
- 1slideViewerPro使用配置说明
- 2安卓手机格式化怎么弄_一加6/7/7Pro怎么从氢OS安卓10降级安卓9系统-完美降级教程...
- 3kali联网(桥接,nat和仅主机模式都有)
- 4Bearpi开发板之HarmonyOS任务管理_鸿蒙线程的等待事件标志时
- 5推荐系统-排序算法:GBDT+LR_gbdp+lr 做排序
- 6关于Clang
- 7disabled什么意思中文翻译,js中disabled是什么意思_05:47 8.00kb/s 5g5g 98不周山上,一老一少,相对而立。“徒儿,你还记得你‘妻
- 8论文阅读:CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrim_cdc (convolutional-de-convolutional networks
- 9【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)
- 10全球首发!总结七十余种开源数据集,一览自动驾驶开源数据体系
【深度学习系列(六)】:RNN系列(6):使用TextCNN实现对文本的分类_一维池化层
赞
踩
我们知道在卷积神经网络不仅用于图像处理领域,在NLP领域也会有很好的使用效果,其中TextCNN是卷积神经网络在文本处理方面的一个知名的模型。在TextCNN模型中通过卷积技术实现对文本的分类功能。目前文本分类在工业界的应用场景非常普遍,从新闻的分类、商品评论信息的情感分类到微博信息打标签辅助推荐系统,都用到了这种技术。下面我们主要了解这个模型的实战以及注意点。
目录
一、卷积神经网络
1.1、一维卷积层
在介绍模型前我们先来解释一维卷积层的工作原理。与二维卷积层一样,一维卷积层使用一维的互相关运算。在一维互相关运算中,卷积窗口从输入数组的最左方开始,按从左往右的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。如图所示,输入是一个宽为 7 的一维数组,核数组的宽为 2。可以看到输出的宽度为 7−2+1=6,且第一个元素是由输入的最左边的宽为 2 的子数组与核数组按元素相乘后再相加得到的:0×1+1×2=2。

多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。下图展示了含 3 个输入通道的一维互相关运算,其中阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:0×1+1×2+1×3+2×4+2×(−1)+3×(−3)=2。
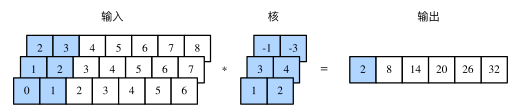
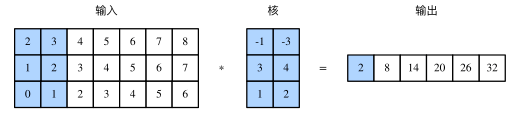
由二维互相关运算的定义可知,多输入通道的一维互相关运算可以看作单输入通道的二维互相关运算。如图所示,我们也可以将图中多输入通道的一维互相关运算以等价的单输入通道的二维互相关运算呈现。这里核的高等于输入的高。图中的阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:2×(−1)+3×(−3)+1×3+2×4+0×1+1×2=2。
1.2、一维池化层
类似地,我们有一维池化层。TextCNN 中使用的时序最大池化(max-over-time pooling)层实际上对应一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。
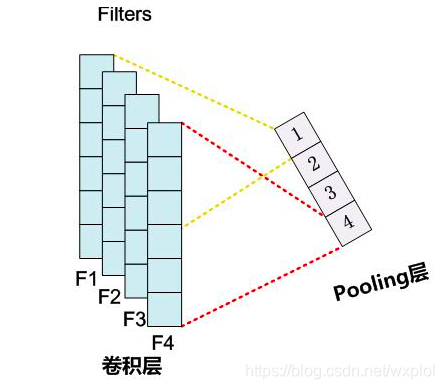
为提升计算性能,我们常常将不同长度的时序样本组成一个小批量,并通过在较短序列后附加特殊字符(如0)令批量中各时序样本长度相同。这些人为添加的特殊字符当然是无意义的。由于时序最大池化的主要目的是抓取时序中最重要的特征,它通常能使模型不受人为添加字符的影响。
参考连接:
二、TextCNN 模型
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 (见参考[1]) 中提出。是2014年的算法。因为卷积神经网络具有提取局部特征的功能,所以可以使用卷积神经网络来提取句子中的类似n-gram算法的关键信息,因此可以理解为通过句子的关键信息进行语义分类。
2.1、模型结构
该模型结构可以分为以下4层:
- 词嵌入层:将每一个词对应的向量转化为多维度的嵌入向量。将每一个句子当作一幅图片进行处理;
- 多通道卷积层:使用2、3、4等不同的卷积核对词嵌入转化后的句子进行卷积操作,生成不同的特征数据;
- 多通道全局最大池化层:对多通道卷积层中输出的每一个通道特征作全局最大池化;
- 全连接层:将池化后的结果如入全链接网络,输出分类个数,得到最终分类结果。
如下图所示,为TextCNN模型的结构图:

卷积层与池化层在分类模型的核心作用就是特征提取的功能,从输入的定长文本序列中,利用局部词序信息,提取初级的特征,并组合初级的特征为高级特征,通过卷积与池化操作,省去了传统机器学习中的特征工程的步骤。但TextCNN的一个明显缺点就是,卷积、池化操作丢失了文本序列中的词汇的顺序、位置信息,比较难以捕获文本序列中的否定、反义等语义信息。
参考连接:
三、TextCNN 模型实战-分析评论者是否满意
3.1、数据预处理
本例使用的数据集为康奈尔大学发布的电影评价数据集,具体链接如下:
链接: https://pan.baidu.com/s/1QBYjRjcO8MP3XFCwUPkz1g 密码: 5d40
该数据集包含两个文件rt-polarity.neg和rt-polarity.pos,其分别包含5331个正面的评论和5331个负面的评论,具体文件如下图所示。
3.1.1、数据预处理
这里我们使用preprocessing接口来进行NLP任务的数据预处理。该模块位于Tensorlow中的contrib模块中的learn子模块中。但是在Tensorflow2.x版本之后已经没有了该模块。由于preprocessing模块的接口完全由python来实现,与Tensorflow框架无关,其完全独立与Tensorflow,所以我们可以手动的将preprocessing模块单独复制到我们的工程中。具体做法如下:将整个precessing文件夹复制出来,放到本地代码同级目录下,然后从本地加载该模块。这里我们提供了该模块的下载地址,只需下载好后复制代工程目录中即可。具体链接如下:
链接: https://pan.baidu.com/s/18as6CVFQ4dFm6hTtsXV4xQ 密码: cmkd
当然,该接口在tf.keras已经有相关使用方法,具体使用可以参考以下链接:
这里我们需要将字符数据集样本转化为字典和向俩数据,具体实现如下:
- import tensorflow as tf
- import numpy as np
- import preprocessing
-
- def load_data(positive_data_file,negative_data_file):
- '''加载数据'''
- file_list = [positive_data_file, negative_data_file]
-
- def get_line(file_list):
- for file in file_list:
- with open(file,'r',encoding='utf-8') as fp:
- for line in fp:
- yield line
-
- x_text=get_line(file_list)#获取文本行
- lenlist=[len(x.split(" ")) for x in x_text]#获取每一行长度
- max_len=max(lenlist)#计算最大长度
-
- #实例化VocabularyProcessor类
- vocab_processor = preprocessing.VocabularyProcessor(max_len, 5)
- x_text = get_line(file_list)
-
- # 并将文本转化为向量
- doc=list(vocab_processor.transform(x_text))
- # 生成字典
- dict=list(vocab_processor.reverse([list(range(0, len(vocab_processor.vocabulary_)))]))
-
- return doc,vocab_processor,dict,max_len
-
-
- def dataset(positive_data_file,negative_data_file,batch_size=256):
- '''生成数据集'''
- #读取数据集
- doc,vocab_processor,dict,max_len=load_data(positive_data_file,negative_data_file)
- # 生成one_hot标签
- labels=[]
- lenlist=len(doc)
- for i in range(lenlist):
- if i< lenlist/2:
- labels.append(np.array([1,0]))
- else:
- labels.append(np.array([0,1]))
-
- data=tf.compat.v1.data.Dataset.from_tensor_slices((doc,labels))
- data=data.shuffle(lenlist)
- data=data.batch(batch_size,drop_remainder=True)
- data=data.prefetch(tf.data.experimental.AUTOTUNE)
- return data,vocab_processor,max_len #返回数据集、字典、最大长度

这里我们可以使用vocab_processor.vocabulary_来获取字典,具体实现如下:
print("字典:",list(vocab_processor.reverse([list(range(0, len(vocab_processor.vocabulary_)))])))结果如下:

3.2、TextCNN模型搭建
前面我们已经详细介绍了TextCNN模型的组成,这里不多介绍,直接使用tensorflow来实现,具体代码如下:
- import tensorflow as tf
-
- def TextCNN(seq_length,num_classes,vocab_size,embeding_size,filter_sizes,num_filters,dropout_keep_prob=0.8):
- '''构建TextCNN模型'''
- input_x=tf.keras.layers.Input([seq_length])
-
- # 词嵌入层
- out=tf.keras.layers.Embedding(vocab_size,embeding_size)(input_x)
- out=tf.expand_dims(out,-1)
-
- # 定义多通道卷积和最大池化层
- pooled_output=[]
- for i ,filter_size in enumerate(filter_sizes):
- conv=tf.keras.layers.Conv2D(num_filters,
- kernel_size=[filter_size,embeding_size],
- strides=1,padding='valid',
- activation='relu',
- name="conv%s"%filter_size)(out)
-
- pooled=tf.keras.layers.MaxPooling2D(pool_size=[seq_length-filter_size+1,1],
- padding='valid',
- name="pool%s"%filter_size)(conv)
-
- pooled_output.append(pooled)#将各通道的结果合并起来
-
- #展开特征,并添加dropout方法
- num_filters_total=num_filters*len(filter_sizes)
- h_pool=tf.concat(pooled_output,3)
- h_pool_flat=tf.reshape(h_pool,[-1,num_filters_total])
-
- out=tf.keras.layers.Dropout(rate=dropout_keep_prob,name="dropout")(h_pool_flat)
-
- out=tf.keras.layers.Dense(num_classes,activation='softmax',name="fully_connecred")(out)
-
- model=tf.keras.Model(inputs=input_x,outputs=out,name="textcnn")
-
- return model
这里我们打印模型如下:

3.3、模型训练
这里我们直接使用tf.keras接口来实现,具体实现代码如下:
- def train():
- # 指定样本文件
- positive_data_file = "./rt-polaritydata/rt-polarity.pos"
- negative_data_file = "./rt-polaritydata/rt-polarity.neg"
- # 设置训练参数
- num_steps = 50 # 定义训练次数
- SaveFileName = "text_cnn_model" # 定义保存模型文件夹名称
- # 设置模型参数
- num_classes = 2 # 设置模型分类
- l2_reg_lambda = 0.1 # 定义正则化系数
- filter_sizes = "3,4,5" # 定义多通道卷积核
- num_filters = 64 # 定义每通道的输出个数
-
- # 加载数据集
- data,vocab_processor,max_len=dataset(positive_data_file,negative_data_file)
- #搭建模型
- text_cnn=TextCNN(seq_length=max_len,
- num_classes=num_classes,
- vocab_size=len(vocab_processor.vocabulary_),
- embeding_size=128,filter_sizes=list(map(int,filter_sizes.split(','))),
- num_filters=num_filters)
-
-
- def l2_loss(y_true, y_pred):
- l2_loss=tf.constant(0.0)
- for tf_var in text_cnn.trainable_weights:
- if tf_var.name == "fully_connecred":
- l2_loss+=tf.reduce_mean(tf.nn.l2_loss(tf_var))
-
- loss=tf.nn.softmax_cross_entropy_with_logits(logits=y_pred,labels=y_true)
- return loss+l2_reg_lambda*l2_loss
-
-
- text_cnn.compile(loss=l2_loss,
- optimizer=tf.keras.optimizers.Adam(lr=1e-3),
- metrics=['acc'])
- text_cnn.fit(data,epochs=num_steps)
-
- text_cnn.save("textcnn.h5")
-
- train()
最终训练结果:
四、TextCNN 模型优化技巧
将CNN中的技术运用到文本分类上一般会产生好的效果,这里主要列举下TextCNN模型进一步提升精度的方法:
- 使用类似Inception系列模型的cell代替多通道卷积:TextCNN模型的结构与Inception系列模型的单元结构类似。所以,可以考虑使用标准Inception系列的模型cell(或NASNet模型的cell)来处理多通道卷积部分,如果句子较长,则可以在通道中尝试使用更大的卷积核。
- 将最大池化替换为空洞卷积:最大池化过程中会丢失很多重要的信息。所以,可以尝试使用空洞卷积的方法来让模型减少信息损失。
- 更好的使用词嵌入:在模型中使用词嵌入是从头开始训练的,在样本不足的情况下,模型的范化能力较差。可以在词嵌入的训练过程中,引入已经训练好的公开词向量对词嵌入层进行初始化;还可以直接使用已经训练好的公开词向量将输入转化为向量特征来训练后面的模型。
- 一些小tip技巧提升模型精度:比如:改变激活函数、改变优化器、调节学习率、调节dropout率以及增加每个通道的输出个数等。

