
- 1Mac 安装MySQL5.7 安装redis4.0 安装Tomcat8 备忘_sudo: firewall-cmd: command not found
- 2Qt常用的按钮控件编程(一)-- Push Button按钮_qt push
- 3三面蚂蚁惨败,面试官要求手写算法?看完你还觉得算法不重要?_高德三面写算法吗
- 4公司安防工程简要介绍及系统需求分析
- 5鸿蒙项目二—— 注册和登录_router.getparams()as{username:string,password:stri
- 6Android Studio 每次新创建项目,重新下载gradle的解决_重新下载 gradle 压缩包
- 7ElasticSearch 中文分词器对比_elasticsearch 中文分词器哪个好用
- 8毕设分享 基于STM32的毕业设计题目项目汇总 - 100例_基于stm32的100个毕业设计
- 9Android:gradle 插件版本号与gradle 版本号对应关系_gradle:3.1.2
- 10Matlab归一化实现_normalize255 matlab
YOLOv8改进-bifpn_yolov8改进bifpn
赞
踩
目录
1. BiFPN论文简介
论文《EfficientDet: Scalable and Efficient Object Detection》地址:https://arxiv.org/abs/1911.09070
BiFPN 全称 Bidirectional Feature Pyramid Network 加权双向(自顶向下 + 自低向上)特征金字塔网络。
加入BIFPN加权双向金字塔结构,提升不同尺度的检测效果。
1.1 FPN是什么
FPN,Feature Pyramid Networks,特征金字塔网络。用来处理多尺度(不同大小)物体检测问题。
1.2 FPN包括哪些部分
FPN依赖backbone,包括自底向上、横向连接、自顶向下、特征融合,特征整合。
自底向上:Resnet特征提取(feature map),例如:C2, C4
横向连接:将C2到C4的特征利用 1x1 卷积进行整合,也就是通道变换,例如:Conv2D 1x1, s1
自顶向下:高层feature map上采样,例如Upsample
特征融合:将自顶向下上采样的channel与横向连接后的channel 相加(注意:它俩通道数相同,尺寸相同),例如 :+。注意:有的特征融合部分不是相加,而是concat拼接,例如YOLOv3。
特征整合:融合后的特征,利用卷积进行整合。例如:Conv2D 3x3, s1
1.3 FPN特征融合的思想
- 低层的feature map包含更多的定位细节,高层的feature map包含更多的目标特征信息
- 把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
1.4 BiFPN解读
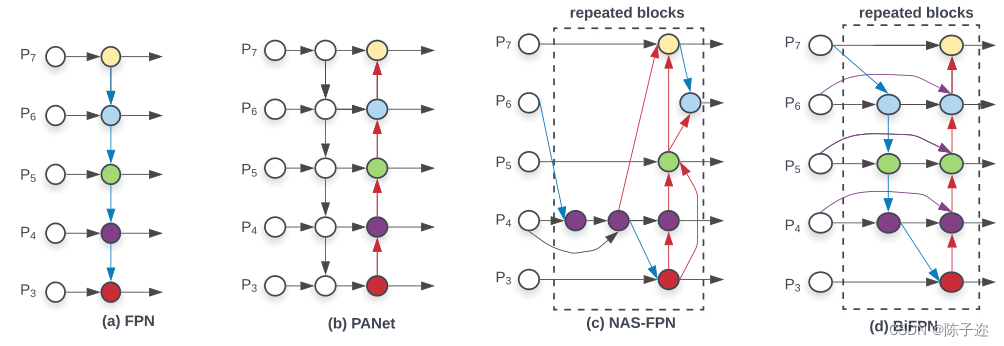
BiFPN是一种改进版的FPN网络结构,主要用于目标检测任务。该结构是加权且双向连接的,即自顶向下和自底向上结构,通过构造双向通道实现跨尺度连接,将特征提取网络中的特征直接与自下而上路径中的相对大小特征融合,保留了更浅的语义信息,而不会丢失太多的深层语义信息。
传统的特征融合时将尺度不同的特征图以相同权重进行加权,但是当输入的特征图分辨率不同时,以相同的权重进行加权对输出的特征图不平等。所以BiFPN根据不同输入特征的重要性设置不同的权重,同时反复采用这种结构来加强特征融合。
BiFPN结构中的加权融合方式采用快速归一化融合(Fast normalized fusion),该融合方式是针对训练速度慢提出的,将权重放缩至0~1范围内,因没有使用Softmax方式,所以训练速度很快。跨尺度连接通过添加一个跳跃连接和双向路径来实现,自此实现了加权融合和双向跨尺度连接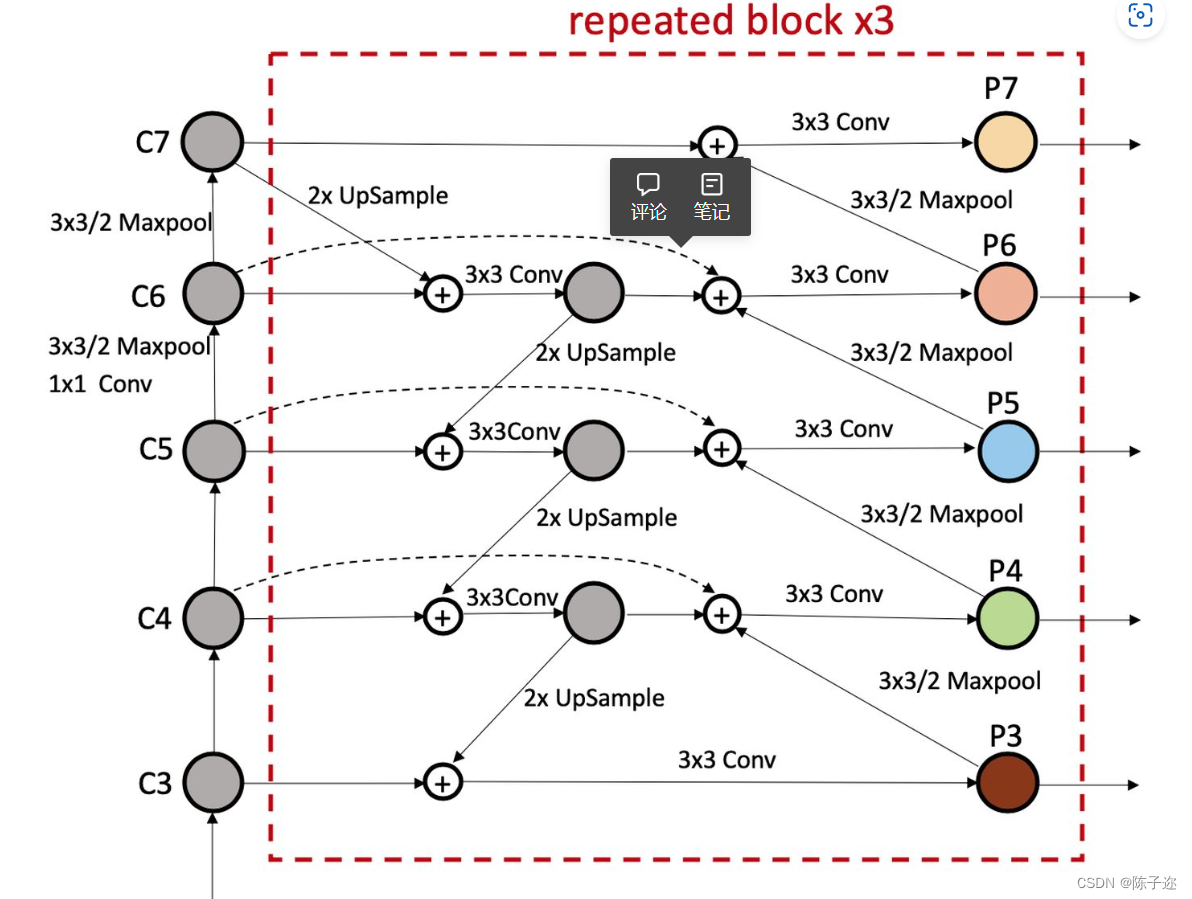

2.YOLOv8改进
2.1 conv中加入
- # 结合BiFPN 设置可学习参数 学习不同分支的权重
- # 两个分支concat操作
- class BiFPN_Concat2(nn.Module):
- def __init__(self, dimension=1):
- super(BiFPN_Concat2, self).__init__()
- self.d = dimension
- self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
- self.epsilon = 0.0001
-
- def forward(self, x):
- w = self.w
- weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
- # Fast normalized fusion
- x = [weight[0] * x[0], weight[1] * x[1]]
- return torch.cat(x, self.d)
-
-
- # 三个分支concat操作
- class BiFPN_Concat3(nn.Module):
- def __init__(self, dimension=1):
- super(BiFPN_Concat3, self).__init__()
- self.d = dimension
- # 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
- # 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
- # 从而在参数优化的时候可以自动一起优化
- self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
- self.epsilon = 0.0001
-
- def forward(self, x):
- w = self.w
- weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
- # Fast normalized fusion
- x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
- return torch.cat(x, self.d)
2.2 修改init.py
修改task 注册bifpn
- # 添加bifpn_concat结构
- elif m in [Concat, BiFPN_Concat2, BiFPN_Concat3]:
- c2 = sum(ch[x] for x in f)
2.3 配置yaml文件
- # Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/248802推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

