
热门标签
热门文章
- 1vue2.0 集成UEditor富文本编辑器_vue2富文本编辑器
- 2win10专业版关闭Windows Defender Antivirus
- 3(YOLOv5-lite)-ONNX模型转换及Openvino推理_yolov5 lite openvino
- 4软考高级之系统分析师及系统架构设计师备考过程记录
- 5utf8mb4_0900_ai_ci_utf8mb40900aici
- 6【银行测试】超细支付功能测试+测试点总结分析(详全)_围绕银行的付款功能和接口进行测试分析
- 7《伸手系列》之arm架构服务器安装kubernetes_kubernetes arm版安装包下载
- 8【C++ QT项目实战-03】---- C++ QT系统实现读取JSON文件数据的自动化模式_qt读json文件
- 9Kafka环境搭建
- 10java 字符数组对象_java-将对象数组转换为字符串数组
当前位置: article > 正文
1.数据类型和向量_向量数据类型
作者:从前慢现在也慢 | 2024-07-07 09:19:50
赞
踩
向量数据类型
1. 数据类型
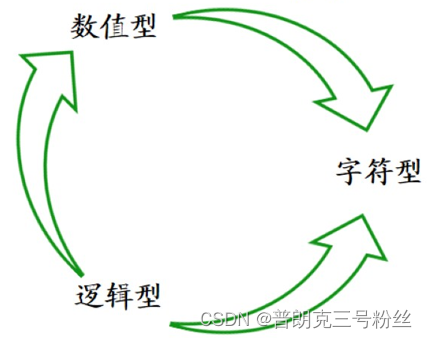
1.1 三种类型
数值型(numeric):1.3, 2
字符型(character):"a", "1"
逻辑型(logical):TRUE(T), FALSE(F), NA
(1)比较运算的结果为逻辑值:
> 3>5
[1] FALSE
> 3==5
[1] FALSE
> 3<=5
[1] TRUE
> 3!=5
[1] TRUE
> "a"!="b"
[1] TRUE
> "a"=="b"
[1] FALSE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(2)逻辑条件“&”,“|”,“!”的运算
> 3>5 & 3==5
[1] FALSE
> 3<5 | 4>5
[1] TRUE
> !(3>=5)
[1] TRUE
- 1
- 2
- 3
- 4
- 5
- 6
1.2 判断函数
判断数据类型的函数为: class()
> class("1")
[1] "character"
> class(1)
[1] "numeric"
> class(TRUE)
[1] "logical"
> class(NA)
[1] "logical"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.3 转换函数
#逻辑型->数值型 > as.numeric(TRUE) [1] 1 > as.numeric(FALSE) [1] 0 #字符型->数值型 > as.numeric("4") [1] 4 #数值型->逻辑型 > as.logical(4) [1] TRUE > as.logical(0) [1] FALSE #字符型->逻辑型 > as.logical("b") [1] NA > as.logical("s") [1] NA > #数值型->字符型 > as.character(4) [1] "4" > #逻辑型->字符型 > as.character(TRUE) [1] "TRUE" > as.character(FALSE) [1] "FALSE"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2. 向量
2.1 向量的生成
(1)使用 c() 罗列
数据转换的优先顺序:
#向量包含: 数值型 + 字符型 = 字符型
> c(1,2,3,"a")
[1] "1" "2" "3" "a"
#向量包含: 数值型 + 逻辑型 = 数值型
> c(1,2,3,TRUE)
[1] 1 2 3 1
#向量包含: 字符型 + 数值型 + 逻辑型 = 字符型
> c(1,"a",3,TRUE)
[1] "1" "a" "3" "TRUE"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(2)连续数值向量
> 1:6
[1] 1 2 3 4 5 6
- 1
- 2
(3)重复值、规律数、随机数
# 重复值 > rep("v",6) [1] "v" "v" "v" "v" "v" "v" > rep(c("a","b","c"),3) [1] "a" "b" "c" "a" "b" "c" "a" "b" "c" # 规律数 > seq(from = 1, to = 5, by = 1) [1] 1 2 3 4 5 > seq(from = 1, to = 5, by = 2) [1] 1 3 5 # 随机数 #生成5个服从正态分布(均值为0,标准差为1)的随机数 > rnorm(5, mean = 0, sd = 1) [1] 2.0884427 -0.8395444 0.4313966 -1.4728999 -2.3550284
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(4)组合函数
> paste(rep("x",5),1:5) # paste的分隔符默认为 空格
[1] "x 1" "x 2" "x 3" "x 4" "x 5"
> paste0(rep("x",5),1:5) # paste0无分隔符
[1] "x1" "x2" "x3" "x4" "x5"
- 1
- 2
- 3
- 4
2.2 单个向量的操作
(1)赋值
# 标准赋值符号 <-
> x <- c(1,2,3,4)
> x
[1] 1 2 3 4
# 非标准赋值符号 =
> y = c(1,2,3,4)
> y
[1] 1 2 3 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(2)数学运算
> x <- c(1,2,3,4)
> x+1
[1] 2 3 4 5
> log(x)
[1] 0.0000000 0.6931472 1.0986123 1.3862944
> sqrt(x)
[1] 1.000000 1.414214 1.732051 2.000000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)逻辑判断
> x <- c(1,2,3,4)
> x > 3
[1] FALSE FALSE FALSE TRUE
- 1
- 2
- 3
(4)初级统计
> x <- c(1,2,3,4,5) > #最小值 > min(x) [1] 1 > #最大值 > max(x) [1] 5 > #均值 > mean(x) [1] 3 > #中位数 > median(x) [1] 3 > #方差 > var(x) [1] 2.5 > #标准差 > sd(x) [1] 1.581139 > #求和 > sum(x) [1] 15 > #升序排序 > sort(x) [1] 1 2 3 4 5 > #降序排序 > sort(x,decreasing = TRUE) [1] 5 4 3 2 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
(5)重复值操作
> x <- c(1,2,3,1,2,5) > # 统计向量元素个数 > length(x) [1] 6 > # 统计向量重复元素个数 > table(x) x 1 2 3 5 #(x中的元素) 2 2 1 1 #(相应元素的个数) > # 判断向量元素是否重复 > duplicated(x) [1] FALSE FALSE FALSE TRUE TRUE FALSE > # 统计向量元素个数 > length(x) [1] 6 > # 去重复 > unique(x) [1] 1 2 3 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.3 两个向量的操作
(1)比较
# 两个向量长度一致时
> x <- c(1,2,3,4,5)
> y <- c(1,2,5,4,8)
>
> x == y
[1] TRUE TRUE FALSE TRUE FALSE
- 1
- 2
- 3
- 4
- 5
- 6
# 两个向量长度不一致时
> x <- c(1,2,3,1,2,5)
> y <- c(1,2,5)
>
> #长度小的向量y发生循环补齐,补齐的元素个数与x相同,即 y : (1,2,5,1,2,5)
> x == y
[1] TRUE TRUE FALSE TRUE TRUE TRUE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)数学运算
> x <- c(1,2,3,1,2,5)
> y <- c(1,2,5)
> # 加 减 乘 除
> x + y
[1] 2 4 8 2 4 10
> x - y
[1] 0 0 -2 0 0 0
> x * y
[1] 1 4 15 1 4 25
> x / y
[1] 1.0 1.0 0.6 1.0 1.0 1.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(3)连接
> x <- c(1,2,3,1,2,5)
> y <- c(1,2,5)
> paste(x,y) # paste的分隔符默认为 空格
[1] "1 1" "2 2" "3 5" "1 1" "2 2" "5 5"
> paste0(x,y) # paste0 无分隔符
[1] "11" "22" "35" "11" "22" "55"
> paste(x,y,sep = "")# 取消paste的分隔符,结果与paste0相同
[1] "11" "22" "35" "11" "22" "55"
> paste(x,y,sep = ",")# paste的分隔符设置为 ,
[1] "1,1" "2,2" "3,5" "1,1" "2,2" "5,5"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(4)交集、并集、差集
> x <- c(1,2,3,1,2,5) > y <- c(1,2,5,1,6) > # 交集 > intersect(x,y) [1] 1 2 5 > # 并集 > union(x,y) [1] 1 2 3 5 6 > # 差集:x除去(x,y)的交集元素 > setdiff(x,y) [1] 3 > # 差集:y除去(x,y)的交集元素 > setdiff(y,x) [1] 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(5) %in%
> x <- c(1,2,3,1,2,5)
> y <- c(1,2,5,1,6)
> # x与y相同位置的元素相等吗 返回值个数为x,y元素个数的最大值
> x == y
[1] TRUE TRUE FALSE TRUE FALSE FALSE
> # x的元素在y中存在吗,返回值个数与x元素个数相同
> x %in% y
[1] TRUE TRUE FALSE TRUE TRUE TRUE
> # y的元素在x中存在吗,返回值个数与y元素个数相同
> y %in% x
[1] TRUE TRUE TRUE TRUE FALSE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.4 向量筛选
(1)根据逻辑值筛选
#单个向量
> x <- 2:10 # (2,3,4,5,6,7,8,9,10)
> # 筛选出x > 7的值
> x>7
[1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
> x[x>7]
[1] 8 9 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
#两个向量
> x <- 2:10 # (2,3,4,5,6,7,8,9,10)
> y <- 5:11 # (5,6,7,8,9,10,11)
> # 筛选出x存在于y中的值
> x[x %in% y]
[1] 5 6 7 8 9 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)根据元素坐标筛选
x <- 2:10 # (2,3,4,5,6,7,8,9,10)
# 筛选出x中第3个、第4个元素
> x[3:4]
[1] 4 5
# 筛选出x中第1个、第7个元素
> x[c(1,7)]
[1] 2 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.5 修改向量元素
> x <- 2:10 > x [1] 2 3 4 5 6 7 8 9 10 > # 将第4个元素赋值为6 > x[4] <- 6 > x [1] 2 3 4 6 6 7 8 9 10 > # 之后,再将第1个元素赋值为6,第三个元素赋值为8 > x[c(1,3)] <- c(6,8) > x [1] 6 3 8 6 6 7 8 9 10 > # 最后,将元素值为6的元素赋值为8 > x[x == 6] <- 8 > x [1] 8 3 8 8 8 7 8 9 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.6 向量元素的命名
(1)命名操作
# 创建向量scores 表示分数
> scores <- c(100,59,78,65,32)
> scores
[1] 100 59 78 65 32
#为向量scores中的元素命名
> names(scores) <- c("ming","uzi","gala","xun","elk")
> scores
ming uzi gala xun elk
100 59 78 65 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(2)取子集操作
# 取出ming和gala的分数 > scores[c(1,3)] # 按照坐标取 ming gala 100 78 > scores[c("ming","gala")] # 按照名称取 ming gala 100 78 > scores[scores>60] # 按照逻辑值取 ming gala xun 100 78 65 # 取出分数超过60的名字 > names(scores)[scores>60] [1] "ming" "gala" "xun"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
from 生信技能树课程
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

