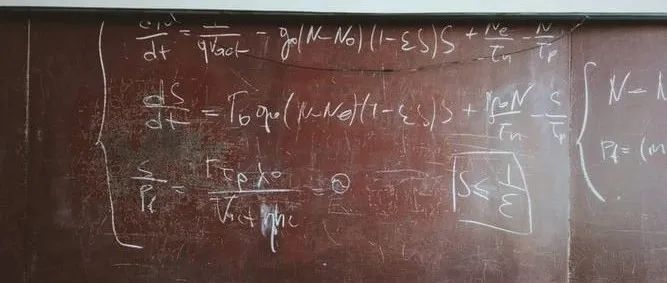- 1excel if in函数_5分钟让你学通Excel中的IF函数
- 2Hugging Face——MLM预训练掩码语言模型方法_掩码语言预训练
- 3C语言 判断是不是字母|三个数中的最大值|变种水仙花
- 4“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向_中国 大模型 开源 闭源
- 5用iPhone前摄3D人像建模,Meta:我看行_ios 开发3d形象
- 6docker安装redis,以及常用操作
- 7本周AI热点回顾:给Deepfake 假脸做 X-Ray、飞桨助力打造肺炎筛查和预评估AI系统
- 8【C语言-二分法】二分法查找有序数组中数的下标为什么要mid+1,mid-1?_为什么二分法要left=mid+1,right=mid-1
- 9Arcgis中栅格计算器赋值python代码_栅格计算器重新赋值
- 10基于全链路的测试分析实践!
EMNLP 2021 | 百度:多语言预训练模型ERNIE-M
赞
踩

作者 | Chilia
哥伦比亚大学 nlp搜索推荐
整理 | NewBeeNLP
2021年伊始,百度发布多语言预训练模型ERNIE-M,通过对96门语言的学习,使得一个模型能同时理解96种语言,该项技术在5类典型跨语言理解任务上刷新世界最好效果。在权威跨语言理解榜单XTREME上,ERNIE-M也登顶榜首,超越微软、谷歌、Facebook等机构提出的模型。(但是现在降到了第7名)
1. 背景
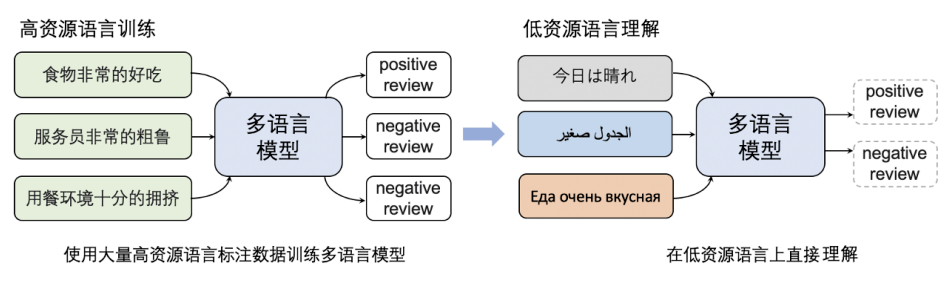
预训练跨语言模型对于下游的跨语言任务有着很大的帮助。以情感分析系统为例,构建情感分析系统往往需要大量有标签数据,而小语种语言中的有标签数据十分稀缺,因而搭建小语种语言的情感分析系统十分困难。依托多语言模型的跨语言迁移能力可以解决该问题,在高资源语言标注数据上训练的模型直接对小语种语言进行理解,搭建小语种语言的情感分析系统。
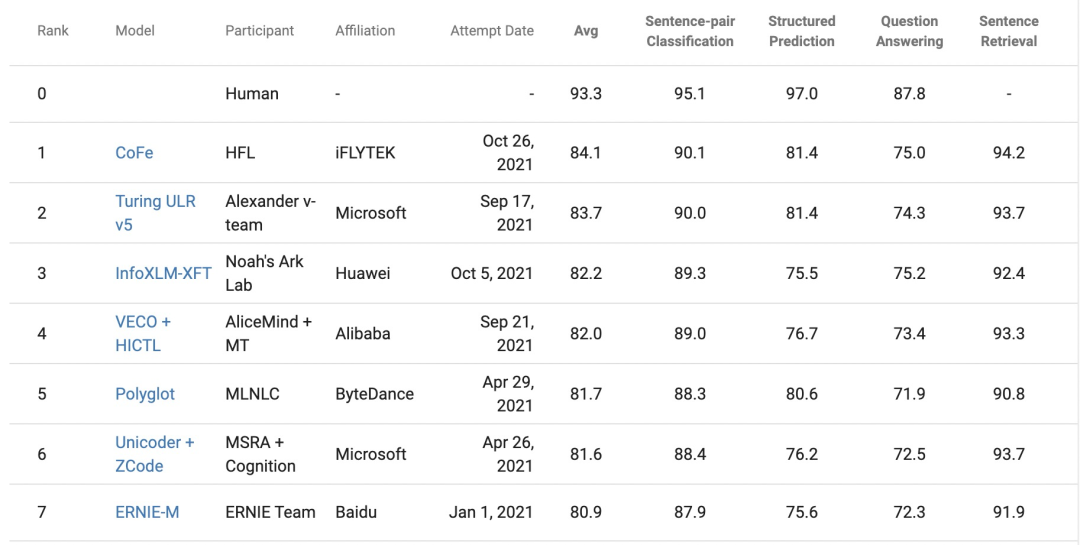
XTREME评测是谷歌研究院、DeepMind和卡耐基梅隆大学于2020年4月发布的涵盖了12个语系40种语言的多语言权威评测榜单。其包括文本分类、结构化预测、语义检索和阅读理解等四类自然语言处理任务的9个数据集。2021年1月1日,ERNIE-M在以80.9分的成绩登顶榜首。
当前的技术主要通过「单语语料」分别学习不同语言的语义,再使用「平行语料」将不同语言的语义对齐。然而大部分语种的平行语料很少,限制了多语言模型的效果。
为了突破平行语料规模对多语言模型的学习效果限制,提升跨语言理解的效果,百度研究人员提出基于「回译机制」、从很少的平行语料中学习语言间的语义对齐关系的预训练模型ERNIE-M,显著提升包括跨语言自然语言推断(XNLI, for cross-lingual natural language inference)、机器问答(MLQA)、命名实体识别(CoNLL)、同意转述识别(PAWS-X, for cross-lingual paraphrase identification)、跨语言检索(Tatoeba) 在内的5种典型跨语言任务效果。
2. 模型
首先提到,现有的预训练方法有:
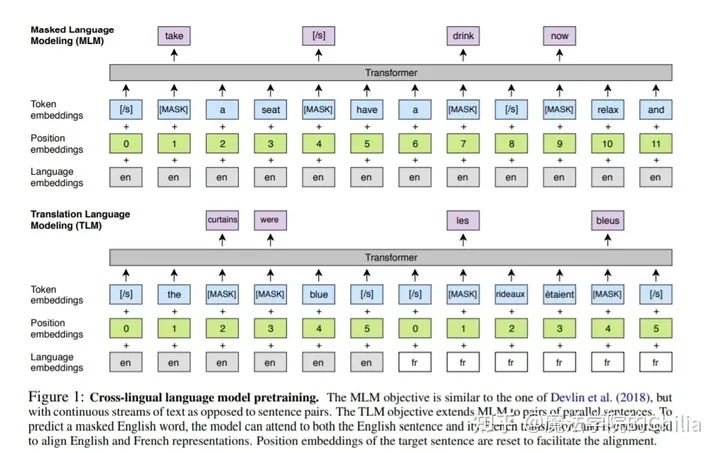
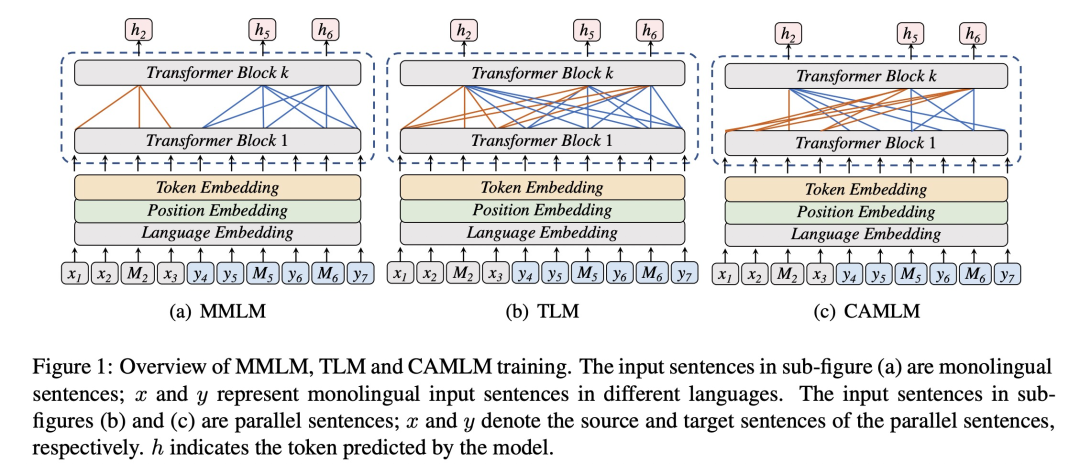
MMLM(multilingual masked language modeling)。其实这个就是最初代的BERT的MLM训练方法,只不过是对100种单语语料都用MLM训练一遍。
TLM(translation language modeling)。这个是XLM提出的预训练方法,和BERT不同的是它用了双语语料,两个语言都有一些[MASK], 需要通过本语言的上下文和对方语言的全文来填补这些[MASK]. 可以想见,MLM由于只用了单一语言,没有做双语对齐;而TLM用了大量平行语料,所以能够「让不同语言embedding共享同一个向量空间」。
本文创新的提出了「CAMLM」(Cross-attention Masked Language Modeling), 其实意思非常简单:对于平行语料语言A和语言B,语言A的[MASK]只能通过语言B来还原、语言B的[MASK]只能通过语言A来还原。这样是为了避免information leakage,即语言直接通过自己的上下文来还原[MASK]。
这样"逼着"模型来学双语的semantic alignment。例如:输入的句子对是<明天会[MASK][MASK]吗,Will it be sunny tomorrow>,模型需要只使用英文句子<Will it be sunny tomorrow>来推断中文句子中掩盖住的词<天晴>,使模型初步建模了语言间的对齐关系。
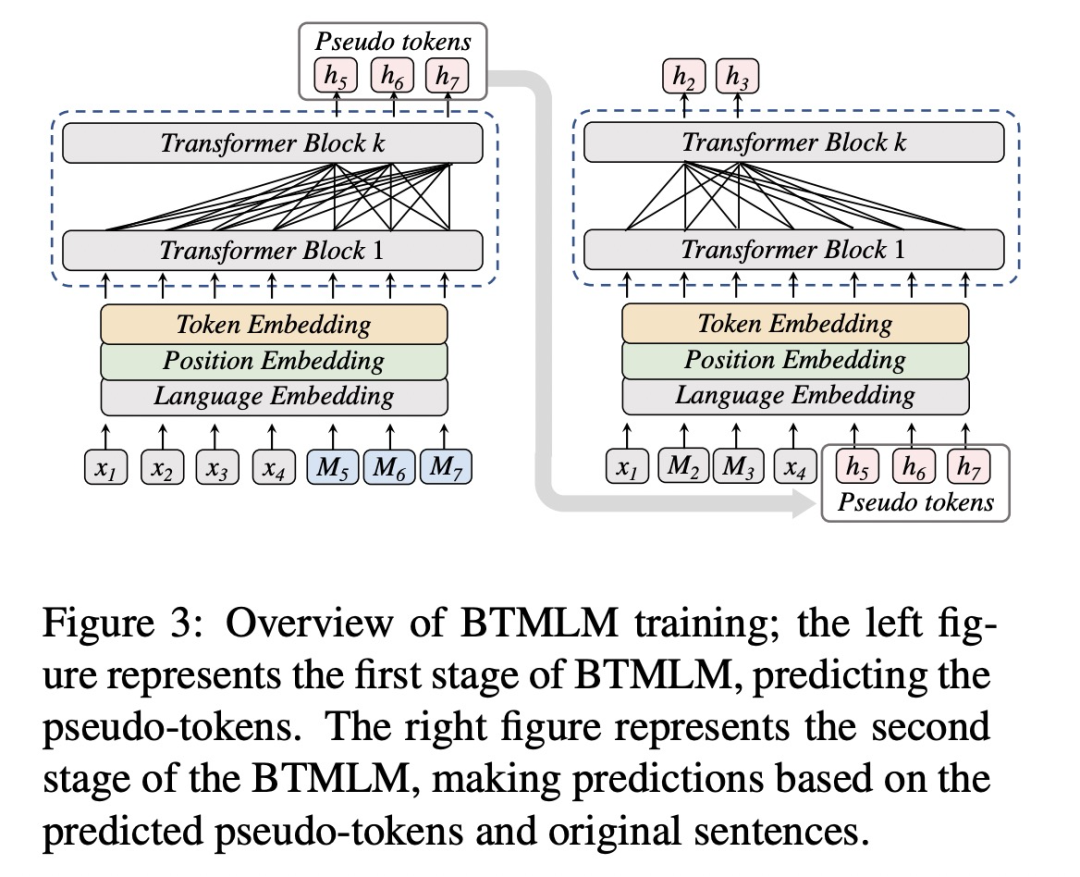
CAMLM需要用到双语语料,那么平行语料不够的怎么办呢?本文还提出了BTMLM(Back-translation Masked Language Modeling), 直接用单语语料学alignment。这是怎么做到的呢?其实也很简单,就是在单语句子A后面加一些[MASK],当成目标语言B需要填充的[MASK],然后用训好的CAMLM来填充之。这样,我们就有了伪平行语料B. 然后再把A的一些词做mask, 只用伪平行语料来填充。通过这种方式,ERNIE-M利用「单语语料更好地建模语义对齐关系」。
3. 实验
使用Transformer encoder。ERNIE-M-BASE 12层,768维,12个头; ERNIE-M-Large 24层,1024维,16头。使用GeLU激活函数,用XLM-R预训练模型做初始化。
通过两种方式评测ERNIE-M的效果:
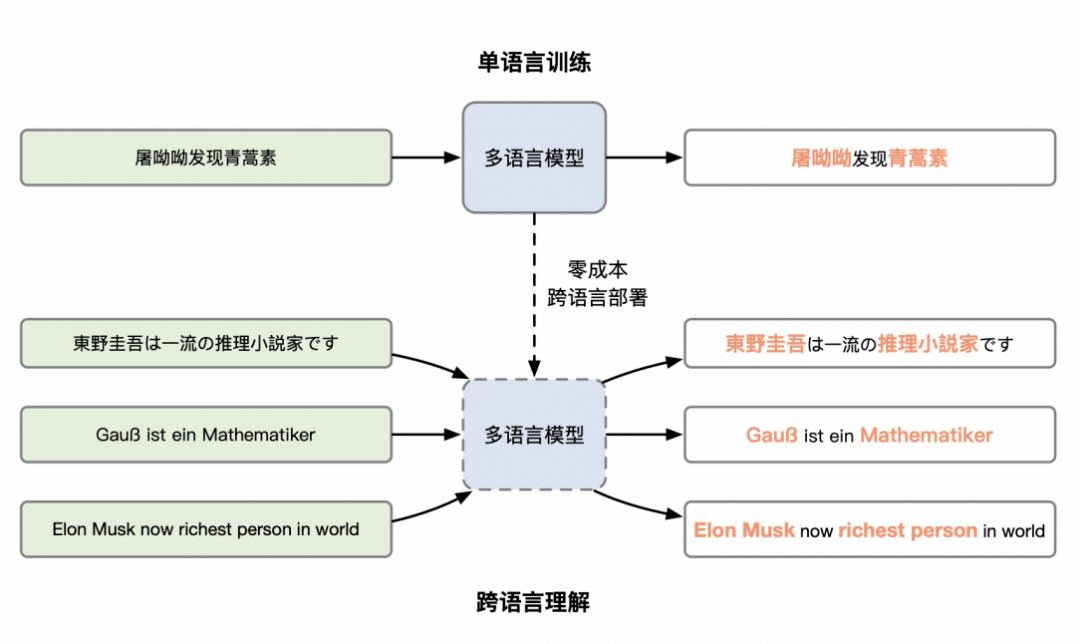
1)Cross-lingual Transfer:该方式将英文训练的模型「直接在其他语言上测试」(直接transfer, 可以理解为是zero-shot learning),验证模型的跨语言理解能力。在实际应用中,如果缺乏某种语言的标注数据,该技术可以通过其他语言的标注数据对多语言模型训练解决该问题,降低小语种系统的构建难度。
2)Multi-language Fine-tuning:该方式使用所有语言的标注数据对模型进行多任务训练,验证在有本语言标注数据的情况下,模型能否「利用其他语言的数据」,进一步增强该语言的理解效果。
跨语言检索 ⭐
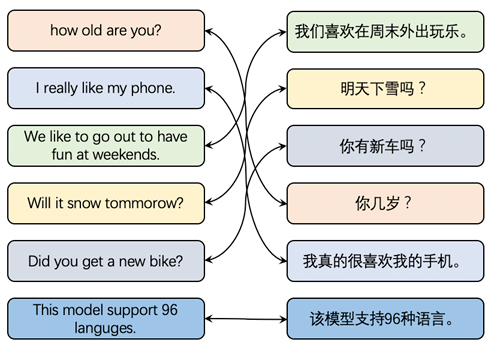
跨语言检索任务是在双语语料库中检索语义相同的句子,如下图所示,ERNIE-M可使得用户只用某一种语言,例如汉语,便可检索到其他语言的结果,如英语、法语、德语等结果。ERNIE-M在跨语言检索数据集「Tatoeba」上取得了准确率87.9%的效果。这个任务也是和笔者现在要研究的方面最接近的。
自然语言推断
自然语言推断是自然语言理解中的一项重要的基准任务,该任务的目标是判断两句话之间的逻辑关系。多语言数据集「XNLI」数据集包含15种语言,既有英语、法语等常见语言也有斯瓦希里语等小语种语言。

ERNIE-M在Cross-lingual Transfer和Multi-language Fine-tuning两种模式下验证了效果。研究者用英语对ERNIE-M进行微调训练,在汉语、德语、乌尔都语等语言上测试,能达到平均准确率82.0%的效果。如果使用所有语言的训练语料,准确率可以进一步提升到84.2%。
阅读理解
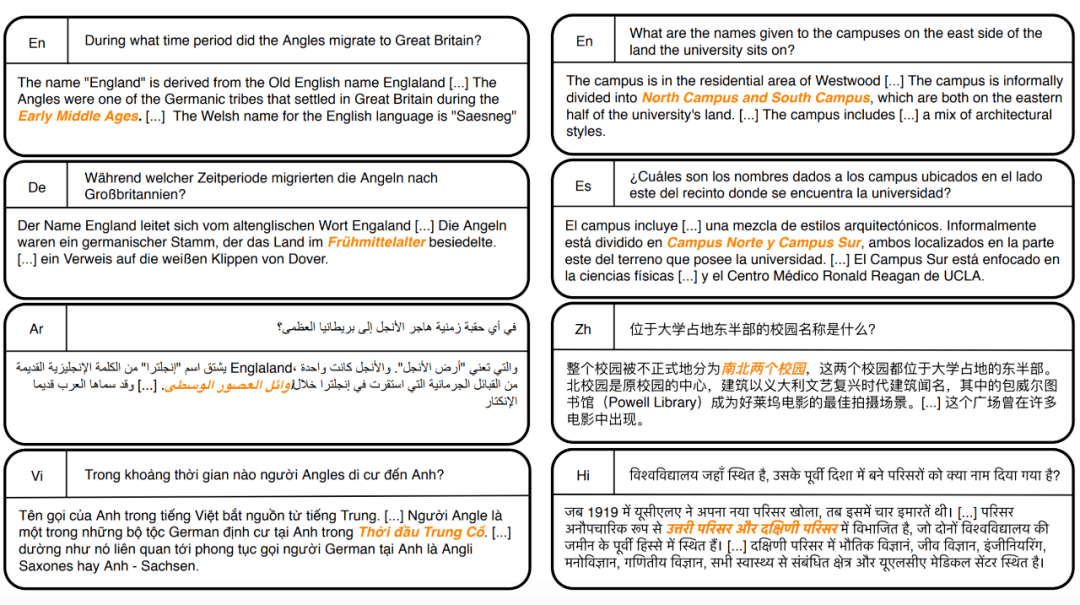
阅读理解任务的目标是根据文章回答指定问题。为了评测ERNIE-M在阅读理解任务上的效果,ERNIE-M在Facebook提出的「MLQA」多语言阅读理解数据集上进行了评测。在该任务中,模型需要先在英语上进行训练,再在其他语言的数据集上评测。此项任务可以评估模型在跨语言问答任务的效果,帮助跨语言问答系统的搭建。该任务如下图所示,ERNIE-M在仅使用英语训练的情况下,不同语言的问题中有55.3%可以完全回答正确。
命名实体识别
命名实体识别任务的目标是识别出文章中的人名、地名、时间、机构等信息。其可以帮助人们快速地从大量文章中提取出有价值的信息。如下图所示,使用多语言模型可以帮助我们在小语种文章上做信息抽取。ERNIE-M在CoNLL数据集上进行评测,同时在Cross-lingual Transfer和Multi-language Fine-tuning两种模式下验证了效果。研究者用英语对ERNIE-M进行微调训练,在荷兰语、西班牙语和德语上进行了测试,平均F1能达到81.6%,如果使用所有语言的训练语料,平均F1可进一步提升至90.8%。
吐槽:本来想用这篇文章的预训练模型,后来发现Ernie-M的预训练模型还没有开源。而且已经开源的ERNIE是用paddlepaddle框架写的,导致很难follow...一人血书百度能不能用点通用框架做研究...

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -