
- 1关于android studio 下载第三方库的时速度慢或下载不下来的问题_android studio后台下载不动
- 2C++实现的windows系统下的WIFI管理_windows wifi native开发
- 3WSL 2 网络配置_wsl2 网络配置
- 4EOS源码备忘-Push Transaction机制_pushtransaction 唤醒tp签名
- 5白帽子实战之高阶安全挑战:操作系统与安全设备的漏洞利用_axman fuzzer
- 6为什么编译boost时,最后提示...failed updating 6 targets... ...skipped 6 targets... ...updated 1092 targets......
- 7裸机编程的几种模式、架构与缺陷。
- 8贪心算法--Leetcode刷刷刷
- 9Android最全面试题整理、还有Kotlin_kotlin面试题
- 10《Diffusion Models Paper》1.0 经典必读论文10篇_diffusion model paper论文
推荐系统-排序算法:GBDT+LR_gbdp+lr 做排序
赞
踩
1. GBDT + LR 是什么
本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题。这个方法出自于Facebook 2014年的论文 Practical Lessons from Predicting Clicks on Ads at Facebook 。
2. GBDT + LR 用在哪
GBDT+LR 使用最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击。
在CTR预估问题的发展初期,使用最多的方法就是逻辑回归(LR),LR使用了Sigmoid变换将函数值映射到0~1区间,映射后的函数值就是CTR的预估值。
LR属于线性模型,容易并行化,可以轻松处理上亿条数据,但是学习能力十分有限,需要大量的特征工程来增加模型的学习能力。但大量的特征工程耗时耗力同时并不一定会带来效果提升。因此,如何自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期,是亟需解决的问题。
FM模型通过隐变量的方式,发现两两特征之间的组合关系,但这种特征组合仅限于两两特征之间,后来发展出来了使用深度神经网络去挖掘更高层次的特征组合关系。但其实在使用神经网络之前,GBDT也是一种经常用来发现特征组合的有效思路。
CTR预估的模型训练分为离线训练(offline)、在线训练(online),其中离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,若出现这种情况,可选择使用Online-Learning来在线更新模型:
2.1 离线部分

- 数据收集:收集和业务相关的数据,如在app位置进行埋点
- 预处理
- 构造数据集:切训练、测试、验证集
- 特征工程:对原始数据进行基本的特征处理,包括去除相关性大的特征,离散变量one-hot,连续特征离散化
- 模型选择:选择合理的机器学习模型来完成相应工作,原则是先从简入深,先找到baseline,然后逐步优化;
- 超参选择:利用gridsearch、randomsearch或者hyperopt来进行超参选择,选择在离线数据集中性能最好的超参组合;
- 在线A/B Test:选择优化过后的模型和原先模型(如baseline)进行A/B Test,若性能有提升则替换原先模型;
2.2 在线模型

- Cache & Logic:设定简单过滤规则,过滤异常数据;
- 模型更新:当Cache & Logic 收集到合适大小数据时,对模型进行增量训练finetuning,若在测试集上比原始模型性能高,则更新model server的模型参数;
- Model Server:接受数据请求,返回预测结果;
3. GBDT + LR 的结构
正如它的名字一样,GBDT+LR 由两部分组成,其中GBDT用来对训练集提取特征作为新的训练输入数据,LR作为新的训练输入数据的分类器。
GBDT和LR的融合方案,FaceBook的paper中有个例子:
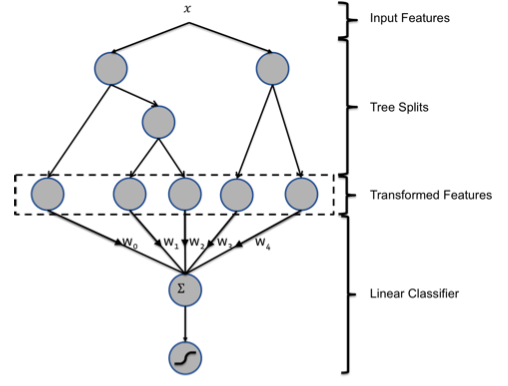
图中共有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR的一个特征。构造的新特征向量(Transformed Features)是取值0/1的。
举例来说:上图有两棵树(即两个弱分类器),左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为input,输入到LR中进行分类。在对原始数据进行GBDT提取为新的数据这一操作之后,数据不仅变得稀疏,而且可能会导致新的训练数据特征维度过大的问题,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
4. GBDT+LR代码实践
本文使用lightgbm包来训练我们的GBDT模型,训练共100棵树(即100个弱分类器),每棵树有64个叶子结点(Transformed Features 有64*100维)
- df_train = pd.read_csv('data/train.csv')
- df_test = pd.read_csv('data/test.csv')
-
- NUMERIC_COLS = [
- "ps_reg_01", "ps_reg_02", "ps_reg_03",
- "ps_car_12", "ps_car_13", "ps_car_14", "ps_car_15",
- ]
-
-
- y_train = df_train['target'] # training label
- y_test = df_test['target'] # testing label
- X_train = df_train[NUMERIC_COLS] # training dataset
- X_test = df_test[NUMERIC_COLS] # testing dataset
-
- # create dataset for lightgbm
- lgb_train = lgb.Dataset(X_train, y_train)
- lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
-
- params = {
- 'task': 'train',
- 'boosting_type': 'gbdt',
- 'objective': 'binary',
- 'metric': {'binary_logloss'},
- 'num_leaves': 64,
- 'num_trees': 100,
- 'learning_rate': 0.01,
- 'feature_fraction': 0.9,
- 'bagging_fraction': 0.8,
- 'bagging_freq': 5,
- 'verbose': 0
- }
-
- # number of leaves,will be used in feature transformation
- num_leaf = 64
-
- # train
- gbm = lgb.train(params,
- lgb_train,
- num_boost_round=100,
- valid_sets=lgb_train)
-
- # save model to file
- gbm.save_model('model.txt')

在训练得到100棵树之后,我们需要得到的不是GBDT的预测结果,而是每一条训练数据落在了每棵树的哪个叶子结点上,因此需要使用下面的语句:
- y_pred = gbm.predict(X_train, pred_leaf=True)
- print(np.array(y_pred).shape)
- print(y_pred[0])
打印上面结果的输出,可以看到shape是(8001,100),其中8001是训练集的样本个数,100是因为有100棵树(aka. 弱分类器)
- (8001, 100)
- [[43 26 47 47 47 19 36 19 50 52 29 0 0 0 46 23 13 27 27 13 10 22 0 10
- 4 57 17 55 54 57 59 42 22 22 22 13 8 5 27 5 58 23 58 14 16 16 10 32
- 60 32 4 4 4 4 4 46 57 48 57 34 54 6 35 6 4 55 13 23 15 51 40 0
- 47 40 10 29 24 24 31 24 55 3 41 3 22 57 6 0 6 6 57 55 57 16 12 18
- 30 15 17 30]]
每个值就是当前输入x落到了哪个叶子上,是[0,64]之间的值。
我们需要将每棵树的特征进行one-hot处理,如前面所说,假设第一棵树落在43号叶子结点上,那我们需要建立一个64维的向量,除43维之外全部都是0。因此用于LR训练的特征维数共num_trees * num_leaves = 100 * 64。
之后我们可以用转换后的训练集特征和label训练我们的LR模型。
一些说明
为什么建树采用GBDT而非RF:RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。

