
热门标签
热门文章
- 1fiddler使用教程以及工作原理_fiddler 会话列表 滚动
- 22020-09兴盛优选前端开发笔试题(不全)_兴盛优选前端面试题
- 3Axure 9 增、删、改、模糊、准确查询_axure是否确认删除出库申请编号为“n,m”的数据项?
- 4闪电模型数学_教你主宰自己的财富与生活:15个让你终身受益的思维模型
- 5机器学习、深度学习中的目标函数、损失函数、梯度概念
- 6Python爬虫如何实现抓取电影网站?Python爬虫如何对电影网站信息进行爬取?_爬虫抓电影网址
- 7怎么使用Amazon SageMaker构建高质量AI作画模型 Stable Diffusion?_如何使用sagemaker notebook搭建自己的stable diffusion模型
- 8Hadoop-3.1.3部署_[root@master hadoop-3.1.3]# jps 21866 nodemanager
- 9自然语言处理(九):传统的循环神经网络RNN_rnn求损失的时候
- 10防止反编译,保护你的SpringBoot项目_classfinal springboot
当前位置: article > 正文
清华大学chatGLM6B模型本地化部署教程_清华大模型本地调用
作者:从前慢现在也慢 | 2024-04-07 16:15:33
赞
踩
清华大模型本地调用
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。项目地址:
https://github.com/THUDM/ChatGLM-6B。
测试环境:windows11,CUDA 12.1,Torch-2.0.1
内存16G,显卡 3060 , 显存6G
- 安装python,git,网上教程很多,不再重复。
- 确定CUDA,Torch版本且是否相互兼容。
cmd命令行中输入:nvidia-smi
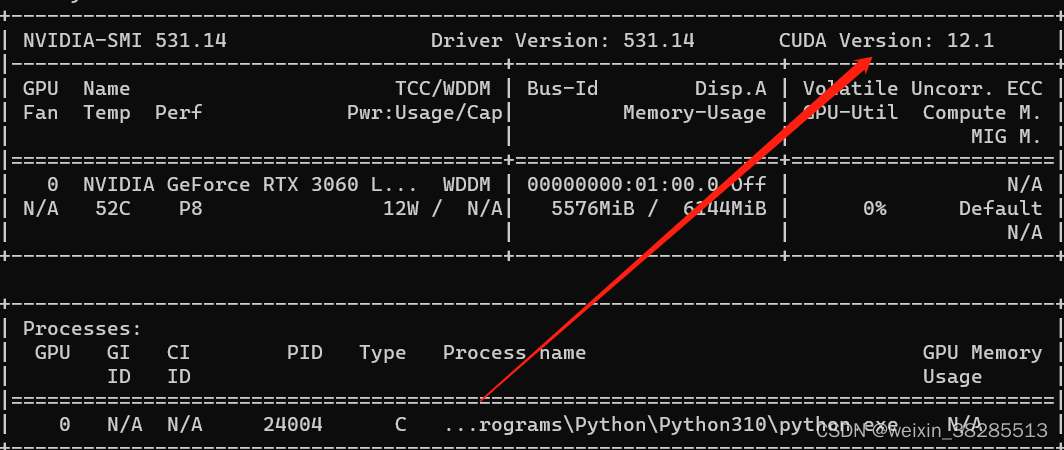
CUDA建议11.8,低于该版本请升级,最新版本下载地址:
https://developer.nvidia.com/cuda-toolkit
Torch 需要选择和CUDA配套的版本:
访问:
https://pytorch.org/get-started/locally/#supported-windows-distributions
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/379457
推荐阅读
相关标签

