
热门标签
热门文章
- 1ohasd failed to start: Inappropriate ioctl for device_oracle 扩展表空间报错 inappropriate ioctl for device
- 2微信小程序实现简单的计算器功能_小程序设计输入框,然后计算结果输出
- 3【机器学习】十大算法之一 “决策树”_决策树算法的发展历程
- 4【学成在线】imx6ull开发板使用方式详解 + 源码下载 +编译运行简单程序 + Ubuntu虚拟机使用鸿蒙LiteOs操作系统常见错误汇总_imx6ull liteos
- 5【@伏草惟存@】7年系列博文精选
- 6ChatGPT学习企业产品、服务内容、往期方案,处理所输入的客户需求,定制化生成解决方案_chatgpt如何训练企业专门的内容库
- 7Android系统文件夹目录结构详解_手机文件结构
- 8基于vue.js房租中介预约看房系统设计与实现(uniapp框架+PHP后台) 研究背景和意义、国内外现状
- 9datetime 比较_MySQL的5种时间类型的比较,看完之后,大部分程序员都收藏了
- 10用css样式使checkbox复选框变为圆角_checkbox 圆角
当前位置: article > 正文
单阶多层检测器: SSD (Single Shot Multibox Detector)_ssd(单词检测器)
作者:从前慢现在也慢 | 2024-03-22 22:03:28
赞
踩
ssd(单词检测器)
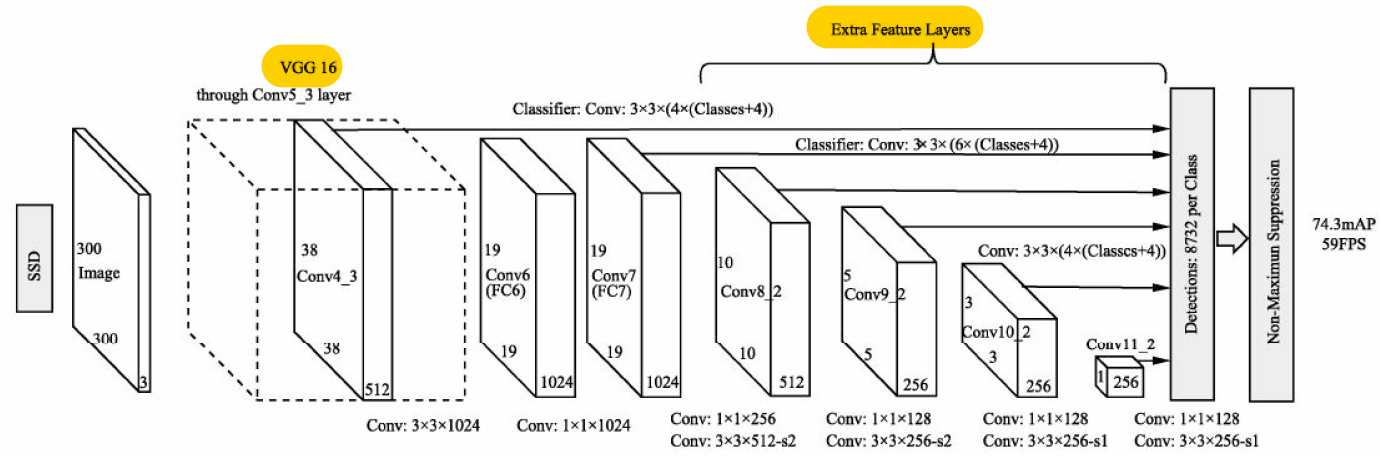
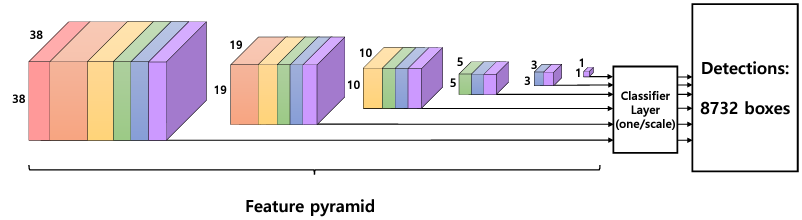
SSD 总览
- SSD 借鉴了 Faster RCNN 与 YOLO 的思想,在一阶网络的基础上使用了固定框进行区域生成,并利用了多层的特征信息,在速度与检测精度上都有了一定的提升
算法流程
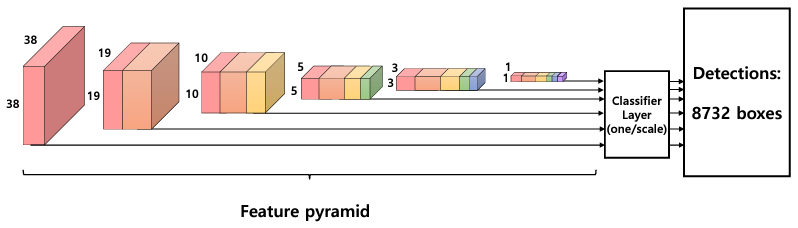
- 输入图像首先经过了 VGGNet 的基础网络,在此之上又增加了 4 个卷积模块,由此得到了 6 个大小与深浅不同的特征层。与 Faster RCNN 类似,SSD 利用了固定大小与宽高的 PriorBox 作为区域生成,但与 Faster RCNN 不同的是,SSD 不是只在一个特征图上设定预选框,而是在 6 个不同尺度上都设立预选框,并且在浅层特征图上设立较小的 PriorBox 来负责检测小物体,在深层特征图上设立较大的 PriorBox 来负责检测大物体。然后利用
3
×
3
3×3
3×3 的卷积核在 6 个大小与深浅不同的特征层上进行预测,得到预选框的分类与回归预测值,随后进行预选框与真实框的匹配,利用 IoU 筛选出正样本与负样本,最终计算出分类损失与回归损失
数据预处理
- SSD 做了丰富的数据增强策略,这部分为模型的 mAP 带来了 8.8% 的提升,尤其是对于小物体和遮挡物体等难点,数据增强起到了非常重要的作用

class SSDAugmentation(object): def __init__(self, size=300, mean=(104, 117, 123)): self.mean = mean self.size = size # 在进行数据增强时,需要将 image, boxes, labels 同步进行变换,因此需要单独实现数据增强的类 # 具体实现可参考代码 https://github.com/amdegroot/ssd.pytorch self.augment = Compose([ ConvertFromInts(), # 将图像像素值从整型变成浮点型 ToAbsoluteCoords(), # 将标签中的边框从比例坐标变换为真实坐标 PhotometricDistort(), # 光学变换 Expand(self.mean), # 随机扩展图像大小,图像仅靠右下方 RandomSampleCrop(), # 随机裁剪图像 RandomMirror(), # 随机左右镜像 ToPercentCoords(), # 从真实坐标变回比例坐标 Resize(self.size), # 缩放到固定的 300×300 大小 SubtractMeans(self.mean) # 去均值 ]) def __call__(self, img, boxes, labels): # 输入参数为 image, boxes, labels return self.augment(img, boxes, labels)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
光学变换
- 亮度调整: 以 0.5 的概率为图像中的每一个点加一个实数,该实数随机选取于 [ − 32 , 32 ) [-32,32) [−32,32) 区间中
- 对比度调整: 以 0.5 的概率为图像中的每一个点乘一个实数,该实数随机选取于 [ 0.5 , 1.5 ) [0.5,1.5) [0.5,1.5) 区间中
- 色相调整: 在 HSV 色域空间中,以 0.5 的概率为图像通道 0 的每一个点加一个实数,该实数随机选取于 [ − 18 , 18 ) [-18,18) [−18,18) 区间中,接着将通道 0 中数值大于 360 的点减去 360,小于 0 的点加上 360
- 饱和度调整: 在 HSV 色域空间中,以 0.5 的概率为图像通道 1 的每一个点乘一个实数,该实数随机选取于
[
0.5
,
1.5
)
[0.5,1.5)
[0.5,1.5) 区间中
- 随机调整顺序: 对比度调整有 0.5 的概率在色相调整和饱和度调整之前,0.5 的概率在色相调整和饱和度调整之后
- 添加随机的光照噪声: 随机交换 RGB 三个通道的值
几何变换
- 随机扩展: 随机选择一个在 [ 1 , 4 ) [1,4) [1,4) 区间的数作为扩展比例生成扩展图像,扩展图像的各个通道的值为原图像各个通道的均值,即 [ 104 , 117 , 123 ] [104,117,123] [104,117,123]。然后将原图像放在扩展后图像的右下角并调整 boxes 的坐标
- 随机裁剪: 从图像中随机裁剪出一块,需要保证该图像块至少与一个物体边框有重叠,重叠的比例从 { 0.1 、 0.3 、 0.7 、 0.9 } \{0.1、0.3、0.7、0.9\} {0.1、0.3、0.7、0.9} 中随机选取,同时至少有一个物体的中心点落在该图像块中。这保证了每一个图形块都有物体,可以过滤掉不包含明显真实物体的图像;同时,不同的重叠比例也极大地丰富了训练集,尤其是针对物体遮挡的情况
- 随机图像镜像: 图像的左右翻转
- 固定缩放: 默认使用了 300 × 300 300×300 300×300 的输入大小。这里 300 × 300 300×300 300×300 的固定输入大小是经过精心设计的,可以恰好满足后续特征图的检测尺度,例如最后一层的特征图大小为 1 × 1 1×1 1×1,负责检测的尺度则为 0.9
- 去均值: 减去每个通道的均值
网络架构
基础 VGG 结构
- SSD 采用了 VGG 16 作为基础网络,并在之上进行了一些改善。输入图像经过预处理后大小固定为
300
×
300
300×300
300×300,首先经过 VGG 16 网络的前 13 个卷积层,然后利用两个卷积 Conv 6 与 Conv 7 取代了原来的全连接网络,进一步提取特征:
 改善主要有以下两点:
改善主要有以下两点:
- (1) 原始 VGG 16 的池化层统一大小为 2 × 2 2×2 2×2,步长为 2,而在 SSD 中,Conv 5 后接的 Maxpooling 层池化大小为 3,步长为 1,这样做可以在增加感受野的同时,维持特征图的尺寸不变
- (2) Conv 6 中使用了空洞数为 6 的空洞卷积,其 padding 也为 6,这样做同样也是为了增加感受野的同时保持参数量与特征图尺寸的不变
def vgg(cfg, i, batch_norm=False): layers = [] in_channels = i for v in cfg: if v == 'M': # add MaxPool layer layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # (floor(W/2), floor(H/2)) elif v == 'C': # add MaxPool layer layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)] # (ceil(W/2), ceil(H/2)) else: # add (Conv[, BN], ReLU) layers conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) # (W, H) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v # 池化层 pool5 在增加感受野的同时,维持特征图的尺寸不变 pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # (W, H) # Conv6 + Conv7 conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) # (W, H) conv7 = nn.Conv2d(1024, 1024, kernel_size=1) # (W, H) layers += [pool5, conv6, nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)] return layers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
# input size: (300, 300, 3)
base = [64, 64, # Conv1 -> output size: (300, 300, 64)
'M', 128, 128, # Conv2 -> output size: (150, 150, 128)
'M', 256, 256, 256, # Conv3 -> output size: (75, 75, 256)
'C', 512, 512, 512, # Conv4 -> output size: (38, 38, 512)
'M', 512, 512, 512] # Conv5 -> output size: (19, 19, 512)
# Conv6 -> output size: (19, 19, 1024)
# Conv7 -> output size: (19, 19, 1024)
vgg_base = vgg(base, 3) # 构造基础网络
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
深度卷积层
- 在 VGG 16 的基础上,SSD 进一步增加了 4 个深度卷积层,用于更高语义信息的提取. 为了降低参数量,在此使用了
1
×
1
1×1
1×1 卷积先降低通道数为该层输出通道数的一半,再利用
3
×
3
3×3
3×3 卷积进行特征提取

def add_extras(cfg, i, batch_norm=False): # Extra layers added to VGG for feature scaling layers = [] in_channels = i flag = False for k, v in enumerate(cfg): # v == 'S' 代表后一个卷积层步长为 2 if in_channels != 'S': if v == 'S': layers += [nn.Conv2d(in_channels, cfg[k + 1], kernel_size=(1, 3)[flag], stride=2, padding=1)] else: layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])] flag = not flag in_channels = v return layers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
# input size: (19, 19, 1024)
extras = [256, 'S', 512, # Conv8 -> output size: (10, 10, 512)
128, 'S', 256, # Conv9 -> output size: (5, 5, 256)
128, 256, # Conv10 -> output size: (3, 3, 256)
128, 256] # Conv11 -> output size: (1, 1, 256)
conv_extras = add_extras(extras, 1024)
- 1
- 2
- 3
- 4
- 5
- 6
PriorBox 与边框特征提取网络
分类与位置卷积层
- PriorBox 与 Faster RCNN 的 Anchor 类似,本质上是在原图上的一系列矩形框。某个特征图上的一个点根据下采样率可以得到在原图的坐标,SSD 先验性地提供了以该坐标为中心的 4 个或 6 个不同大小的 PriorBox,然后利用特征图的特征去预测这 4/6 个 PriorBox 的类别与位置偏移量
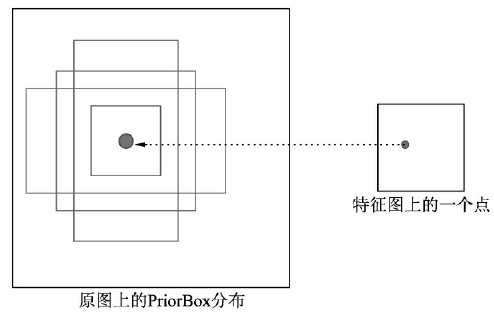
- 同时,SSD 还使用了多层特征图来做物体检测,分别提取出 Conv 4, 7, 8, 9, 10, 11 输出的 6 个不同大小的特征图,其中浅层的特征图检测小物体,深层的特征图检测大物体。6 个特征图上的每一个点分别对应 4、6、6、6、4、4 个 PriorBox。接下来分别利用
3
×
3
3×3
3×3 的卷积 (分类与位置卷积层),即可得到每一个 PriorBox 对应的类别与位置预测量:
 例如,Conv 8 得到的特征图大小为
10
×
10
×
512
10×10×512
10×10×512,每个点对应 6 个 PriorBox,一共有 600 个 PriorBox。由于采用的 PASCAL VOC 数据集的物体类别为 21 类,因此
3
×
3
3×3
3×3 卷积后得到的类别特征维度为
6
×
21
=
126
6×21=126
6×21=126,位置特征维度为
6
×
4
=
24
6×4=24
6×4=24
例如,Conv 8 得到的特征图大小为
10
×
10
×
512
10×10×512
10×10×512,每个点对应 6 个 PriorBox,一共有 600 个 PriorBox。由于采用的 PASCAL VOC 数据集的物体类别为 21 类,因此
3
×
3
3×3
3×3 卷积后得到的类别特征维度为
6
×
21
=
126
6×21=126
6×21=126,位置特征维度为
6
×
4
=
24
6×4=24
6×4=24
一共生成了 8732 个预选框
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [21, -2] # vgg 中 Conv4 和 Conv7 的序号
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels, # 位置卷积层
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels, # 分类卷积层
cfg[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k] # 位置卷积层
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k] # 分类卷积层
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
mbox = [4, 6, 6, 6, 4, 4] # number of boxes per feature map location
# vgg_base, conv_extras 分别为 VGG 和深度卷积层的各层组成的列表
base_, extras_, head_ = multibox(vgg_base, conv_extras, mbox, num_classes)
- 1
- 2
- 3
确定每一个特征图 PriorBox 的具体大小
- 越深的特征图拥有的感受野越大,其对应的 PriorBox 也应越来越大,SSD 采用了下式来计算每一个特征图对应的 PriorBox 的尺度
S
k
S_k
Sk:
 其中
k
=
1
,
2
,
3
,
4
,
5
,
6
k=1,2,3,4,5,6
k=1,2,3,4,5,6 时分别对应 SSD 的第
4
,
7
,
8
,
9
,
10
,
11
4,7,8,9,10,11
4,7,8,9,10,11 个卷积层;
S
m
i
n
=
0.2
S_{min}=0.2
Smin=0.2,
S
m
a
x
=
0.9
S_{max}=0.9
Smax=0.9,分别表示最浅层与最深层对应的尺度与原图大小的比例,即第 4 个卷积层得到的特征图对应的尺度为 0.2,第 11 个卷积层得到的特征图对应的尺度为 0.9
其中
k
=
1
,
2
,
3
,
4
,
5
,
6
k=1,2,3,4,5,6
k=1,2,3,4,5,6 时分别对应 SSD 的第
4
,
7
,
8
,
9
,
10
,
11
4,7,8,9,10,11
4,7,8,9,10,11 个卷积层;
S
m
i
n
=
0.2
S_{min}=0.2
Smin=0.2,
S
m
a
x
=
0.9
S_{max}=0.9
Smax=0.9,分别表示最浅层与最深层对应的尺度与原图大小的比例,即第 4 个卷积层得到的特征图对应的尺度为 0.2,第 11 个卷积层得到的特征图对应的尺度为 0.9 - 基于每一层的基础尺度
S
k
S_k
Sk,对于第 1、5、6 个特征图,每个点对应了 4 个PriorBox,因此其宽高分别为
{ S k , S k } , { S k 2 , 2 S k } , { 2 S k , S k 2 } , { S k S k + 1 , S k S k + 1 } \{S_k,S_k\},\{\frac{S_k}{\sqrt2},\sqrt2S_k\},\{\sqrt2S_k,\frac{S_k}{\sqrt2}\},\{\sqrt{S_kS_{k+1}},\sqrt{S_kS_{k+1}}\} {Sk,Sk},{2 Sk,2 Sk},{2 Sk,2 Sk},{SkSk+1 ,SkSk+1 }而对于第 2、3、4 个特征图,每个点对应了 6 个 PriorBox,则在上述 4 个宽高值上再增加两种比例的框:
{ S k 3 , 3 S k } , { 3 S k , S k 3 } \{\frac{S_k}{\sqrt3},\sqrt3S_k\},\{\sqrt3S_k,\frac{S_k}{\sqrt3}\} {3 Sk,3 Sk},{3 Sk,3 Sk}
匹配与损失求解
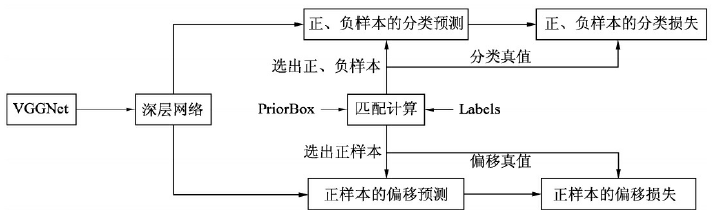
预选框与真实框的匹配
- 在求得 8732 个 PriorBox 坐标及对应的类别、位置预测后,首先要做的就是为每一个 PriorBox 贴标签,筛选出符合条件的正样本与负样本,以便进行后续的损失计算。SSD 处理匹配过程时遵循以下原则:
- (1) 在判断正、负样本时,IoU 阈值设置为 0.5,即一个 PriorBox 与所有真实框的最大 IoU 小于 0.5 时,判断该框为负样本
- (2) 判断对应关系时,将 PriorBox 与其拥有最大 IoU 的真实框作为其位置标签
- (3) 与真实框有最大 IoU 的 PriorBox,即使该 IoU 不是此 PriorBox 与所有真实框 IoU 中最大的 IoU,也要将该 Box 对应到真实框上,这是为了保证真实框的 Recall
- (4) 在预测边框位置时,SSD 与 Faster RCNN 相同,都是预测相对于预选框的偏移量,因此在求得匹配关系后还需要进行偏移量计算:
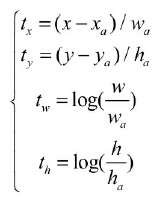
定位损失的计算
- 在完成匹配后,由于有了正、负样本及每一个样本对应的真实框,因此可以进行定位的损失计算。与 Faster RCNN 相同,SSD 使用了
s
m
o
o
t
h
L
1
smooth_{L_{1}}
smoothL1 函数作为定位损失函数,并且只对正样本计算:
L r e g ( t i , t i ∗ ) = ∑ i ∈ { x , y , w , h } smooth L 1 ( t i − t i ∗ ) smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwiseLreg(ti,ti∗)=i∈{x,y,w,h}∑ smooth L1(ti−ti∗) smooth L1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise Lreg(ti,t∗i)=∑i∈{x,y,w,h} smooth L1(ti−t∗i) smooth L1(x)={0.5x2|x|−0.5 if |x|<1 otherwise
难样本挖掘
- 在完成正、负样本匹配后,由于一般情况下一张图片的物体数量不会超过 100,因此会存在大量的负样本。如果这些负样本都考虑则在损失反传时,正样本能起到的作用就微乎其微了,因此需要进行难样本的挖掘。这里的难样本是针对负样本而言的
- Faster RCNN 通过限制正负样本的数量来保持正、负样本均衡,而在 SSD 中,则是保证正、负样本的比例来实现样本均衡。具体做法是在计算出所有负样本的损失后进行排序,选取损失较大的那一部分进行计算,舍弃剩下的负样本,数量为正样本的 3 倍。
类别损失计算
- 在得到筛选后的正、负样本后,即可进行类别的损失计算。SSD 在此使用了交叉熵损失函数,并且正、负样本全部参与计算。同时,为了克服正、负样本的不均衡,进行
难样本挖掘,筛选出数量是正样本 3 倍的负样本;最后,计算筛选出的正、负样本的类别损失,完成整个网络向前计算的全过程
SSD 的改进算法
SSD 算法的限制
- 对于小物体的检测效果一般,这是由于其虽然使用了分辨率大的浅层特征图来检测小物体,但浅层的语义信息不足,无法很好地完成分类与回归的预测
- 每一层 PriorBox 的大小与宽高依赖于人工设置,无法自动学习,当检测任务更换时,调试过程较为烦琐
- 由于是一阶的检测算法,分类与边框回归都只有一次,在一些追求高精度的场景下,SSD系列相较于 Faster RNCN 系列来讲,仍然处在下风
DSSD: 深浅层特征融合
- 为了解决 SSD 浅层语义信息不足而带来的小物体检测效果一般的问题,DSSD 进行了提出了一套针对 SSD 多尺度预测的深浅特征融合方法,改进了传统的上采样方法,并且可以适用于多种基础 Backbone 结构,提升了模型的性能,尤其是对于小物体的检测
深浅层特征融合是一种常用的解决浅层语义信息不足的方法,通常有 3 种计算方法:
- (1) 按通道拼接 (Concatenation): 将深层与浅层的特征按通道维度进行拼接
- (2) 逐元素相加 (Eltw Sum): 将深层与浅层的每一个元素在对应位置进行相加
- (3) 逐元素相乘 (Eltw Product): 将深层与浅层的每一个元素在对应位置进行相乘,这也是 DSSD 采用的特征融合方式 (在实验时,DSSD 采用逐元素相乘比逐元素相加提升了 0.2% 个 mAP,速度上相乘操作比相加稍慢一点)
DSSD 的深浅层特征融合
- 将最深层的
1
×
1
1\times1
1×1 特征图直接用作分类与回归,接着,该特征经过一个反卷积模块进行上采样,并与更浅一层的特征进行逐元素相乘,将输出的特征用于分类与回归计算。类似地,继续将该特征与浅层特征进行反卷积与融合,共计输出 6 个融合后的特征图,形成一个沙漏式的结构,最后给分类与回归网络做预测
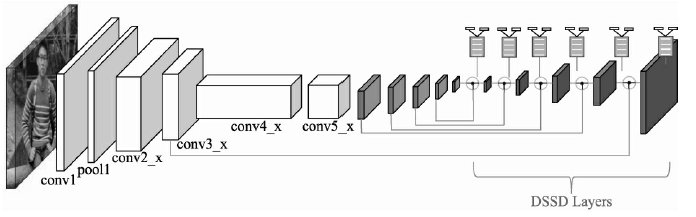
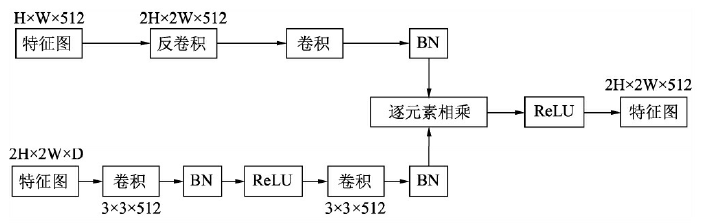
- 具体的反卷积模块如下图所示,注意到深浅层特征图是在 BN 层之后进行逐元素相乘,这是由于不同层之间的特征激活值尺度与感受野不同,直接融合在一起训练难度较大,也可能会淹没某些特征图上的特征,因此在融合前得先做一个 BN 操作,把各层特征进行均一化处理以统一尺度,加速训练
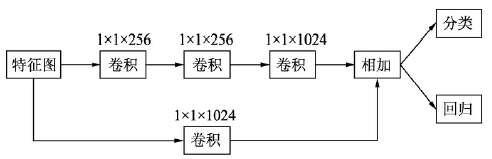
DSSD 的预测网络
- DSSD 的预测网络包含了一个残差单元,主路和旁路进行逐元素相加,然后再接到分类与回归的预测模块中
RSSD (Rainbow SSD): 彩虹式特征融合
Motivation
- (1) SSD 的各个特征图只考虑当前层的检测尺度,没有考虑特征图之间的关联性,容易出现多个特征图上的预选框与一个真实框 (GroundTruth) 相匹配,即使有 NMS 后续操作,但也不能完全避免这种误检的情况
- (2) 小物体检测效果差:SSD 主要利用浅层特征图检测小物体,但由于浅层的特征图语义信息太少,影响了对小物体的检测
彩虹式特征融合
- 池化融合: 对浅层的特征图进行池化,然后与下一个特征图进行通道拼接作为下一层特征图的最终特征。类似地,依次向下进行通道拼接,这样特征图的通道数逐渐增加,并且融合了越来越多层的特征
- 反卷积融合: 与池化融合方法相反,反卷积融合是对深层的特征图进行反卷积,扩充尺寸,然后与浅层的特征图进行通道拼接,并逐渐传递到最浅层
- 彩虹式融合: 彩虹式融合结合了前两种策略,浅层特征通过池化层融合到深层中,深层特征通过反卷积融合到浅层中,这样就使每一个特征图的通道数是相同的 (i,e.
512
+
1024
+
512
+
256
+
256
+
256
=
2816
512+1024+512+256+256+256=2816
512+1024+512+256+256+256=2816)。由于每一层都融合了多个特征图的特征,并且可以用下图的颜色进行区分,因此被称为 Rainbow SSD
 注意到,与 DSSD 类似,在进行不同尺度特征图融合前需要做一次 BN 操作,以统一融合时每个层的尺度
注意到,与 DSSD 类似,在进行不同尺度特征图融合前需要做一次 BN 操作,以统一融合时每个层的尺度
共享分类网络分支的卷积权重
- 每一个特征图的特征通道相同,因此可以采用同一个分类网络来提取预选框的类别预测信息,共用一套分类网络权重参数,这样做的好处是将不同尺度的问题归一化处理,模
型更加稳定,也更容易收敛,同时增加了不同特征图之间的联系,减少了重复框的出现
RefineDet: Faster RCNN 与 SSD 的结合
- RefineDet 结合了一阶网络与两阶网络的优点,在保持高效的前提下实现了精度更高的检测。RefineDet 在 SSD 的基础上,一方面引入了 Faster RCNN 两阶网络中边框由粗到细两步调整的思想,即先通过一个网络粗调固定框,然后再通过一个网络细调;另一方面采用了类似于 FPN 的特征融合方法,可以有效提高对小物体的检测效果
RefineDet 的网络结构
- RefineDet 的网络结构主要由 ARM (Anchor Refinement Module)、TCB (Transfer Connection Block) 与 ODM (Object Detection Module) 这 3 个模块组成:
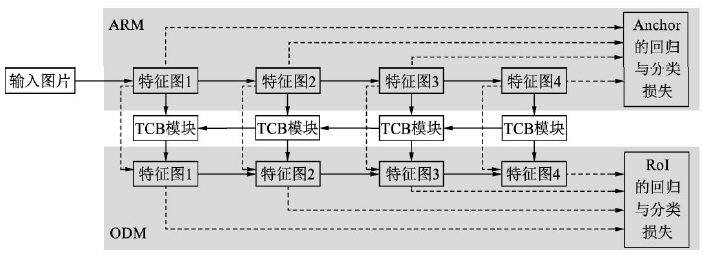
ARM (Anchor Refinement Module)
- ARM 部分首先经过一个 VGG 16 或者 ResNet-101 的基础网络得到 4 个不同尺度的特征图,然后在多个特征图上对应不同大小宽高的 Anchors,并用 3 × 3 3\times3 3×3 的卷积网络去预测 Anchors 的类别 (前景/背景) 和偏移量,进一步可以求得每一个 Anchor 的分类与回归损失 (交叉熵分类与 s m o o t h L 1 smooth_{L_1} smoothL1 损失函数)。这一步起到了类似于 RPN 的作用,网络结构类似于 SSD
- 总体来看,ARM 有如下两点作用:(1) 过滤掉一些简单的负样本,减少后续模型的搜索空间,也缓解了正、负样本不均衡的问题;(2) 通过类似于 RPN 一样的网络,可以得到 Anchor 的预测偏移量,因此可以粗略地修正 Anchor 的位置,为 ODM 模块提供比固定框更精准的感兴趣区域。相比一阶网络,这样做往往可以得到更高的精度
RefineDet 通过 ARM 模块对 Anchor 位置进行了粗略修正,这也是其名字中 “Refine” 的由来
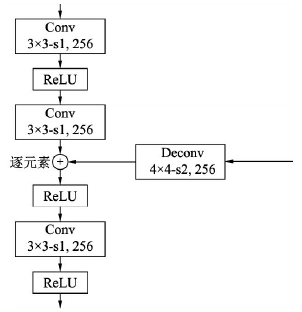
TCB (Transfer Connection Block)
- TCB 模块首先对 ARM 中的每一个特征图进行转换,然后将深层的特征图融合到浅层的特征图中,这一步非常像 FPN 中自上而下与横向连接操作的操作,这种深浅融合的网络可以使特征图拥有更加丰富的信息,对于小物体等物体的预测会更加准确
- 具体而言,TCB 模块使用了两个
3
×
3
3×3
3×3 大小的卷积进一步处理 ARM 部分的特征图,与此同时,利用反卷积处理深层的特征图,得到与浅层尺寸相同的特征,然后逐元素相加,最后再经过一个
3
×
3
3×3
3×3 卷积,将结果输出到 ODM 模块中 (疑问:这里在融合不同尺度特征图时加一个 BN 会不会更好?)
ODM (Object Detection Module)
- ODM 模块基本采取了 SSD 多层特征图的网络结构,但是相比 SSD 算法,ODM 模块的输入有下面两个优势:
- (1) 更好的特征图:相比 SSD 从浅到深的特征,ODM 接收的是 TCB 模块深浅融合的特征,其信息更加丰富,质量更高
- (2) 更好的预选框:SSD 使用了固定的预选框 PriorBox,而 ODM 接收的则是经过 ARM 模块优化后的 Anchor,位置更加精准,并且正、负样本更加均衡
- ODM 后续的匹配与损失计算也基本沿用了 SSD 的算法,采用 0.5 作为正、负样本的阈值,正、负样本的比例为 1:3,损失函数为 Softmax 损失与 s m o o t h L 1 smooth_{L_1} smoothL1 损失
在具体的代码实现时,为了计算方便,在 ARM 处并没有直接抑制掉得分很低的 Anchor,而是在随后的 ODM 中将两部分的得分综合考虑,完成 Anchor 的分类。这种操作也保证了全网络只有一次预选框筛选,从这个角度来看,RefineDet 是一阶的
RFBNet (Receptive Field Block Net): 多感受野融合
Motivation
- 在物体检测领域中,精度与速度始终是难以兼得的两个指标。两阶网络如 Faster RCNN 虽然获得了较高的精度,但牺牲了速度。一阶网络如 SSD、YOLO 等基本可以达到实时的速度,但精度始终不如同时期的两阶网络。基于一阶网络的改进算法,如 DSSD、RefineDet 等虽然提升了一阶网络的精度,但仍牺牲了网络的计算速度 (采用了更复杂的 backbone)
- 针对以上问题,RFBNet 受人类视觉感知的启发,在原有的检测框架中增加了 RFB 模块,使得网络拥有更为强悍的表征能力,而不是简单地增加网络层数、融合等,因此获得了较好的检测速度与精度
RFB 模块
- 神经学发现,群体感受野 (pRF, population Receptive Field) 的尺度会随着视网膜图的偏心而变化,偏心度越大的地方,感受野的尺度也越大。而在卷积网络中,卷积核的不同大小可以实现感受野的不同尺度,空洞卷积的空洞数也可以实现不同的偏心度
- 传统的卷积模块,如 Inception 结构,虽然利用了多个分支来实现多个尺度的感受野,但由于空洞数都为 1,离心率相同,因此在融合时仅仅是不同尺度的堆叠。相比之下,RFBNet 同时将感受野的尺度与偏心度纳入到卷积模块:与 Inception 结构类似,RFB 模块拥有 3 个不同的分支,并且使用了
1
×
1
1×1
1×1、
3
×
3
3×3
3×3 与
5
×
5
5×5
5×5 不同大小的卷积核来模拟不同的感受野尺度,同时使用了空洞数为 1、3、5 的
3
×
3
3\times3
3×3 空洞卷积来实现不同的偏心度。完成 3 个分支后,再利用通道拼接的方法进行融合,利用
1
×
1
1×1
1×1 的卷积降低特征的通道数:
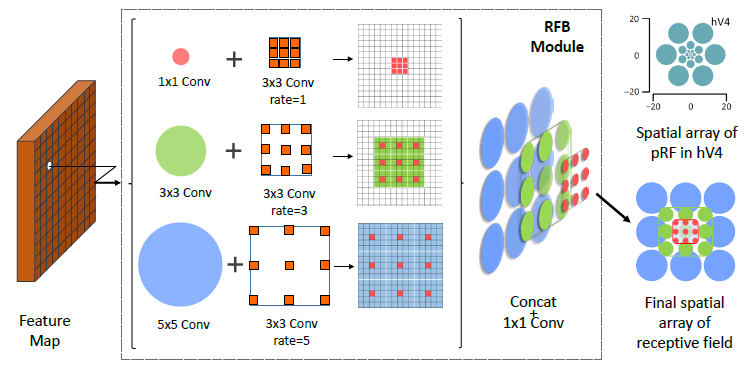
结论
- RFBNe t将 RFB 模块集成到了 SSD 中,在没有使用 ResNet-101 的前提下,可以达到两阶网络的检测精度。同时,RFBNet 还尝试使用了更轻量化的网络,如 MobileNet,检测效果仍然很好,证明了该算法具有较强的泛化能力
- 总体来讲,RFBNet 同时实现了较好的检测性能与较快的速度,并且实现简单,是一个非常优雅的物体检测算法
参考文献
- 《深度学习之 PyTorch 物体检测实战》
- code: https://github.com/amdegroot/ssd.pytorch
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/291206
推荐阅读
相关标签

