
- 1银河麒麟高级服务器操作系统V10SP2(X86)audit服务组件升级、进程彻底关闭介绍_audit-3.0-5.se.08.ky10
- 2python opencv中文显示cv2 imshow()窗口中文标题乱码解决办法 python win32gui按装_cv2.imshow中文乱码
- 3【2023年APMCM亚太杯C题】完整代码+结果分析+论文框架_ahp分析汽车后市场影响因素
- 4Unity程序开发框架——单例模式基类模块_: singletonbehaviourbase
- 5使用div利用布局实现表格的效果_div 表格样式
- 6【ETOJ P1025】最长公共子序列 题解(动态规划+最长公共子序列)
- 7Android复习系列③之《Android筑基》_android开发scheme跳转支持唤醒到前台
- 8毕业设计 基于51单片机的智能门禁系统的设计_门禁报警电路怎么连接单片机
- 9【头歌-Python】列表自学引导_平台会对你编写的代码进行测试,平台生成一个包含1万个元素的列表(里面的元素每次
- 10Git reset 和 revert的区别_git reset和revert区别
EM算法及其应用(一)
赞
踩
EM算法是期望最大化 (Expectation Maximization) 算法的简称,用于含有隐变量的情况下,概率模型参数的极大似然估计或极大后验估计。EM算法是一种迭代算法,每次迭代由两步组成:E步,求期望 (expectation),即利用当前估计的参数值来计算对数似然函数的期望值;M步,求极大 (maximization),即求参数
§1 先验知识
凸函数、凹函数和 Jensen不等式
设
则
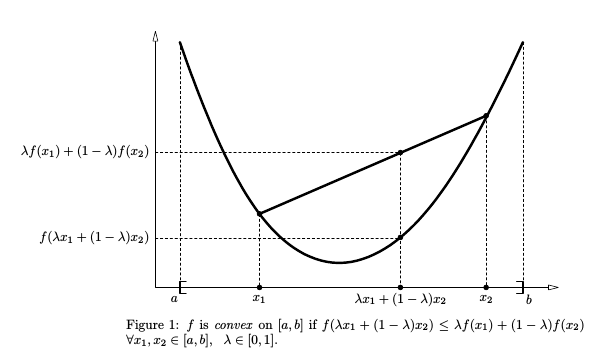
Jensen不等式就是上式的推广,设
如果是凹函数,则将不等号反向,若用对数函数来表示,就是:
若将
KL散度
KL散度(Kullback-Leibler divergence) 又称相对熵 (relative entropy),主要用于衡量两个概率分布p和q的差异,也可理解为两个分布对数差的期望。
KL散度总满足
KL散度不具备对称性,即
极大似然估计和极大后验估计
极大似然估计 (Maximum likelihood estimation) 是参数估计的常用方法,基本思想是在给定样本集的情况下,求使得该样本集出现的“可能性”最大的参数
这个函数反映了在观测结果X已知的条件下,
于是通过求导求解使得对数似然函数最大的参数
极大后验估计 (Maximum a posteriori estimation) 是贝叶斯学派的参数估计方法,相比于频率学派,贝叶斯学派将参数
上式中
§2 EM算法初探
概率模型有时既含有观测变量 (observable variable),又含有隐变量 (hidden variable),隐变量顾名思义就是无法被观测到的变量。如果都是观测变量,则给定数据,可以直接使用极大似然估计。但如果模型含有隐变量时,直接求导得到参数比较困难。而EM算法就是解决此类问题的常用方法。
对于一个含有隐变量
我们的目标是极大化观测数据
上式中存在“对数的和” ——
要想构建下界,就需要运用上文中的Jensen不等式。记
P(Z|X,θ(t))⩾0 ∑ZP(Z|X,θ(t))=1 -
ln(⋅) 为凹函数
因而可以利用Jensen不等式求出
基于观测数据
X 和 当前参数θ(t) 计算未观测数据Z 的条件概率分布P(Z|X,θ(t)) ,则Q函数为完全数据的对数似然函数关于Z 的期望。
此即E步中期望值的来历。
接下来来看M步。在
可以看到在第t步,
EM算法流程:
输入: 观测数据
输出:模型参数
- 初始化参数
θ(0) - E步: 利用当前参数
θ(t) 计算Q函数,Q(θ,θ(t))=∑ZP(Z|X,θ(t))lnP(X,Z|θ) - M步: 极大化Q函数,求出相应的
θ=argmaxθQ(θ,θ(t)) - 重复 2. 和3. 步直至收敛。
EM算法也可用于极大后验估计,极大后验估计仅仅是在极大似然估计的基础上加上参数
§3 EM算法深入
上一节中遗留了一个问题:为什么式
假设一个关于隐变量
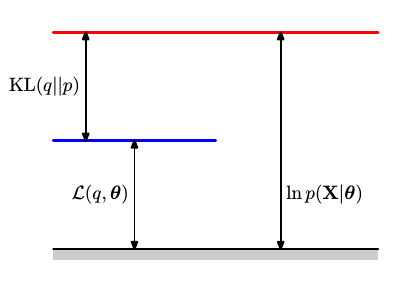
由此可将EM算法视为一个坐标提升(coordinate ascent)的方法,分别在E步和M步不断提升下界
在E步中,固定参数
在M步中,固定分布
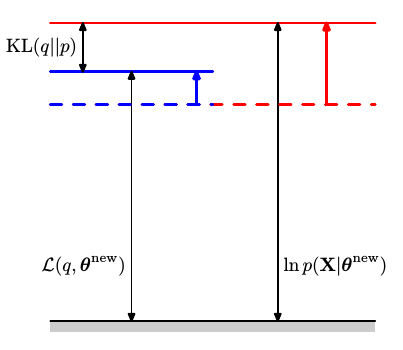
因此在EM算法的迭代过程中,通过交替固定
Reference:
- Christopher M. Bishop. Pattern Recognition and Machine Learning
- 李航. 《统计学习方法》
- CS838. The EM Algorithm
/

