
- 1mtd-utils工具的使用_mtd-utils对nor测试
- 2【IT人沟通技巧】如何学会结构化倾听_结构化倾听的案例
- 3数据安全与隐私保护:人工智能与大数据的发展与应用
- 4ChatGPT:人工智能语言模型的革命性进步_gpt系列模型在语言生成与理解中的创新与改进
- 5如何运用 AI 提升产品经理工作效率?_ai工具如何帮助互联网产品经理高效完成实际工作开展
- 6【前端开发】Vue + Fabric.js + Element-plus 实现简易的H5可视化图片编辑器_vue fabric
- 7桥接模式C++实现
- 8python实现改进版冒泡排序_改进的冒泡排序pathony
- 9MySQL面试题大全,MySQL必刷的那些面试题(2024版)
- 10【大语言模型】5分钟快速认识ChatGPT、Whisper、Transformer、GAN_chatgpt whisper
【网络原理】HTTP协议 | 报文格式 | Fiddler抓包 | HTTP请求 | HTTP响应 | 构造HTTP请求_网络报文格式使用方法
赞
踩
HTTP协议
- HTTP超文本传输协议,是一种应用非常广泛的应用层协议。
最新版本是HTTP/3.0,但是目前大规模使用的版本仍是HTTP/1.1
使用HTTP的场景:
1.浏览器打开网站。网页和后台服务器的交互(基本上)
2.手机APP访问对应的服务器(大概率)
一、HTTP协议的报文格式
HTTP的报文格式,要分成 请求 和 响应两个部分来看待。HTTP协议是一种“一问一答”结构模型的协议,请求和响应的协议格式,是有所差异的。
一问一答(访问网站)、多问一答(上传文件)、一问多答(下载文件)、 多问多答(串流、远程桌面)
- 可以通过抓包工具来查看HTTP请求和响应的格式。
1.Fiddler的使用教程
抓包:把网卡上经过的数据,获取到并显示出来。Fiddler(专门抓HTTP)、wireshark工具。
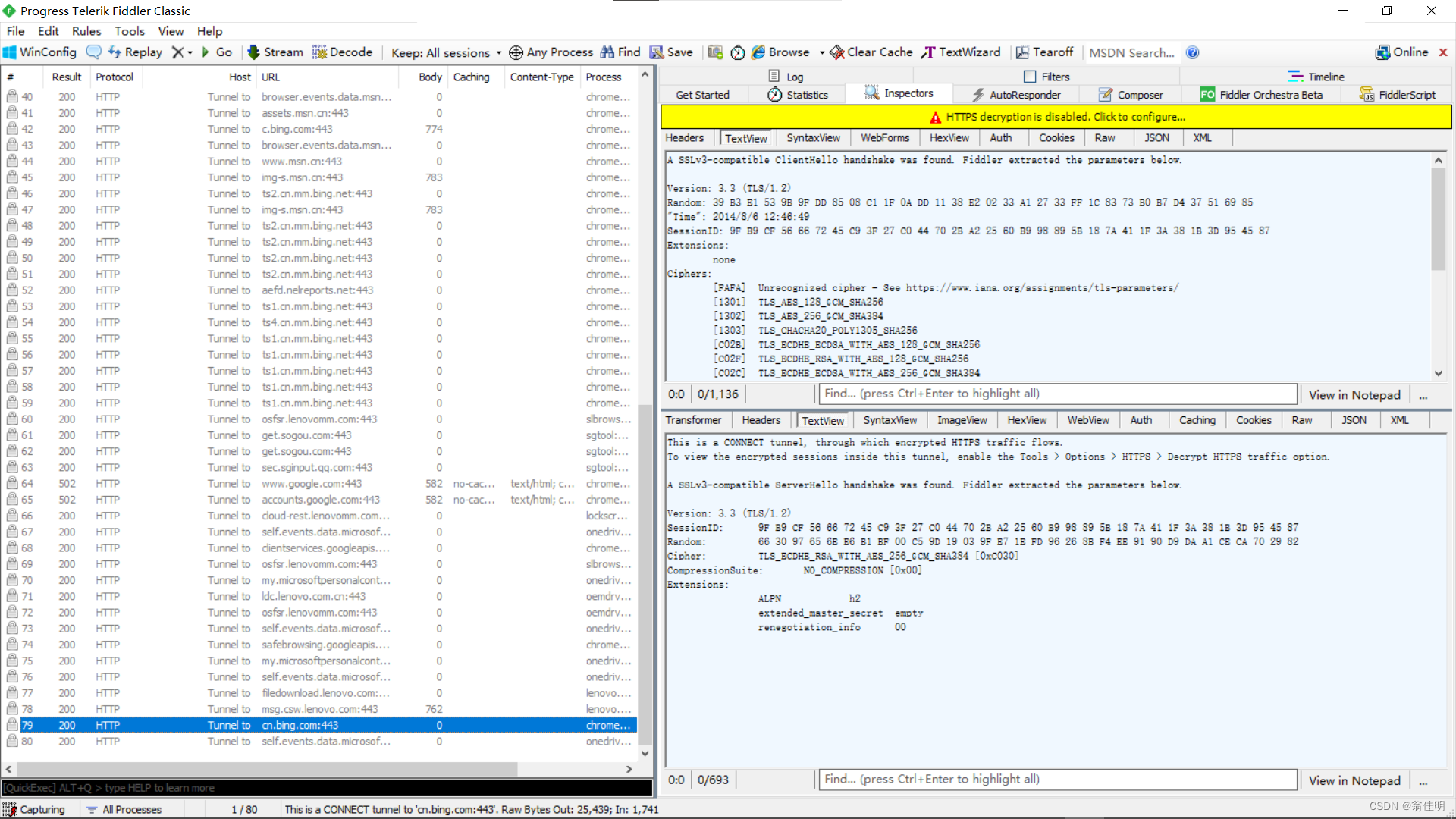
- 左侧是抓到的包,右上方是请求,右下方的响应。
新安装的Fidder需要手动开启HTTPS功能,并且安装证书(否则只能抓HTTP)而当前的互联网环境上,以HTTPS为主,很少有纯HTTP。
Tools->Options->HTTPS都勾上 并安装证书。
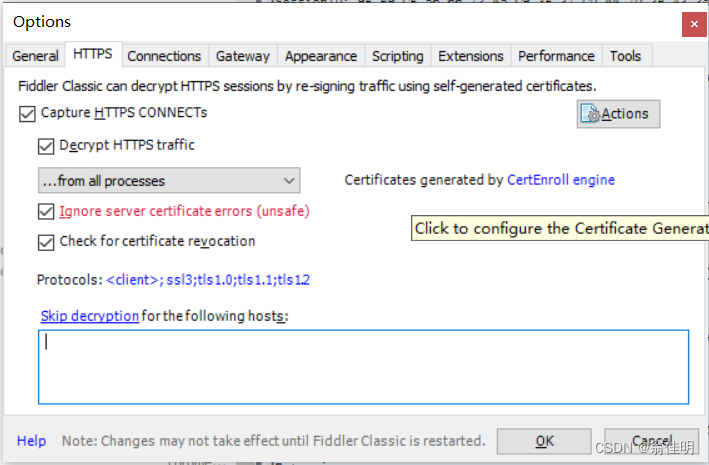
Fiddler本质上是一个“正向代理”,可能会和其他的代理软件发生冲突。Fiddler代理的是客户端。把请求先给Fiddler,服务器回复的响应会先回到Fiddler,Fiddler再返回给客户端。因此,Fiddler可以获取到请求和响应的详细内容。
ctrl+a 全选,delete 清空当前全部抓到的包。

蓝色是获取到的HTML页面。选择后,看右上方的Raw选项:请求最原始的数据格式。
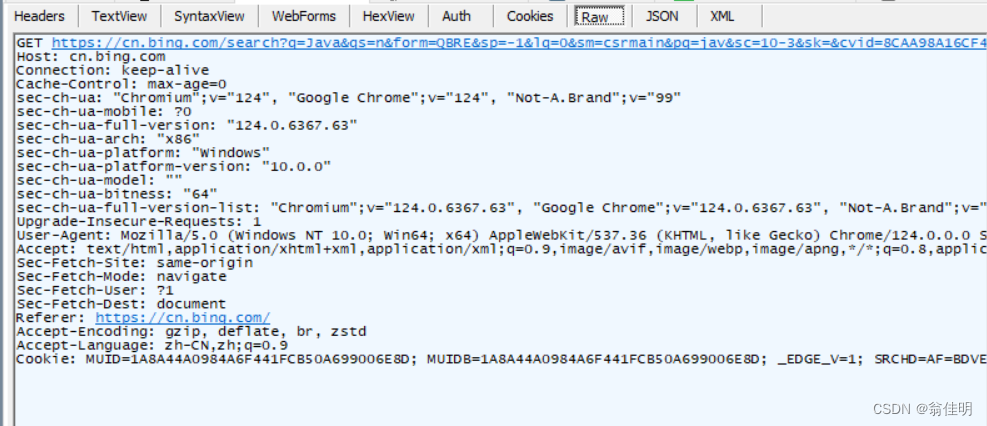
HTTP协议是文本格式的协议(内容都是字符),之前的TCP、UDP、IP协议都是二进制格式的协议。
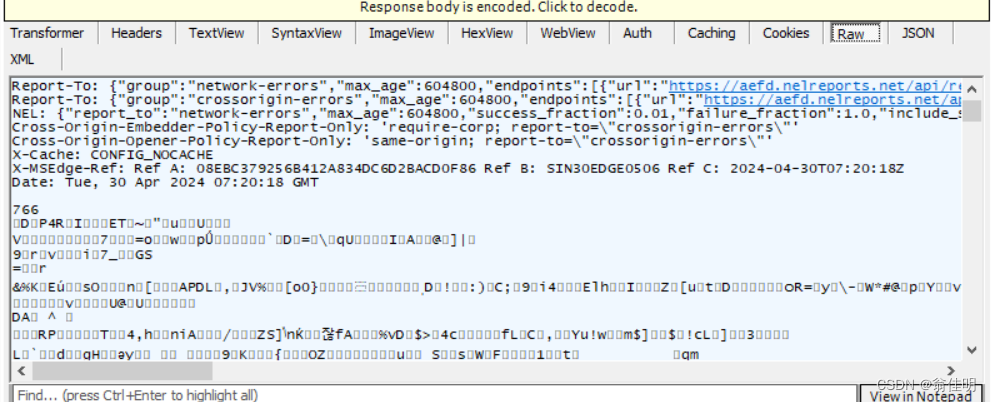
HTTP的响应也是文本格式的,这里的二进制乱码是因为被压缩了。HTTP响应经常会被压缩,压缩之后体积变小,传输的时候可以节省网络带宽(服务器最贵的资源,就是网络带宽)。但同时,压缩和解压缩,需要消耗额外的CPU和时间。

点击淡黄色框。Click to decode,进行解压缩
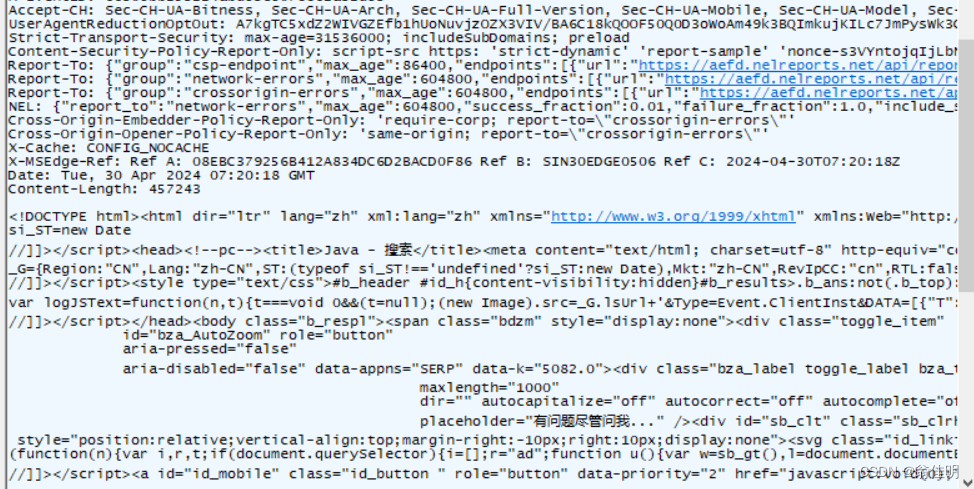
此时就可以看到之前的乱码被解压好了,响应的数据是一个html文件。浏览器上显示的网页(html),往往都是浏览器先请求对应的服务器,从服务器这边拿到的页面数据(html)
二、HTTP请求(Request)
1.首行:
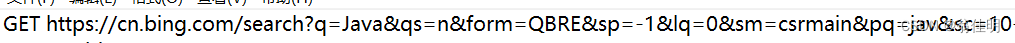
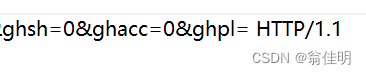
HTTP请求的第一行,有三个部分信息,使用空格分隔。
1.GET : HTTP请求的“方法”(method)
2.URL (唯一资源定位符):描述了一个资源在网络上的位置
3.版本号:HTTP/1.1 当前最主流的版本。
1)方法(method)
GET 获取资源
POST 传输实体主体(登录、上传文件)
GET请求通常会把要传给服务器的数据,加到url的query string中
POST请求,通常会把要传给服务器的数据,加到body
各种不同的请求最初的未来表示不同的语义。但是如何使用不一定严格遵守。
GET和POST的区别(面试题)
1.没有本质区别,双方可以进行替换
2.使用习惯上存在差异:GET通常会把要传给服务器的数据,加到url的query string中POST放在body中。
3.语义上的差异:GET大多数用来获取数据,POST大多数用来提交数据(登录、上传等)
4.在早期硬件性能受限的情况下,会限制url的长度从而降低get的传输能力。但是现在的url已经可以很长,来满足需求。
5.GET虽然是显示信息的,但是并不意味着不安全,即使获取到也不容易破解加密
6.GET也可以在body中存放二进制信息。也可以把二进制的数据通过base64转码,放在url的query string中。
7.GET请求是幂等的,POST请求不是幂等的。实际上是否幂等取决于代码的实现。RFC标准文档建议GET请求实现成幂等的。
8.GET请求可以被浏览器缓存,POST不可以被缓存(幂等性的延续)
9.GET请求可以浏览器收藏夹收藏,POST不能(可能会丢失body)
幂等:输入相同的内容,输出是稳定的
2)URL
URL是计算机中非常重要的概念,不仅仅在HTTP中涉及到。在jdbc中设置数据源时:setUrl(“jdbc:mysql://127.0.0.1:3306/base?characterEncoding=utf8&useSSL = false”);这就是一个URL,URL(唯一资源定位符)描述了某个资源在网络上的所属位置。数据库同样也是一种资源。描述出数据库具体的位置。

-
协议方案名 :http:// https://
-
登录认证信息,现在几乎不会用到,尤其是针对用户的产品。
-
服务器地址:可以是一个IP,也可以是域名。
-
服务器端口号:通过IP地址只是描述了网络资源在哪个主机上,一个主机可能有很多服务器程序,使用端口号来进行区分是哪个程序。URL中是端口号,有时可以省略。对于http请求,端口号省略,默认访问80端口。对于https请求来说,端口号省略,默认访问443端口。
-
带层次的文件路径:描述了要访问服务器的哪个资源。
一个服务器提供的资源可能有很多。/dir/index.html虽然写法是目录的写法,只是用来区分当前资源的位置,在服务器上不一定是以目录的形式来存储资源的。(这个资源可能是硬盘的数据、内存的数据、通过网络访问其他服务器拿到的数据、通过CPU计算出来的一些数据)这个目录结构怎么写,和后续服务器代码的编写程序密切相关。
-
查询字符串(query string):针对这次请求进行了一些补充说明。
?uid = 1 :以?开头是一种键值对结构的数据,键值对&来分隔,键和值用=来分隔。一个url中的query string里可以包含N个键值对,可能会导致很长。query string中的键值对都是程序员自定义的,而header中的键值对是标准规定的。
如果value部分要包含一些特殊符号的话,往往要进行urlencode操作。“+?:/…”这些字符在url中已经有特殊用途了。如果value中,也包含特殊字符,就可能会使浏览器/http服务器,对url的解析出现bug。C++ ->C%2B%2B。urlencode(本质上是一种转义字符)“+”的ascii码就是2B,在前面加上%表示这是转义的结果。汉字也需要进行转义。后续在使用url时要记得需要针对query string的内容进行urlencode操作,避免浏览器解析失败,导致请求无法正常进行。
-
片段标识符:#ch1 有的网页内容比较长,就可以分成多个“片段”,通过片段标识符,就可以完成页面内部的跳转。(翻阅技术文档)
2.请求头(header):
- 首行下面就是是请求头header。
- 是一个键值对结构的数据,每个键值对都独占一行。都是属于“标准规定”的。键和值之间,使用 :+ 空格 来区分。
- 使用空行,来作为请求头的结束标记。

1.HOST:
表示服务器主机的地址和端口,地址也在url中存在。在使用代理的时候,HOST的内容可能和url中的内容是不同的。
2.Content-Length
Content-Length:描述body中数据的长度。 Content-Type:描述body中数据的格式
出现这两个属性的前提是请求中有body,通常情况下GET请求没有body.POST请求有body
TCP涉及到粘包问题,HTTP在传输层就是基于TCP的。使用同一个TCP连接,传输多个HTTP数据包,此时就会使多个HTTP数据包在TCP接受缓冲区中挨在一起。接收方解析的时候,就需要能够清楚HTTP数据包之间的边界。对于GET这种没有body的请求,直接使用空行(分隔符)区分。对于POST这种有body的请求,结合空行和Content-Length区分
3.body中数据的格式:
请求:1.json ({ })2.form表单的格式 (相当于把GET的query string搬到body中)3.form-data的格式(上传文件)
响应:1.html 2.css 3.js 4.json 5.图片…
后续给服务器提交的请求,不同的Content-Type,服务器处理的逻辑的不同的。浏览器也会对返回的不同Content-Type进行处理。
4.User-Agent(UA)
描述了使用什么设备上网(操作系统版本、浏览器版本)。目前的浏览器差异很小,所以目前UA主要用来区分PC端和移动端。
5.Referer
描述了当前页面是从哪个页面跳转来的。
如果是直接在地址栏输入url(或者点击收藏夹)是没有Referer的
6.Cookie
浏览器在本地存储数据的一种机制。
Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服务器在HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).
在浏览器存储临时数据(上次登录的时间、用户的身份信息、累计访问次数等)
为了保证安全性,又能进行存储数据,于是就引入了Cookie(也是按照硬盘文件的方式保存,但是浏览器把操作文件封装了,网页只能往Cookie中存储 键值对->字符串)。Cookie存储在浏览器所在主机的硬盘上,并且按照域名为维度来存储。每个域名下可以存自己的Cookie,彼此互不影响。Cookie按照键值对和形式进行组织(键值对是由程序员自定义的和query string类似)后续再请求这个服务器的时候,就会把Cookie中的内容自动代入到请求中,再发给服务器。服务器再根据Cookie的内容进行处理。
3.正文(body):
有的HTTP请求有,有的没有。
三、HTTP响应
1.首行
- 由三个部分组成。

1.版本号:HTTP/1.1
2.状态码 : 200 描述了请求的结果
表示了这次请求对于的响应是什么状态(成功、失败、其他情况、对于的原因)
2XX:2开头的都表示成功。
3XX: 3开头的都表示重定向。302:临时重定向
重定向:请求中访问的是A的地址,响应返回了一个重定向报文,告诉应该访问B地址。比如网页跳转、或者服务器迁移了
重定向的响应报文,会带有Location字段描述出当前要跳转到哪个新的地址。
4XX:4开头表示请求错误。
404:Not Found 请求中访问的资源,在服务器上不存在。
403:Forbidden 表示访问的资源没有权限。
418:I am a teapot! 是HTTP RFC文档中的彩蛋,并没有实际的含义。
5XX: 5开头的表示服务器出错了。(服务器挂了) 500:写的代码有bug
总结:
1**:hold on 等一等,后面还有
2**:Here you go 你走对了
3**:Go away 去别处
4**:You fucked up 你出错了
5**:I fuckd up 我出错了
3.状态码描述:OK 对这个状态码做了进一步的解释。
2.响应头(header)
- 首行下面的响应头,同样是键值对结构,每个键值对独占一行,一直到空行结束。

3.正文
- 空行的下面,正文可能比较长,可能是多种格式。
四、如何让客户端构造一个HTTP请求
浏览器:
1.直接在浏览器地址栏输入url,构造一个GET请求。
2.特殊的html标签,可能会触发GET请求:img、a、link、script。
3.通过form表单来触发GET/POST请求。
浏览器对于html来说具有一定的鲁棒性(容错能力、即使写的不规范,也尽可能的进行解析)
<form action="http://www.baidu.com/abc.html" method="get">
</form>
- 1
- 2
- 3
- action属性里写要访问请求的url路径是什么。
- method属性描述了当前要构造的请求是get还是post(form只支持get和post)
<form action="http://www.baidu.com/abc.html" method="get">
<input type="text" name="key1">
<input type="text" name="key2">
<input type="text" name="key3">
<input type="submit" value="提交">
</form>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
输入框的内容就会被构造成http请求的query string
query string是键值对形式的,key就是input输入框的name属性,value就是输入框中用户输入的内容
4.ajax的方式
form存在一些缺陷,1.只支持get和post,不支持其他方法。2.form会出触发页面跳转(有的时候不需要跳转)所以引进ajax。通过js提供的api来构造http请求。针对拿到的响应,可以使用js灵活进行处理。
浏览器原生提供了ajax的api,不好用。一些第三方库,封装了ajax,使用第三方库封装好的ajax来进行操作
1.引入jquery库
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script>
- 1
2.编写代码
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script>
<script>
$.ajax({
type: 'get',
url: 'https://www.sogou.com/abc.html',
success: function (body) {
console.log(body);
}
});
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- $是一个变量名(在jquery中定义的全局变量),通过这个变量来调用一些方法,使用jquery中的api
- js中{ } 表示对象。里面用键值对的方式来进行描述
- success这个函数,不是立即执行的,而是服务器返回200这样的响应时,才会执行到success(回调函数)
5.通过第三方工具,图形化界面构造:postman
var settings = { "url": "https://www.sogou.com", "method": "POST", "timeout": 0, "headers": { "Content-Type": "application/json", "Cookie": "IPLOC=CN6101; SUID=09842E705EA7A20B00000000663A0247; cuid=AAEV1zYJTAAAAAuiptoeYwEAEAM=; ABTEST=0|1715077703|v17" }, "data": JSON.stringify({ "a": "100", "b": "200" }), }; $.ajax(settings).done(function (response) { console.log(response); });

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 通过postman来生成js代码


