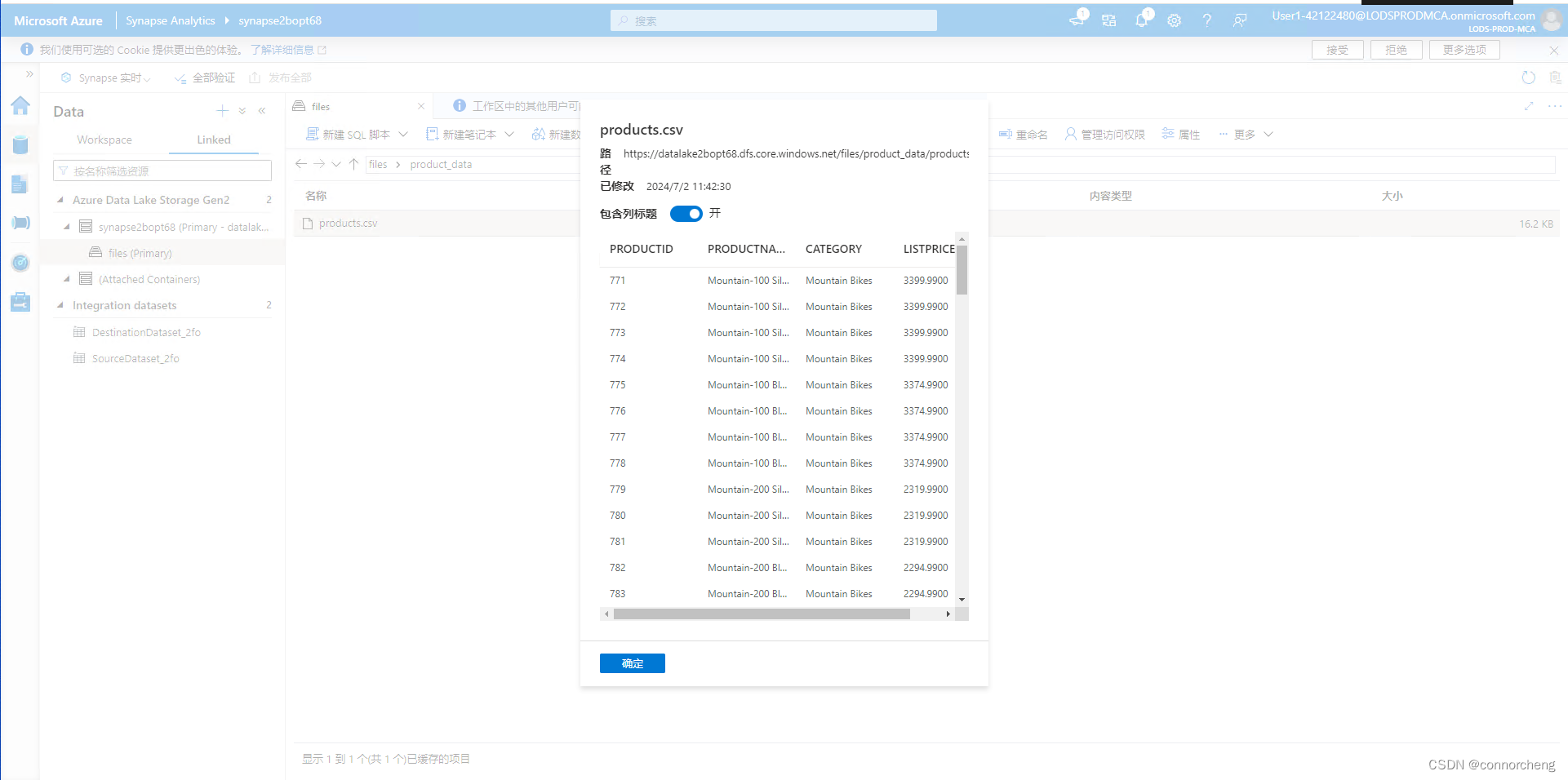
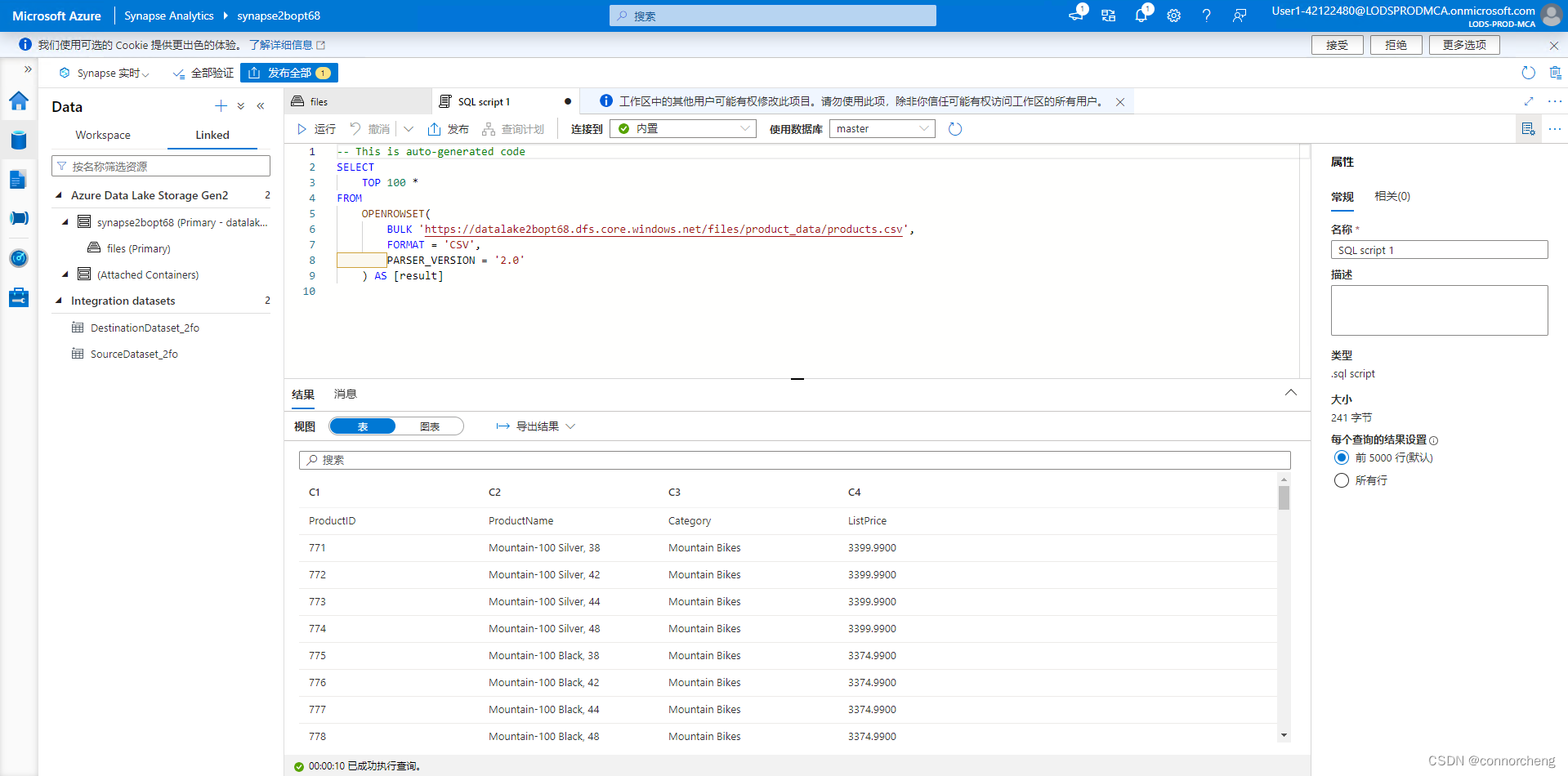
- -- This is auto-generated code
- SELECT
- TOP 100 *
- FROM
- OPENROWSET(
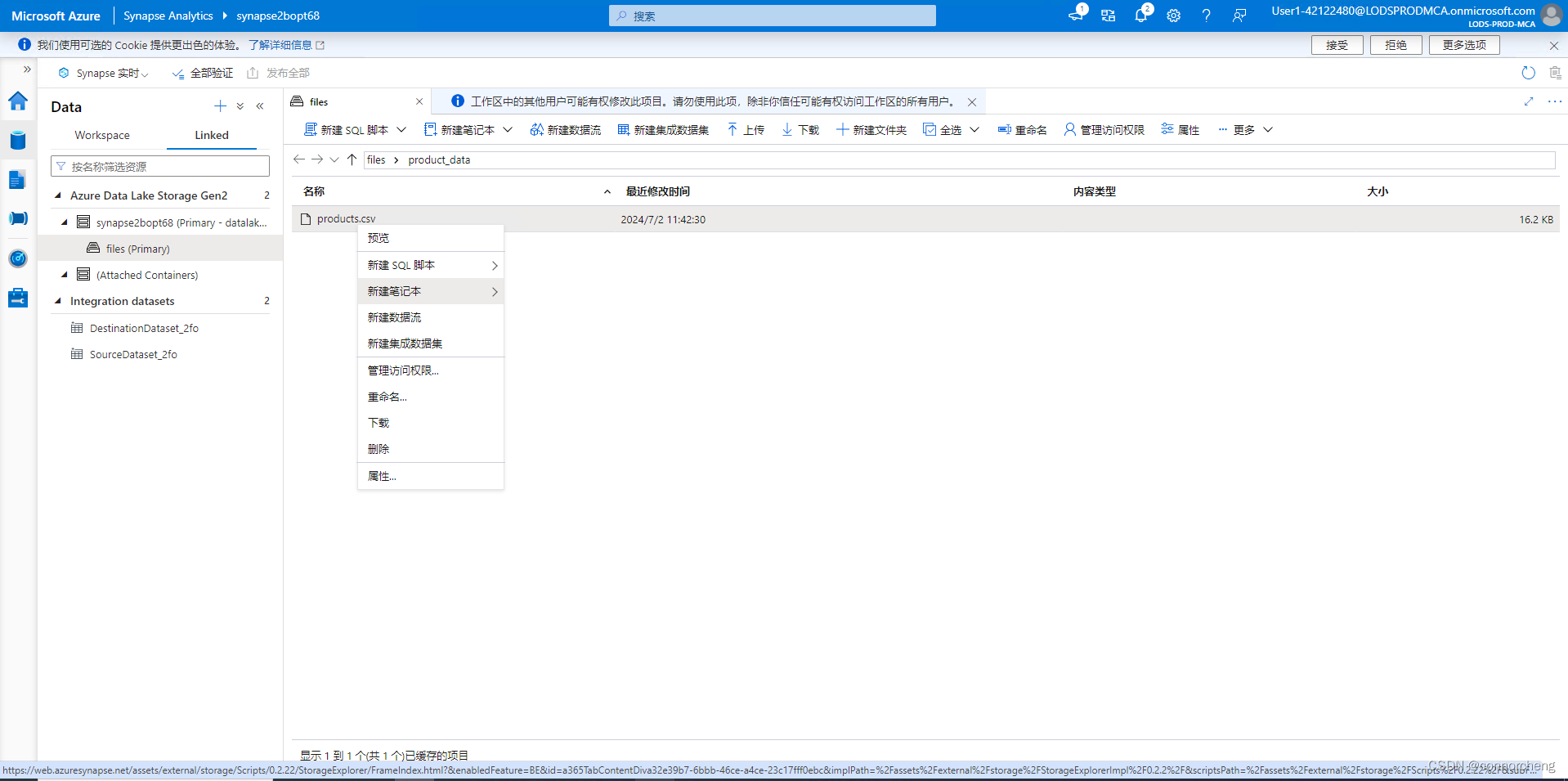
- BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
- FORMAT = 'CSV',
- PARSER_VERSION='2.0'
- ) AS [result]
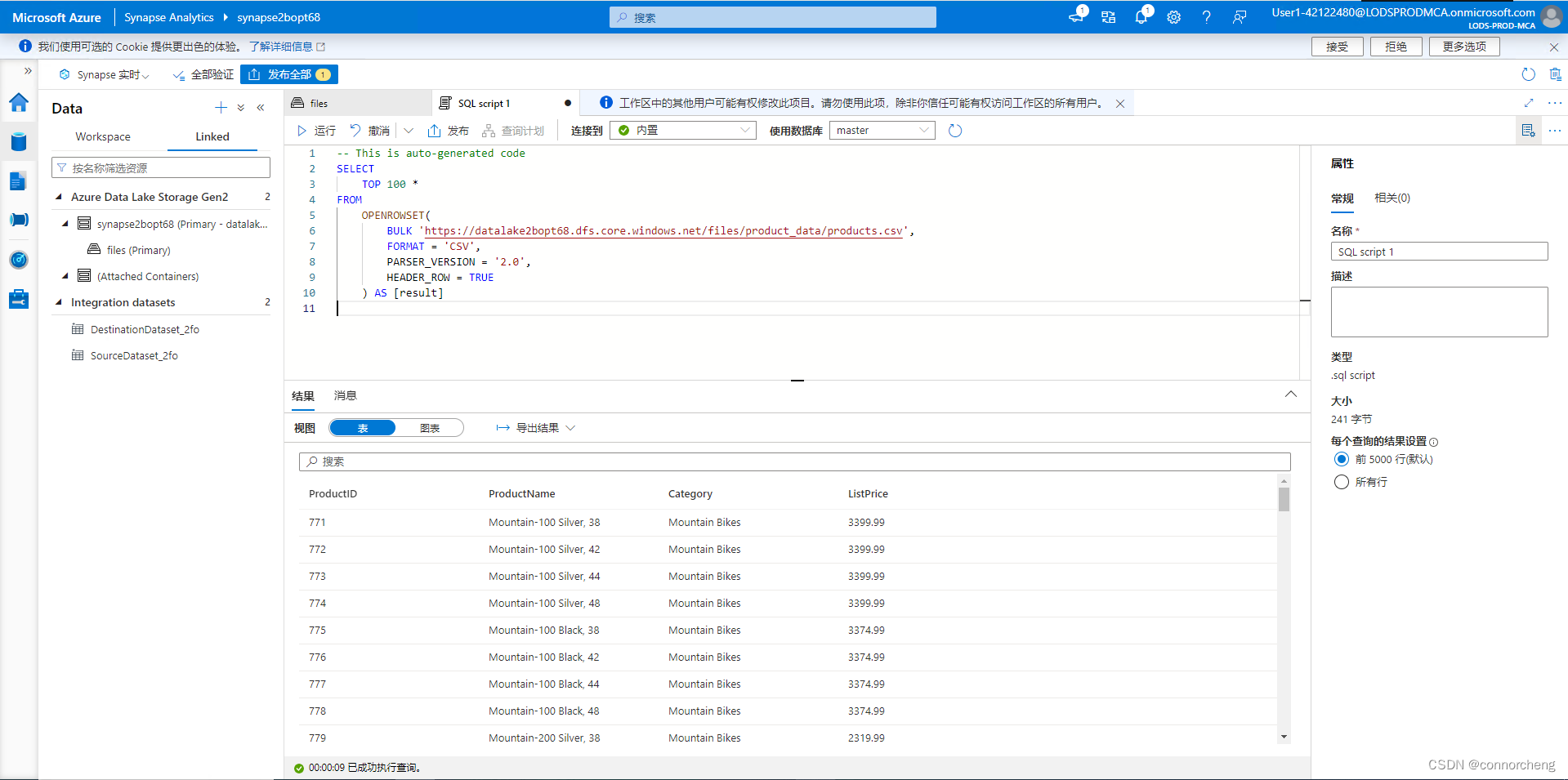
- SELECT
- TOP 100 *
- FROM
- OPENROWSET(
- BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
- FORMAT = 'CSV',
- PARSER_VERSION='2.0',
- HEADER_ROW = TRUE
- ) AS [result]
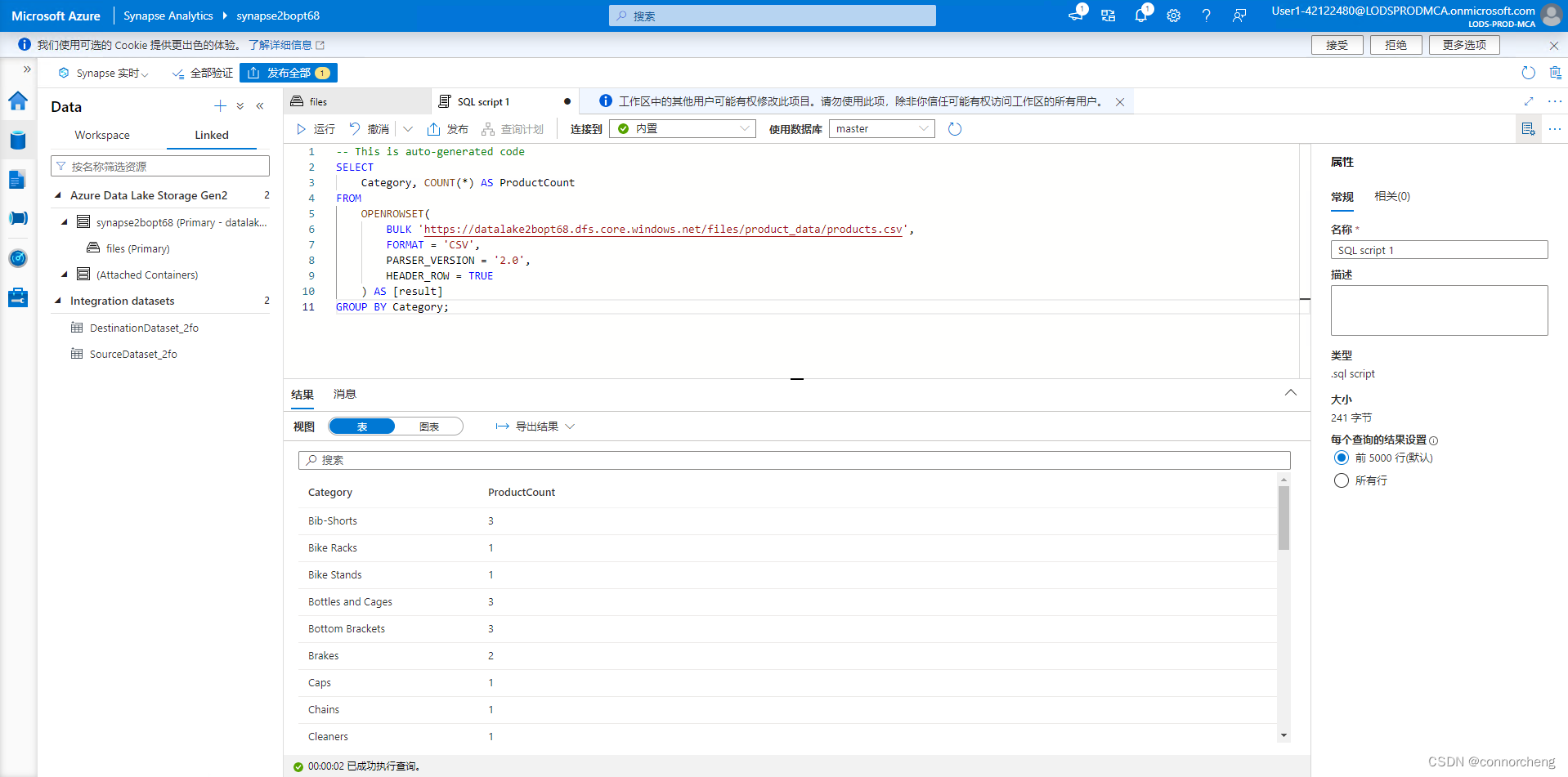
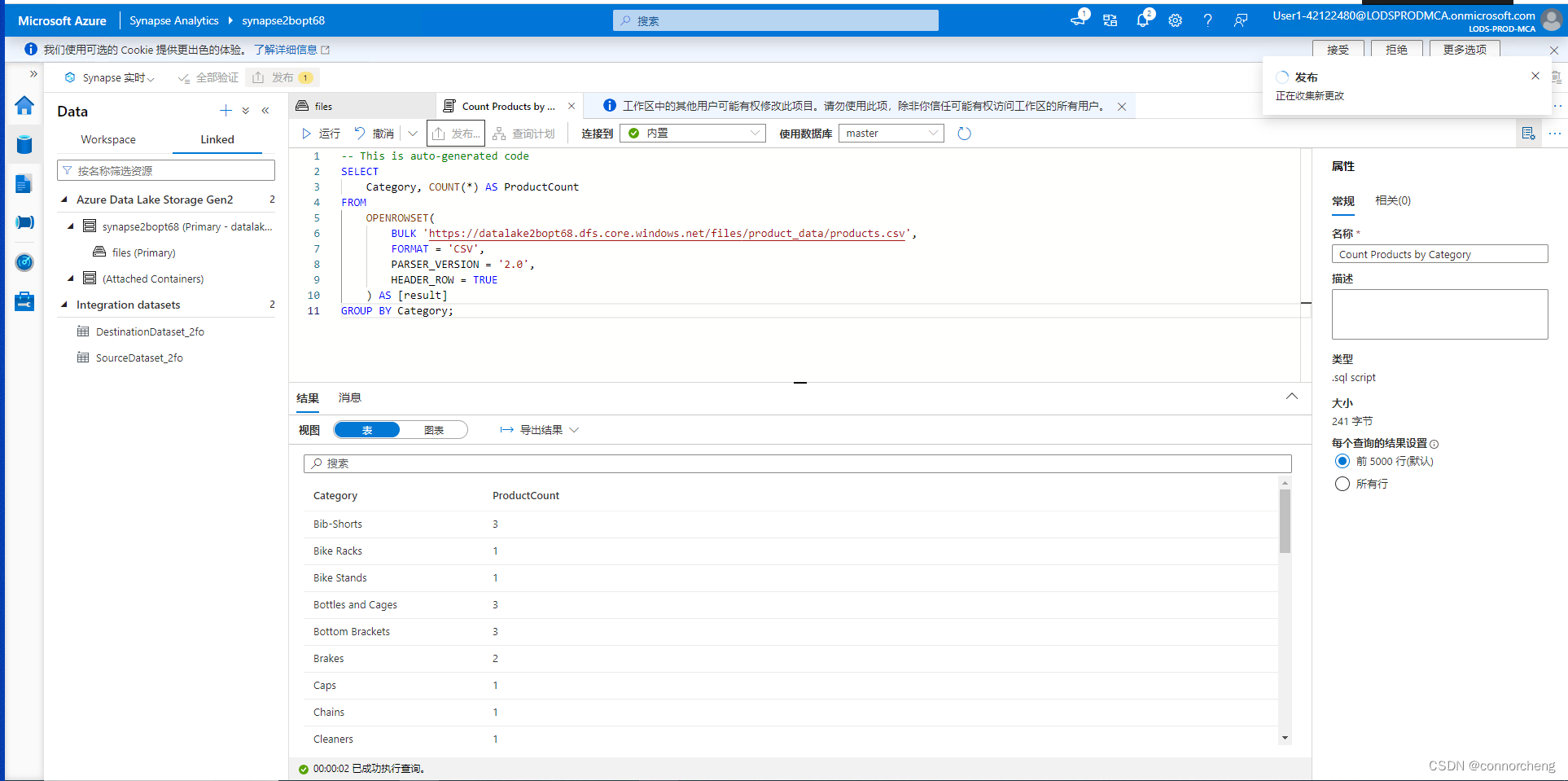
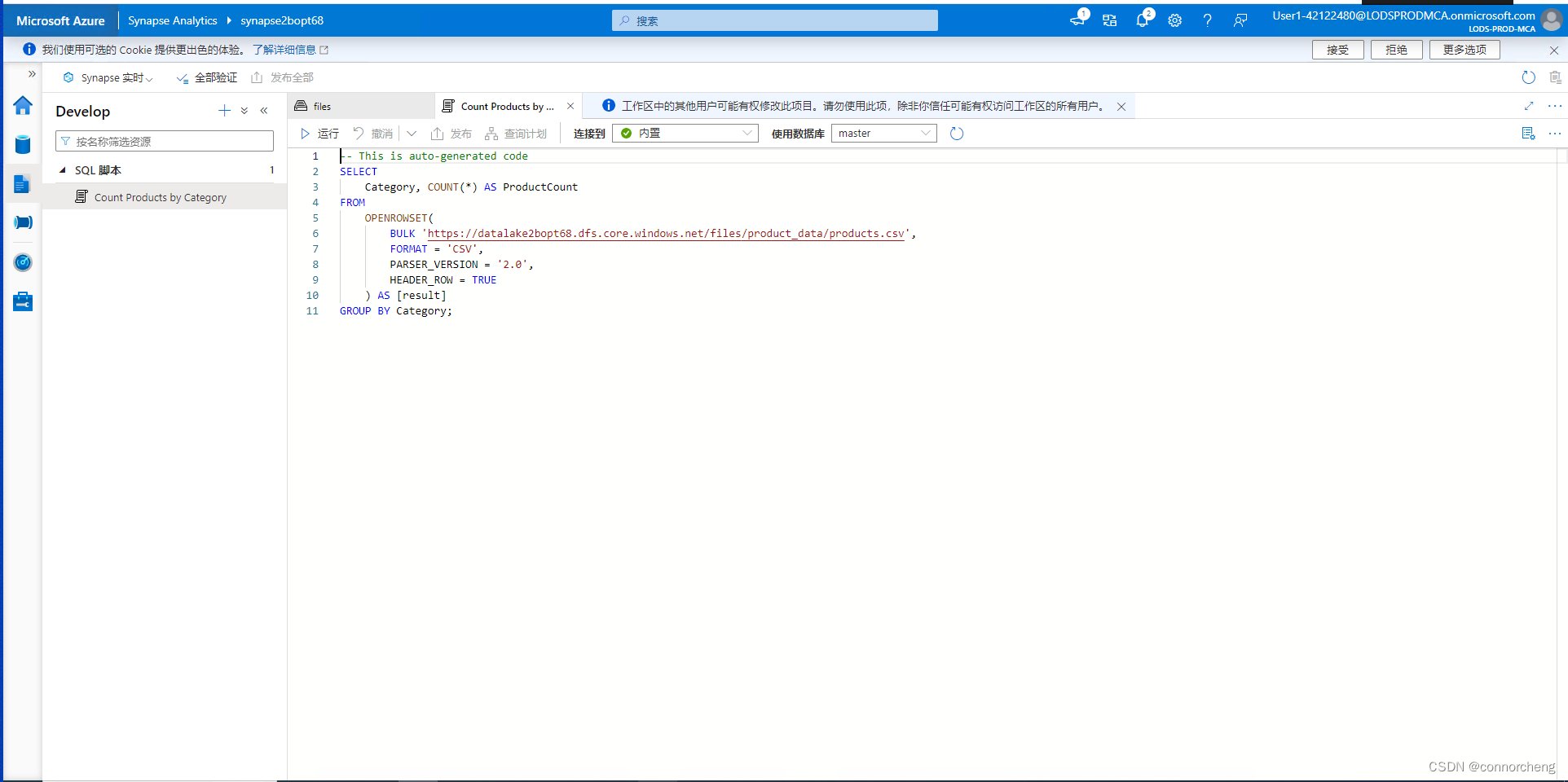
- SELECT
- Category, COUNT(*) AS ProductCount
- FROM
- OPENROWSET(
- BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
- FORMAT = 'CSV',
- PARSER_VERSION='2.0',
- HEADER_ROW = TRUE
- ) AS [result]
- GROUP BY Category;
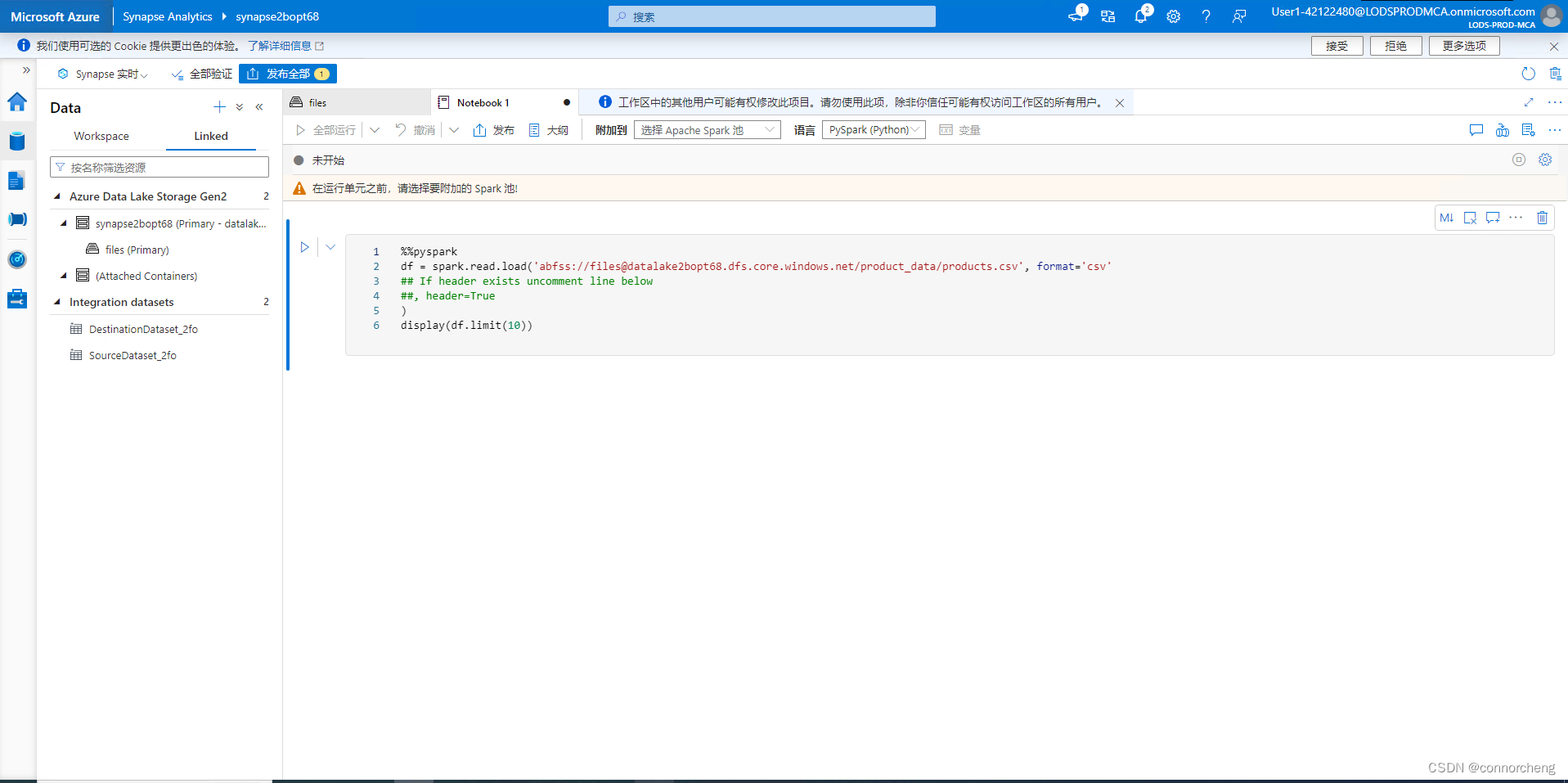
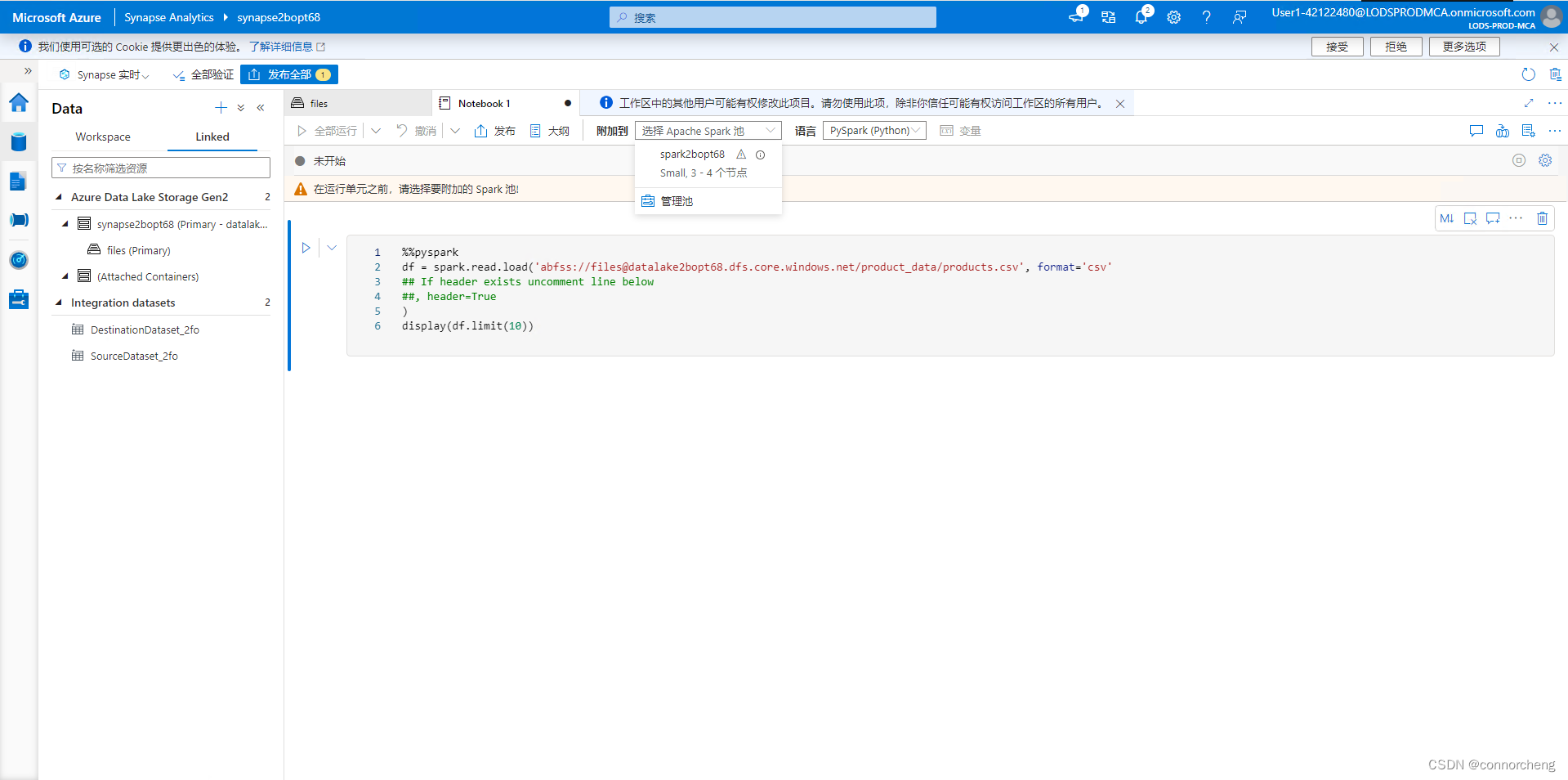
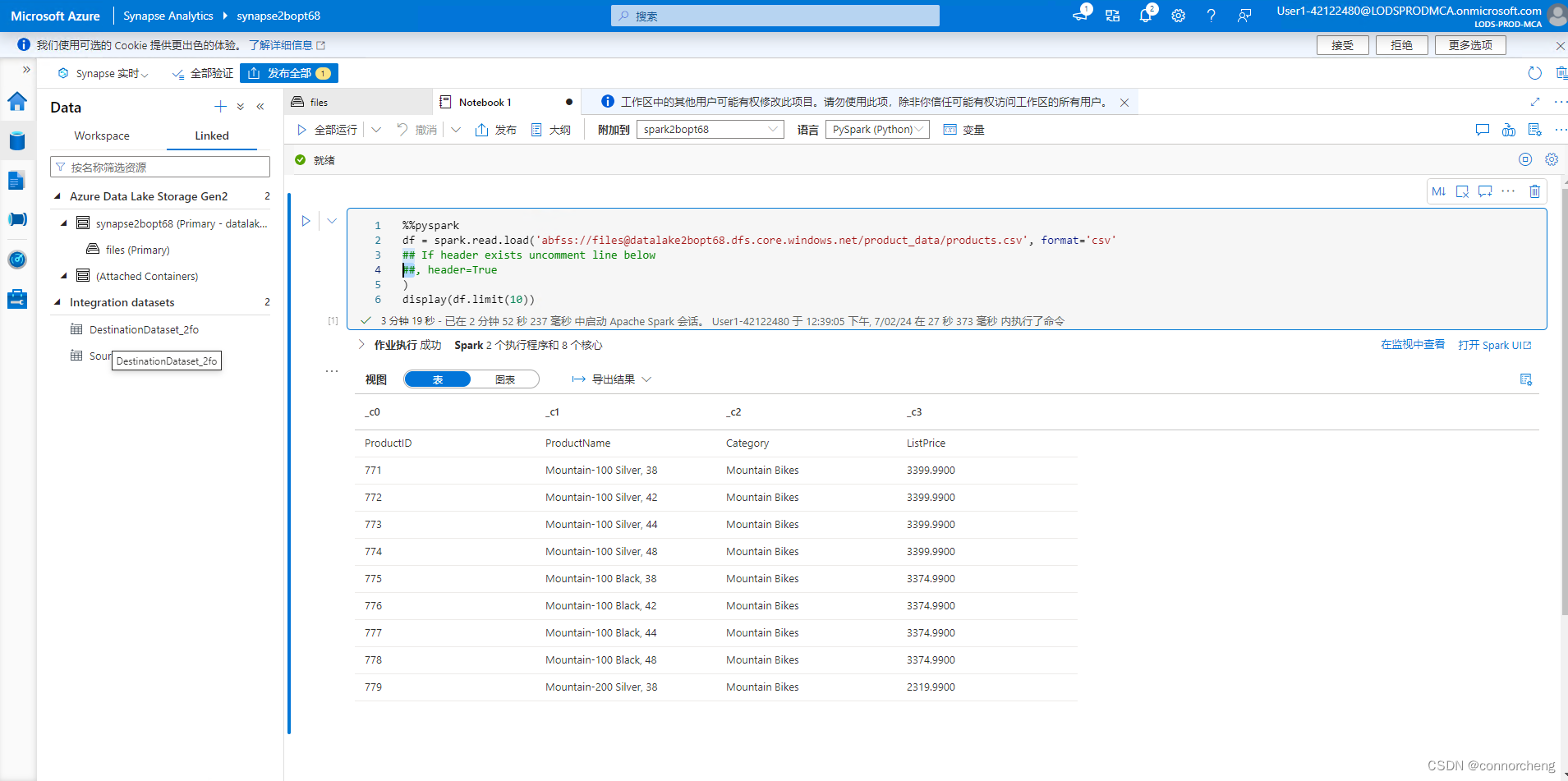
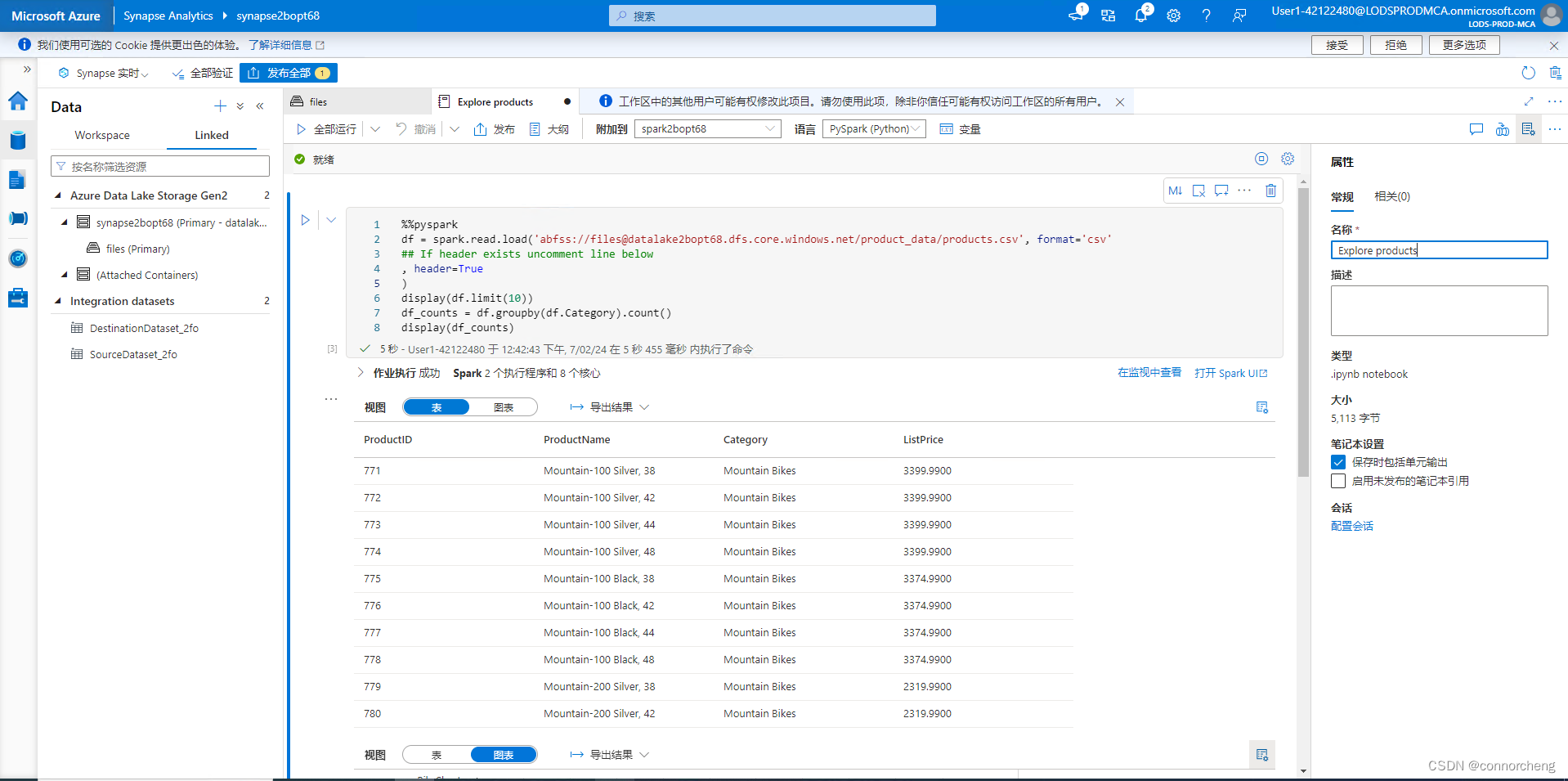
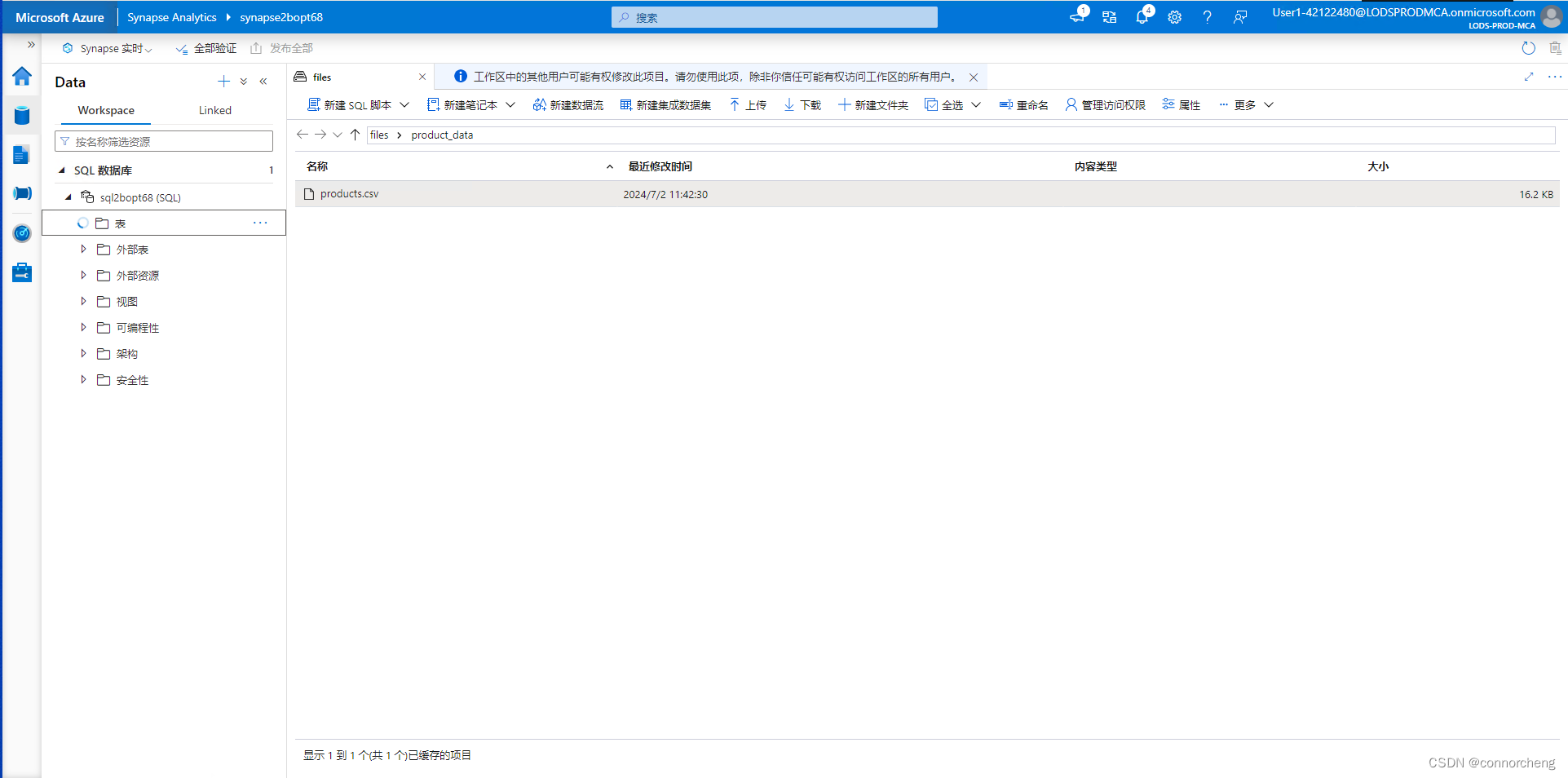
- %%pyspark
- df = spark.read.load('abfss://files@datalakexxxxxxx.dfs.core.windows.net/product_data/products.csv', format='csv'
- ## If header exists uncomment line below
- ##, header=True
- )
- display(df.limit(10))
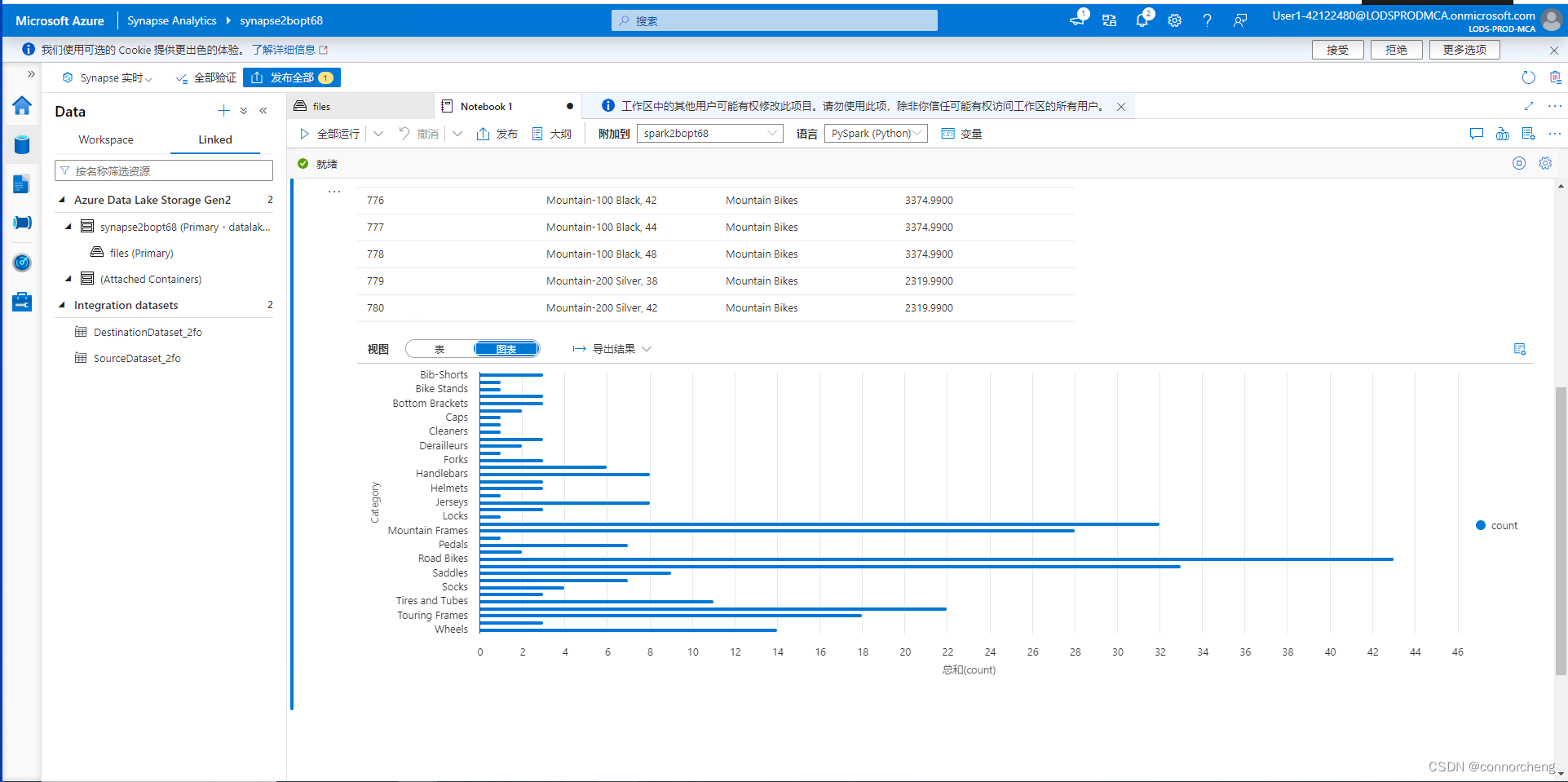
- %%pyspark
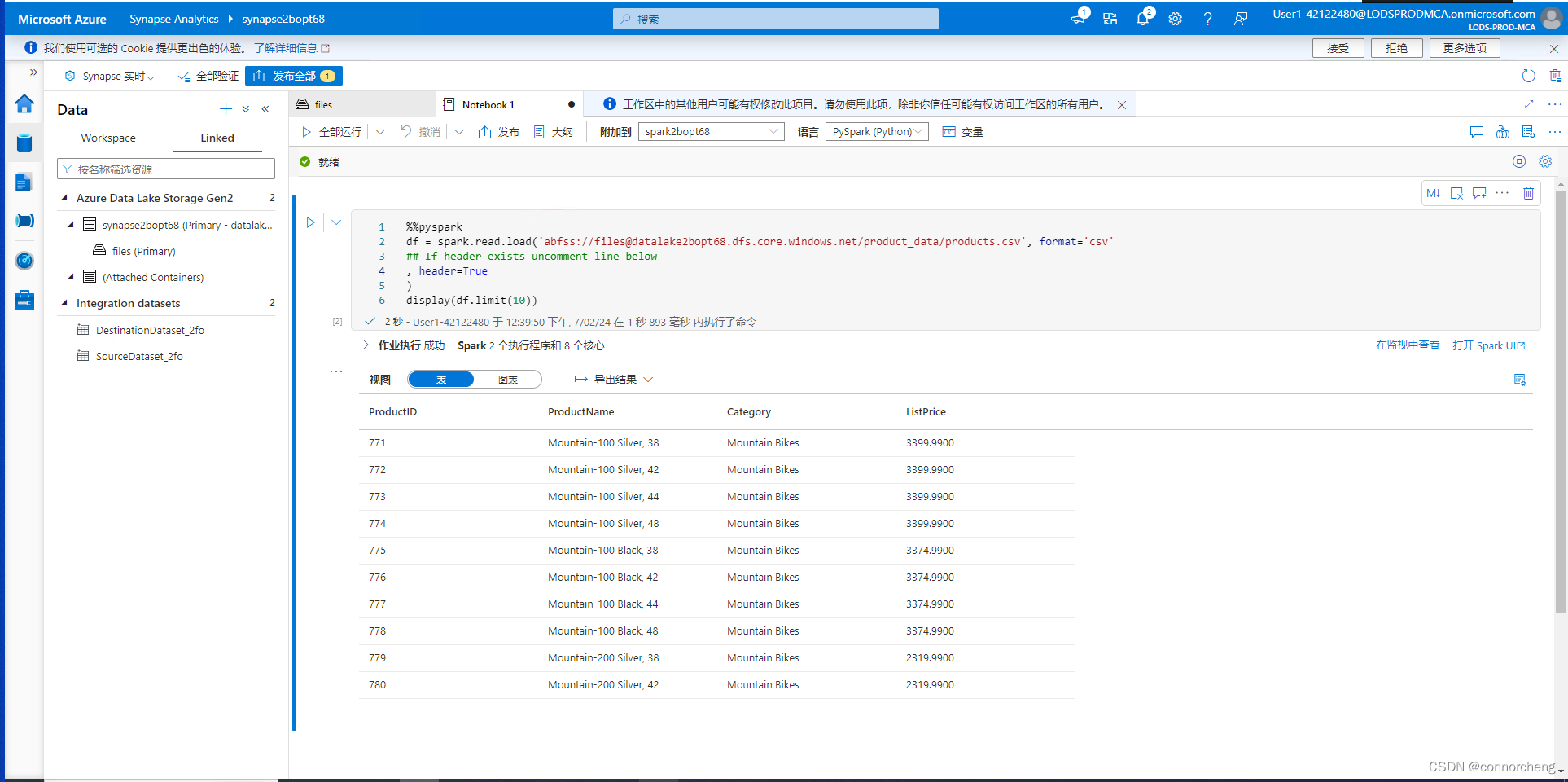
- df = spark.read.load('abfss://files@datalakexxxxxxx.dfs.core.windows.net/product_data/products.csv', format='csv'
- ## If header exists uncomment line below
- , header=True
- )
- display(df.limit(10))
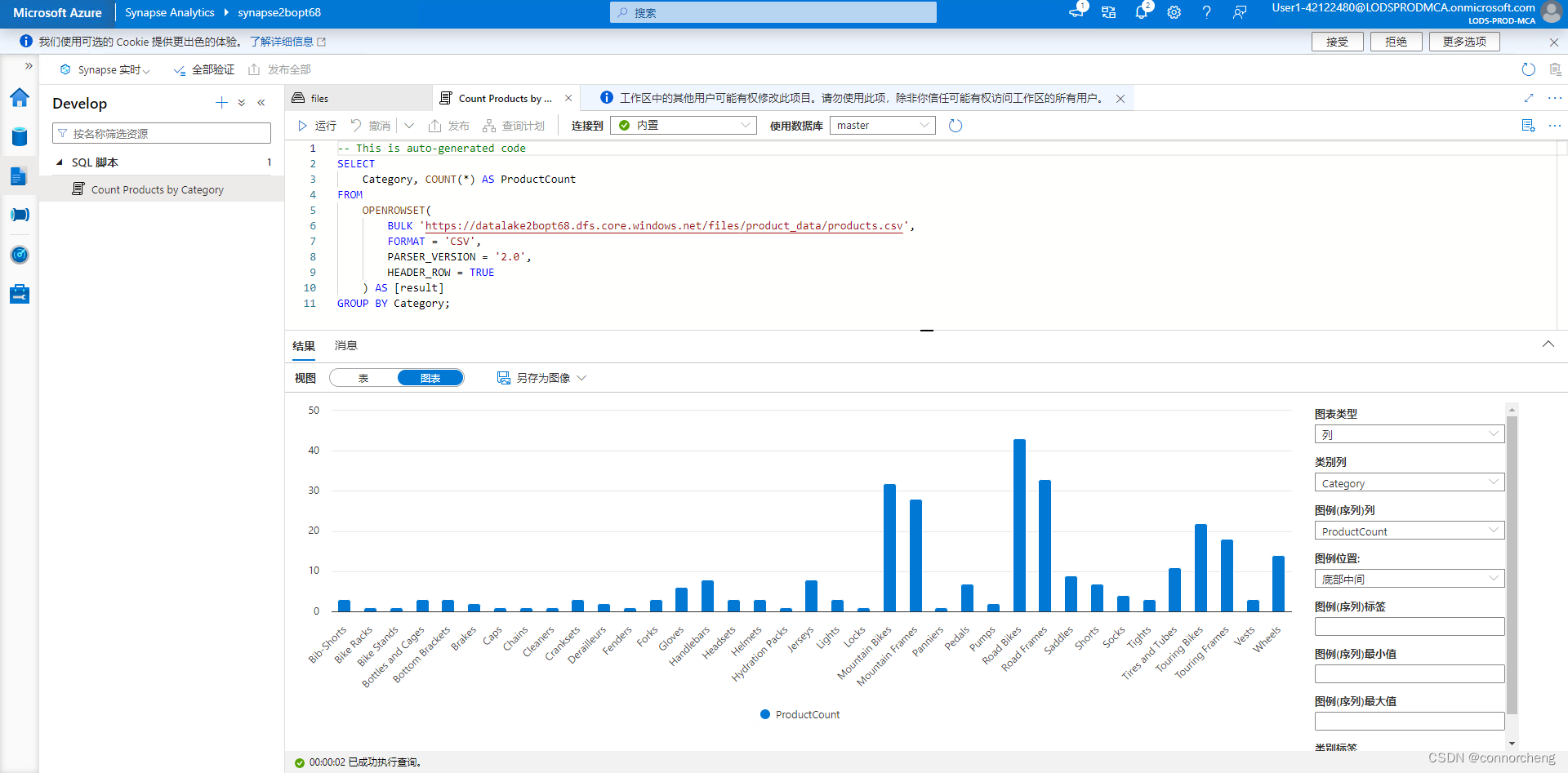
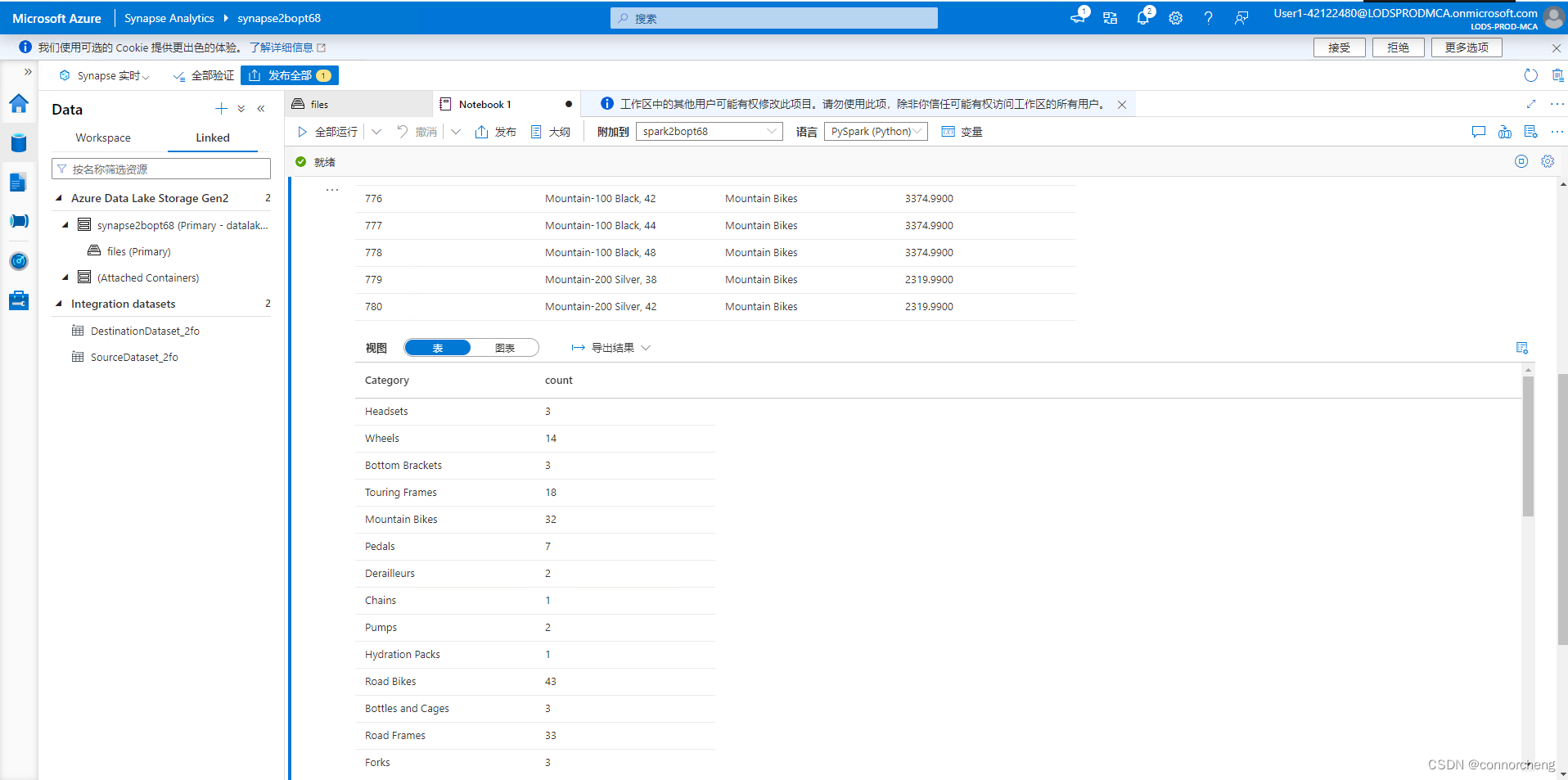
- df_counts = df.groupby(df.Category).count()
- display(df_counts)
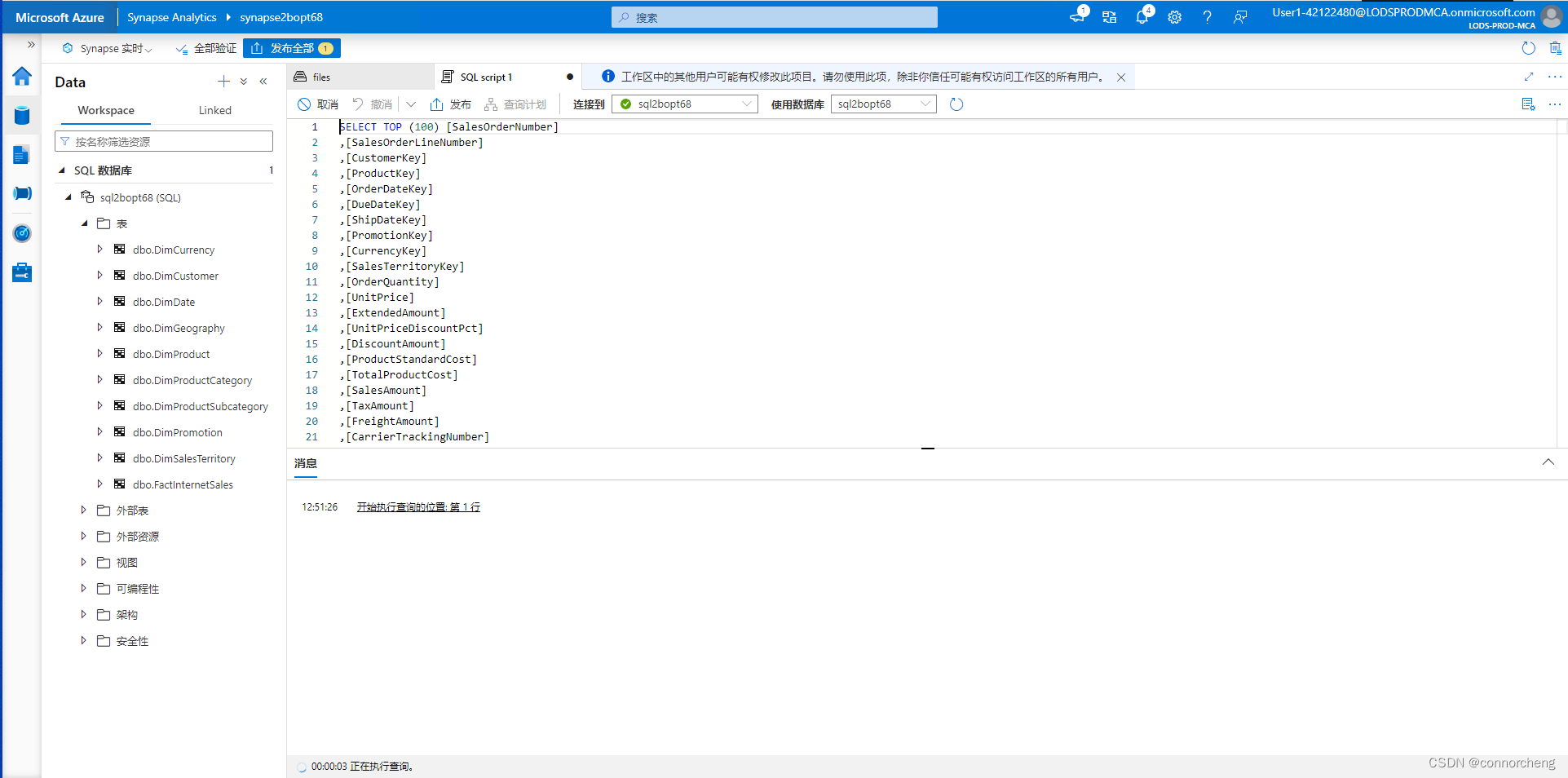
- SELECT d.CalendarYear, d.MonthNumberOfYear, d.EnglishMonthName,
- p.EnglishProductName AS Product, SUM(o.OrderQuantity) AS UnitsSold
- FROM dbo.FactInternetSales AS o
- JOIN dbo.DimDate AS d ON o.OrderDateKey = d.DateKey
- JOIN dbo.DimProduct AS p ON o.ProductKey = p.ProductKey
- GROUP BY d.CalendarYear, d.MonthNumberOfYear, d.EnglishMonthName, p.EnglishProductName
- ORDER BY d.MonthNumberOfYear
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/796423
推荐阅读
相关标签

