
热门标签
热门文章
- 1 拒绝“割韭菜”— 谈谈区块链正经的商用场景!
- 2项目分享:基于微信小程序的点餐系统设计与实现_国内外微信小程序的医院食堂点餐系统研究现状
- 32024年6月12日Arxiv机器学习相关论文_deformtime:多元时间序列预测的混合信道方法
- 4OpenAI收购5人远程协作公司
- 5HarmonyOS NEXT 使用Web组件预览PDF文件实现案例_鸿蒙 pdf预览
- 621-阴影映射_samplecmplevelzero
- 7使用cv2.applyColorMap画热力图_cv2绘制热力图
- 8【华为OD机试真题 C语言】469、测试用例执行计划 | 机试真题+思路参考+代码解析(C卷)
- 9ora-65096解决方案
- 10LlamaFactory-Ollama-Langchain大模型训练-部署一条龙_ollama langchain 微调模型
当前位置: article > 正文
机器学习经典案例——鸢尾花分类预测_利用sklearn库的数据集,实现鸢尾花宽度的预测
作者:人工智能uu | 2024-06-23 03:22:16
赞
踩
利用sklearn库的数据集,实现鸢尾花宽度的预测
机器学习经典案例——鸢尾花分类预测
简介
鸢尾花数据集是机器学习中经典的数据集之一,它被广泛用于分类问题的研究和练习。本文将介绍如何使用Python和Scikit-Learn库来进行鸢尾花的分类预测,通过一个完整的机器学习流程,包括数据预处理、模型训练和性能评估。
数据集介绍
鸢尾花数据集包含了三个不同种类的鸢尾花的测量特征,共有150个样本。数据集中的特征包括花萼长度、花萼宽度、花瓣长度和花瓣宽度,目标变量是鸢尾花的种类(Setosa、Versicolor、Virginica)。
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
# 查看数据集的基本信息
print("数据集大小:", iris.data.shape)
print("特征名称:", iris.feature_names)
print("目标值:", iris.target)
print("目标值名称:", iris.target_names)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数据基本处理
首先,我们需要将数据集分割为训练集和测试集,以便评估模型的性能。我们使用Scikit-Learn的train_test_split函数,并指定了测试集的大小和随机种子以确保结果可重复。
pythonCopy codefrom sklearn.model_selection import train_test_split
# 分割数据集为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=66)
- 1
- 2
- 3
- 4
特征工程
在进行模型训练之前,我们对特征进行归一化处理,使用MinMax Scaling方法将特征缩放到0到1的范围。
pythonCopy codefrom sklearn.preprocessing import MinMaxScaler
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
# 对训练集和测试集进行特征缩放
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
机器学习模型选择
为了解决鸢尾花分类问题,我们选择了随机森林算法作为我们的机器学习模型。随机森林是一个强大的集成算法,通常对分类问题表现良好。
pythonCopy codefrom sklearn.ensemble import RandomForestClassifier
# 实例化随机森林分类器
estimator = RandomForestClassifier()
# 模型训练
estimator.fit(x_train, y_train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
模型评估
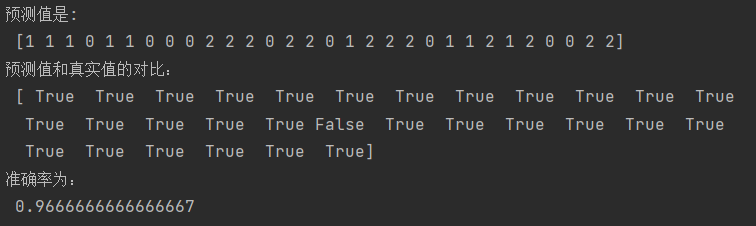
我们使用模型在测试集上的性能来评估模型的准确性。首先,我们进行预测并将预测结果与真实值进行比较。然后,我们计算模型的准确率作为性能指标。
pythonCopy code# 预测值结果输出
y_pred = estimator.predict(x_test)
# 计算准确率
accuracy = (y_pred == y_test).mean()
print("准确率:", accuracy)
- 1
- 2
- 3
- 4
- 5
- 6
结论
通过这个示例,我们演示了如何使用Python和Scikit-Learn库进行鸢尾花的分类预测。这个案例涵盖了机器学习流程中的关键步骤,包括数据预处理、模型选择、模型训练和性能评估。鸢尾花数据集是一个经典的机器学习练习案例,可以帮助初学者了解和实践机器学习技术。
参考资料
源码
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from sklearn.ensemble import RandomForestClassifier ## 1.获取数据集 # 获取鸢尾花数据集 iris = load_iris() # 查看数据集的详细信息 print(iris.data.shape) print("鸢尾花特征的名称:\n",iris["feature_names"]) print("鸢尾花的目标值:\n",iris["target"]) print("鸢尾花目标值的名称:\n",iris["target_names"]) ## 2.数据基本处理 # 对鸢尾花数据集进行分割 # 训练集的特征值x_train,测试集的特征值x_test 训练集的目标值y_train,测试集的目标值y_test x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=66) # 若不指定训练集和测试集比例,默认按3:1划分 random_state确保随机性操作的可重复性,在不同运行中获得相同的随机结果 # print("x_train:\n",x_train) print(x_test.shape) ## 3.特征工程(特征预处理,这里使用的是归一化的Min-Max Scaling) # 创建MinMaxScaler对象 scaler = MinMaxScaler() # 对训练集进行Min-Max缩放 x_train = scaler.fit_transform(x_train) # 对测试集进行Min-Max缩放 x_test = scaler.fit_transform(x_test) ## 4.机器学习(这里选择的是随机森林算法) # 实例化随机森林分类器 estimator = RandomForestClassifier() # 模型训练 estimator.fit(x_train,y_train) ## 5.模型评估 # 预测值结果输出 y_pre = estimator.predict(x_test) print("预测值是:\n",y_pre) print("预测值和真实值的对比:\n",y_pre == y_test) # 准确率计算 score = estimator.score(x_test,y_test) print("准确率为:\n",score)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/748546
推荐阅读
相关标签

