
热门标签
热门文章
- 1Flink elasticsearch-sink by http and https_elasticsearch7sinkbuilder
- 2软件测试方法——等价类划分法详解_软件测试等价划分,字节软件测试面试必问_软件测评师等价类
- 3基于python的语音识别系统,Python语音识别技术路线_python 语音识别系统 毕设
- 4sklearn -- 线性回归_sklearn linearregression
- 5Spring Boot + Freemaker 打包成jar 出现无法生成pdf_java jar包里面放pdf文件不生效
- 6超详细版本|Linux Centos7从零搭建Hadoop集群及运行MapReduce分布式集群案例(全网最详细教程!)_centos linux 7
- 7【消息】GPT4有多强?_gtp4
- 809|代理(上):ReAct框架,推理与行动的协同_react 推理
- 9无人机之遥控器保养
- 10阿里架构师带你彻底了解docker,微服务为什么一定要用docker?_微服务必须用docker吗
当前位置: article > 正文
DataFrame实战-----数据规整化之USDA食品数据库-----python数据分析_usda食品营养数据库
作者:人工智能uu | 2024-07-26 07:57:10
赞
踩
usda食品营养数据库
目录
文件下载地址
美国农业部USDA制作一份有关食物营养的数据库。由Ashley Williams制作出JSON版。
https://raw.githubusercontent.com/wesm/pydata-book/2nd-edition/datasets/usda_food/database.json
*文件比较大,建议先下载好在导进去而不是复制进编译器

- >>> import json
- >>> db = json.load(open('D:\python\DataAnalysis\data\database.json'))
- >>> len(db)
- 6636
- >>> db[0].keys()
- [u'portions', u'description', u'tags', u'nutrients', u'group', u'id', u'manufacturer']
- >>> db[0]['nutrients'][0]
- {u'units': u'g', u'group': u'Composition', u'description': u'Protein', u'value': 25.18}
抽取数据
在转为DataFrame时,可以只抽取一部分字段,这里取出食物的名称,分类,编号及制造商信息
- >>> from pandas import DataFrame,Series
- Backend TkAgg is interactive backend. Turning interactive mode on.
- >>> info_keys = ['description','group','id','manufacturer']
- >>> info = DataFrame(db,columns=info_keys)
- >>> info[:5]
- description ... manufacturer
- 0 Cheese, caraway ...
- 1 Cheese, cheddar ...
- 2 Cheese, edam ...
- 3 Cheese, feta ...
- 4 Cheese, mozzarella, part skim milk ...
-
- [5 rows x 4 columns]
通过value_counts查看食物类别的分布情况:
- >>> import pandas as pd
- >>> pd.value_counts(info.group)
- Vegetables and Vegetable Products 812
- Beef Products 618
- Baked Products 496
- Breakfast Cereals 403
- Legumes and Legume Products 365
- Fast Foods 365
- Lamb, Veal, and Game Products 345
- Sweets 341
- Fruits and Fruit Juices 328
- Pork Products 328
- Beverages 278
- Soups, Sauces, and Gravies 275
- Finfish and Shellfish Products 255
- Baby Foods 209
- Cereal Grains and Pasta 183
- Ethnic Foods 165
- Snacks 162
- Nut and Seed Products 128
- Poultry Products 116
- Sausages and Luncheon Meats 111
- Dairy and Egg Products 107
- Fats and Oils 97
- Meals, Entrees, and Sidedishes 57
- Restaurant Foods 51
- Spices and Herbs 41
- Name: group, dtype: int64

分析过程
现在,为了对全部营养数据做一些分析,最简单的办法是将所有食物的营养成分整合到一个大表中,我们分步骤实现该目的。
首先将各食物的营养成分列表转换为一个DataFrame,并添加一个表示编号的列,然后将该DataFrame添加到一个列表中,最后通过concaat将这些东西连接起来。
- >>> nutrients = []
- >>> for rec in db:
- ... fnuts = DataFrame(rec['nutrients'])
- ... fnuts['id'] = rec['id']
- ... nutrients.append(fnuts)
- ... nutrients = pd.concat(nutrients,ignore_index=True)
连接后的nutrients[ ]
- >>> nutrients
- description group ... value id
- 0 Protein Composition ... 25.180 1008
- 1 Total lipid (fat) Composition ... 29.200 1008
- 2 Carbohydrate, by difference Composition ... 3.060 1008
- 3 Ash Other ... 3.280 1008
- 4 Energy Energy ... 376.000 1008
- 5 Water Composition ... 39.280 1008
- 6 Energy Energy ... 1573.000 1008
- 7 Fiber, total dietary Composition ... 0.000 1008
- 8 Calcium, Ca Elements ... 673.000 1008
- 9 Iron, Fe Elements ... 0.640 1008
- 10 Magnesium, Mg Elements ... 22.000 1008
- 11 Phosphorus, P Elements ... 490.000 1008
- 12 Potassium, K Elements ... 93.000 1008
- 13 Sodium, Na Elements ... 690.000 1008
- 14 Zinc, Zn Elements ... 2.940 1008
- 15 Copper, Cu Elements ... 0.024 1008
- 16 Manganese, Mn Elements ... 0.021 1008
- 17 Selenium, Se Elements ... 14.500 1008
- 18 Vitamin A, IU Vitamins ... 1054.000 1008
- 19 Retinol Vitamins ... 262.000 1008
- 20 Vitamin A, RAE Vitamins ... 271.000 1008
- 21 Vitamin C, total ascorbic acid Vitamins ... 0.000 1008
- 22 Thiamin Vitamins ... 0.031 1008
- 23 Riboflavin Vitamins ... 0.450 1008
- 24 Niacin Vitamins ... 0.180 1008
- 25 Pantothenic acid Vitamins ... 0.190 1008
- 26 Vitamin B-6 Vitamins ... 0.074 1008
- 27 Folate, total Vitamins ... 18.000 1008
- 28 Vitamin B-12 Vitamins ... 0.270 1008
- 29 Folic acid Vitamins ... 0.000 1008
- ... ... ... ... ...
- 1168085 Selenium, Se Elements ... 1.100 43546
- 1168086 Vitamin A, IU Vitamins ... 5.000 43546
- 1168087 Retinol Vitamins ... 0.000 43546
- 1168088 Vitamin A, RAE Vitamins ... 0.000 43546
- 1168089 Carotene, beta Vitamins ... 2.000 43546
- 1168090 Carotene, alpha Vitamins ... 2.000 43546
- 1168091 Vitamin E (alpha-tocopherol) Vitamins ... 0.250 43546
- 1168092 Vitamin D Vitamins ... 0.000 43546
- 1168093 Vitamin D (D2 + D3) Vitamins ... 0.000 43546
- 1168094 Cryptoxanthin, beta Vitamins ... 0.000 43546
- 1168095 Lycopene Vitamins ... 0.000 43546
- 1168096 Lutein + zeaxanthin Vitamins ... 20.000 43546
- 1168097 Vitamin C, total ascorbic acid Vitamins ... 21.900 43546
- 1168098 Thiamin Vitamins ... 0.020 43546
- 1168099 Riboflavin Vitamins ... 0.060 43546
- 1168100 Niacin Vitamins ... 0.540 43546
- 1168101 Vitamin B-6 Vitamins ... 0.260 43546
- 1168102 Folate, total Vitamins ... 17.000 43546
- 1168103 Vitamin B-12 Vitamins ... 0.000 43546
- 1168104 Choline, total Vitamins ... 4.100 43546
- 1168105 Vitamin K (phylloquinone) Vitamins ... 0.500 43546
- 1168106 Folic acid Vitamins ... 0.000 43546
- 1168107 Folate, food Vitamins ... 17.000 43546
- 1168108 Folate, DFE Vitamins ... 17.000 43546
- 1168109 Vitamin E, added Vitamins ... 0.000 43546
- 1168110 Vitamin B-12, added Vitamins ... 0.000 43546
- 1168111 Cholesterol Other ... 0.000 43546
- 1168112 Fatty acids, total saturated Other ... 0.072 43546
- 1168113 Fatty acids, total monounsaturated Other ... 0.028 43546
- 1168114 Fatty acids, total polyunsaturated Other ... 0.041 43546
-
- [1168115 rows x 5 columns]
丢弃重复项
- >>> nutrients.duplicated().sum()
- 792939
重命名列对象
- >>> col_mapping = {'description':'food','group':'fgroup'}
- >>> info = info.rename(columns = col_mapping,copy=False)
- >>> col_mapping = {'description':'nutrient','group':'nutgroup'}
- >>> nutrients = nutrients.rename(columns = col_mapping,copy = False)
结合info与nutrients
- >>> ndata = pd.merge(nutrients,info,on='id',how='outer')
- >>> ndata.ix[30000]
- nutrient Folate, food
- nutgroup Vitamins
- units mcg
- value 11
- id 1180
- food Sour cream, fat free
- fgroup Dairy and Egg Products
- manufacturer None
- Name: 30000, dtype: object
接下来利用前面的知识练练手,比如根据食物分类和营养类型画出一张中位值的图。
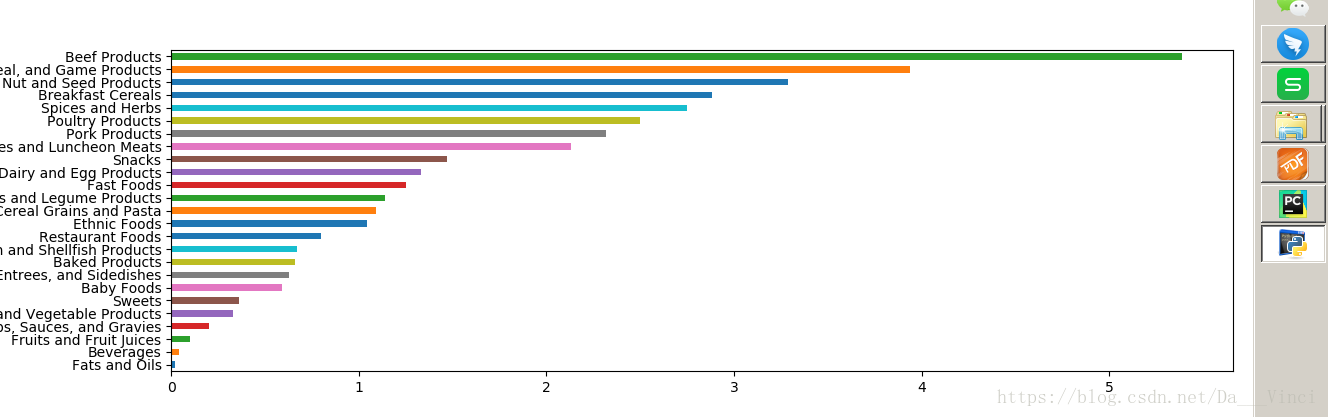
- >>> result = ndata.groupby(['nutrient','fgroup'])['value'].quantile(0.5)
- >>> result['Zinc, Zn'].sort_values().plot(kind='barh')
氨基酸最丰富的食物:
- >>> by_nutrient = ndata.groupby(['nutgroup','nutrient'])
- >>> get_maximum = lambda x: x.xs(x.value.idxmax())
- >>> get_minimum = lambda x: x.xs(x.value.idxmin())
- >>> max_foods = by_nutrient.apply(get_maximum)[['value','food']]
- >>> max_foods.food = max_foods.food.str[:50]
- >>> max_foods.ix['Amino Acids']['food']
- nutrient
- Alanine Gelatins, dry powder, unsweetened
- Arginine Seeds, sesame flour, low-fat
- Aspartic acid Soy protein isolate
- Cystine Seeds, cottonseed flour, low fat (glandless)
- Glutamic acid Soy protein isolate
- Glycine Gelatins, dry powder, unsweetened
- Histidine Whale, beluga, meat, dried (Alaska Native)
- Hydroxyproline KENTUCKY FRIED CHICKEN, Fried Chicken, ORIGINA...
- Isoleucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Leucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Lysine Seal, bearded (Oogruk), meat, dried (Alaska Na...
- Methionine Fish, cod, Atlantic, dried and salted
- Phenylalanine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Proline Gelatins, dry powder, unsweetened
- Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
- Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
- Name: food, dtype: object
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/884272
推荐阅读
相关标签

