
- 1Linux X86_64位虚拟地址空间布局与试验_linux blitz64
- 2Jetson Xavier NX套件 Ubuntu 源码编译安装Qt5.15.6_xavier安装qt环境
- 3一张厚度为0.1MM的纸对折多少次后,高度超过珠穆朗玛峰(8848米)?_c#一张纸 厚度0.1cm 折叠多少次, 高度超过 珠穆朗玛峰?
- 4一文带你了解如何在Java中操作Redis_java redis
- 5uniapp 微信浏览器打开外部APP_uninapp在微信中打开app
- 6mathtype7 正版官网 宣布免费使用_mathtype官网
- 7学人工智能电脑配置要求高吗?多少钱能搞定?_ai程序运行 机器的要求
- 8限流算法之----滑动窗口_滑动窗口限流算法
- 9Java课程设计——计算器_java gui 设计一个计算器,能够实现整数的+、-、×、/ 四 种运算
- 10Android Studio进入Chrome浏览器卡顿以及无法下载图片问题_android studio虚拟的手机打开谷歌浏览器整个电脑卡死怎么回事
visio形成数据字典_学习之大数据项目笔记第六篇【数仓模块-ID-MAPPING】
赞
踩
1 id-mapping概述
在后续的数仓、画像、推荐等模块开发中,我们都需要对每一条行为日志数据标记用户的唯一标识!
简单的方案是
将这条数据中的uid/imei码/imsi码/mac/androidid/uuid这些字段(标识字段)按优先级取一个标识,作为这条数据的用户唯一标识!
这个方案有严重的漏洞!
现实的是
在现实的日志数据中,由于,用户可能使用各种各样的设备,有着各种各样的前端入口,甚至同一个用户拥有多个设备以及使用多种前端入口,就会导致,日志数据中对同一个人,不同时间段所收集到的日志数据中,可能取到的标识个数、种类各不相同;
比如:
用户可能使用各种各样的设备:
1)手机、平板电脑
2)安卓手机、ios手机、winphone手机
3)安卓系统有各种版本 ( 5.0 6.0 7.0 8.0 9.0 )
4)ios系统也有各种版本(3.x 4.x 5.x 6.x 7.x .... 12.x )
产生问题:
用户设备的标识,没办法轻易定制一个规则来取某个作为唯一标识:
mac:手机网卡物理地址, 若干早期版本的ios,winphone,android可取到
imei(入网许可证序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
imsi(手机SIM卡序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
androidid :安卓系统id
openuuid(app自己生成的序号) :卸载重装app就会变更
idfa(广告跟踪码)
deviceid(app日志采集埋点开发人员自己定义一种逻辑id,可能取自 android,imei,openudid等):逻辑上的id
从而导致:
有一些数据中,用户有登录账号,而有些没有;
有一些数据中,有imei码,mac地址;而有些则有mac地址和android;
前一日的数据中,有uid,android,而后一日数据中有android,mac地址
在这些情况中,如果按照之前的方案来生成数据的唯一标识,显然错漏百出!
如下图:

要从这些纷繁复杂的各类id中,分辨出哪些id属于同一个受众(设备),用普通的“where x=y”这种简单条件逻辑很难实现。
2 id-mapping技术方案
3 id-mapping技术手段1:借助redis
可以借助外部存储,比如redis,来实现idmapping
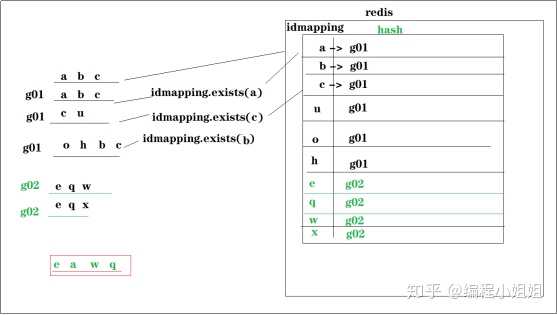
1). 从日志数据中抽取各种标识id
2). 将提取出的标识id,去redis标识id库中查询是否存在
3). 如果不存在,则新建一个"统一标识"+"id set"
4). 如果已存在,则使用已存在的统一标识
=== 考虑一个很无奈的问题 ====
有些数据可能属于同一个人,但在某个阶段上,这些数据之间没有任何联系,那么这人的数据可能会被打上两个不同的标识!
一点点修补措施: 定期对redis的id映射库进行整理合并!
但是合并,又可能带来另一个问题:两个不同的人被打上相同唯一标识(guid)
4 id-mapping技术手段2:借助图计算
采用图计算手段,来找到各种id标识之间的关联关系,从而识别出哪些id标识属于同一个人;
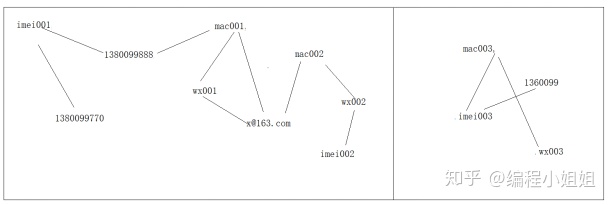
图计算的核心思想:
将数据表达成“点”,点和点之间可以通过某种业务含义建立“边”
然后,我们就可以从点、边上找出各种类型的数据关系:
比如连通性;
比如最短路径规划;
- id_mapping(id打通)的最后目标,就是形成一个id映射字典:
- id ---- guid
- idx01 -> gid01
- idy01-> gid01
- idz01 -> gid01
- idx02 -> gid01
-
- idx02,idy2,idz02,idx13 -> gid02
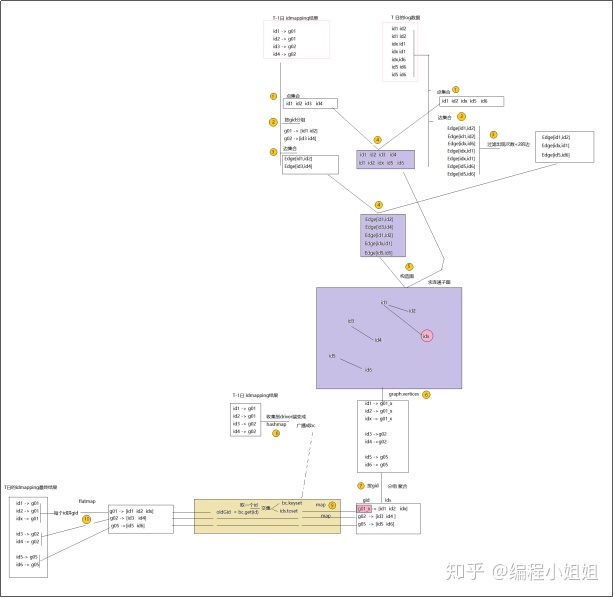
整体流程:
1). 将当日数据中的所有用户标识字段,及标志字段之间的关联,生成点集合 、边集合
2). 将上一日的ids->guid的映射关系,也生成点集合、边集合
3). 将上面两类点集合、边集合合并到一起生成一个图
4). 再对上述的图执行“最大连通子图”算法,得到一个连通子图结果
5). 在从结果图中取到哪些id属于同一组,并生成一个唯一标识
6). 将上面步骤生成的唯一标识去比对前日的ids->guid映射表(如果一个人已经存在guid,则沿用原来的guid)
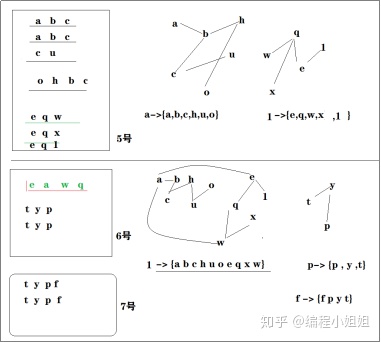
5 id-mapping开发实现
5.1 开发目标
将(pc端埋点日志、app端埋点日志、小程序端埋点日志)数据中的各种id标识字段提取出来,用图计算的连通子图算法,求出哪些id标识属于同一个人;
- 目标结果形式:
- id-mapping字典:
- gid01 : [imei01 , imei03 ,13888997766 ,andorid03,mac03 ]
5.2 整体逻辑
1). 抽取3类数据中的各种id字段,映射成“点”集合和“边”集合
2). (可选)过滤掉出现次数低于某个阈值(10次)的“边”
3). 在结合T-1日的idmapping字典,构造一个图模型
4).求最大连通子图,得到T日的临时结果
5).整理临时结果(去T-1日的idmapping中匹配已经存在的gid)以便保持gid的延续性!
gid -> imei01,idfa01,mac01
图计算算法应用基本步骤跟前面章节入门案例基本一致
(抽各id,得到一个id数据集合,然后再映射出点集合、边集合,再构造图模型,再调连通子图算法,取结果加工);
5.3 重点细节问题
有一些现实情况需要考虑,比如:
1) 假如一个人偶尔用他朋友的手机登录过一次,则会出现他的uid跟他朋友的各设备id之间产生关联。
- 13800001100,zss,imei000,android000
- 13800001100,zss,imei000,android000
- 13800001100,zss,imei000,android000
- 13800001100,zss,imei000,android000
- 13800001100,zss,imei000,android000
- 13800001100,zss,imei000,android000
- 13800002211,zss,imei002,android002
- 13800002211,zss,imei002,android002
- 13800002211,tqq,imei002,android002
- 13800002211,tqq,imei002,android002
- 13800002211,tqq,imei002,android002
2) id-mapping计算,需要逐日滚动进行,这就涉及到T日的数据与T-1日的id-mapping字典数据之间的合并问题(难在需要将之前生成好的“图id”保持一贯)
3) 一个用户的某些id标识,如果持续不再“出现”,应该持续衰减其权重值,权重值低于指定阈值后可以考虑过滤去除(本需求暂时放入下期迭代时实现)
5.4 滚动计算方案
day=1:
1)抽取当天各类数据中的id,并映射出“点集合”和“边集合”
2)对“边集合”进行聚合计数,过滤掉(频次<阈值)的边(作用:过滤偶然性“噪点”干扰)
3)用过滤后的边构造图
3)用图计算连通子图算法,对id标识聚合打通,得到“gid<=>各id标识” id-mapping映射字典
day=2:
1)抽取当天各类数据中的id,并映射出“点集合VertextC1”和“边集合”
2)对当天“边集合”进行聚合计数,过滤掉(频次<阈值)的边,得到“边集合”EdgeC1
3)对T-1日的id-mapping结果,重新映射成“点VertextC2、边集合EdgeC2”
4)将上述两个“点、边集合”合并,并构造图
5)对合并图执行连通子图计算,得到新的id-mapping结果
6)将新id-mapping跟旧的id-mapping进行合并操作(可能有新增组,可能有旧组新增id)
(考虑情况:新id新组;新id旧组)
day>=3:重复day_2的流程
5.5 实现流程图
主体流程
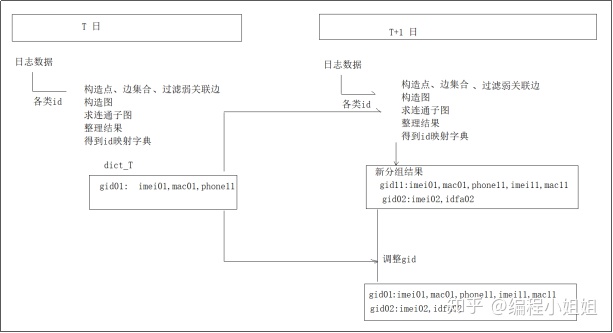
细节流程
5.6 代码实现
多种来源的数据:
web端埋点日志
app端埋点日志
微信小程序埋点日志
步骤:
1). 加载当日的这几类数据
2). 提取出每类数据中的每一行中的各种用户标识(uid,imei,mac,androidid,uuid,imsi.....)
3). 根据提取出来的这些标识,生成图计算中的vertex集合,以及生成图计算中的Edge集合
4). 然后将点集合和边集合,构造一张图Graph
5). 然后调用图的算法(最大连通子图算法),得到结果图
6). 然后从结果图上,取所有的点集合(就是映射结果)
7). 整理结果,成为我们想要的形式
5.7 最终结果形式
- (id映射字典—idmapping字典):
- imei01:gid01
- mac01:gid01
- idfa01:gid01
- uuid01:gid01
- 138002:gid02
- imei02:gid02
- android02:gid02

