
热门标签
当前位置: article > 正文
人工智能---课设
作者:不正经 | 2024-06-16 10:50:18
赞
踩
人工智能---课设
题目
利用 SVM 将图中给定 5 类数据分为 3 类,并在原图中画出 3 类别分类曲线,然后再计算分类器精度。 其中分类器
按照 85-15%总体数据进行学习和测试,用模糊矩阵表示分类结论并对分类结果进行说明。
- 1
- 2
第一题: 提取数据+绘图
查找资料解决如何读取 fig 文件中数据,并按照自己的理解方式重新制 作 MATLAB 图形。
重新绘制图形如下:
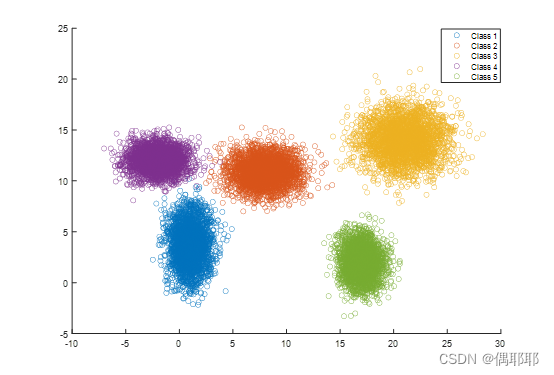
从fig文件提取数据代码如下:
% 打开.fig文件并获取图形句柄 figure_handle = open('Fig_DataSetM.fig'); % 获取当前轴上的所有子图形对象 children = get(gca, 'Children'); % 初始化一个新的图形窗口 figure; % 设置颜色映射和符号 colors = lines(length(children)); % 使用 lines 而不是 jet markers = ['o', 'x', '+', '*', 's', 'd', 'v', 'p', 'h', '.']; % 初始化空数组用于存储数据 data = []; % 遍历所有子图形对象 for i = 1:length(children) % 获取子图形对象的句柄 child = children(i); % 为每个类别选择一个符号 marker = markers(mod(i-1, length(markers)) + 1); % 检查子图形对象是否为一个组 if strcmp(get(child, 'Type'), 'hggroup') % 获取组内的所有子图形对象 grand_children = get(child, 'Children'); % 遍历组内的所有子图形对象 for j = 1:length(grand_children) grand_child = grand_children(j); % 获取数据并画散点图,为每个类别设置一种颜色和一个符号 x_data = get(grand_child, 'XData'); y_data = get(grand_child, 'YData'); scatter(x_data, y_data, [], colors(i,:), marker); hold on; % 保持当前图形 % 将数据添加到数组中 data = [data; [x_data(:), y_data(:), repmat(i, length(x_data), 1)]]; end else % 获取数据并画散点图,为每个类别设置一种颜色和一个符号 x_data = get(child, 'XData'); y_data = get(child, 'YData'); scatter(x_data, y_data, 'MarkerEdgeColor', colors(i,:), 'Marker', marker); % 不使用 'filled',而是指定边缘颜色 hold on; % 保持当前图形 % 将数据添加到数组中 data = [data; [x_data(:), y_data(:), repmat(i, length(x_data), 1)]]; %读出数据为data00.csv文件 data = [data]; filename = 'data00.csv'; writematrix(data, filename);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
重新画MATLAB图代码如下:
% 读取数据文件 data = readmatrix('data00.csv'); % 将数据按标签分组 label1 = data(data(:,end)==1,:); label2 = data(data(:,end)==2,:); label3 = data(data(:,end)==3,:); label4 = data(data(:,end)==4,:); label5 = data(data(:,end)==5,:); % 绘制散点图 scatter(label1(:,1),label1(:,2)); hold on; scatter(label2(:,1),label2(:,2)); scatter(label3(:,1),label3(:,2)); scatter(label4(:,1),label4(:,2)); scatter(label5(:,1),label5(:,2)); hold off; % 添加图例 legend('Class 1','Class 2','Class 3','Class 4','Class 5');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
第二题:SVM实现多分类
分类图如下:
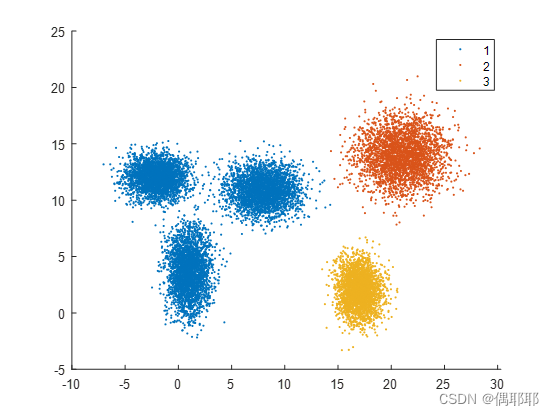
分类图代码如下:
% 读取数据文件 data = readmatrix('data00.csv'); % 将数据按标签分组 label1 = data(data(:,end)==1,:); label2 = data(data(:,end)==2,:); label4 = data(data(:,end)==4,:); label3 = data(data(:,end)==3,:); label5 = data(data(:,end)==5,:); % 将第一类、第二类和第四类数据合并为一类 label124 = [label1; label2; label4]; % 将数据标签合并为 3 类 group = zeros(size(data,1),1); group(ismember(data(:,end),[1,2,4])) = 1; % 第一类、第二类和第四类为第一类别 group(data(:,end)==3) = 2; % 第三类为第二类别 group(data(:,end)==5) = 3; % 第五类为第三类别 % 划分训练集和测试集 [trainInd,valInd,testInd] = dividerand(size(data,1),0.85,0,0.15); trainData = data(trainInd,:); trainGroup = group(trainInd,:); testData = data(testInd,:); testGroup = group(testInd,:); % 训练 SVM 模型 svmMdl = fitcecoc(trainData(:,1:end-1),trainGroup); % 在测试集上进行预测 testPred = predict(svmMdl,testData(:,1:end-1)); % 计算准确率 acc = sum(testPred == testGroup)/length(testGroup); % 绘制散点图和分类曲线 figure(); hold on; gscatter(data(:,1),data(:,2),group);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
第三题:实现多分类结果表示并计算出分类精度
混淆矩阵如下:
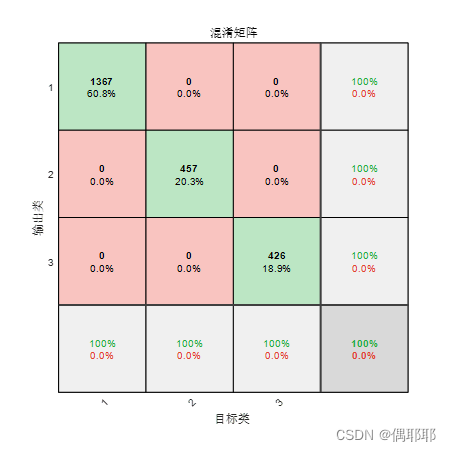
代码如下:
% 绘制混淆矩阵图
plotconfusion(categorical(testGroup),categorical(testPred));
% 计算混淆矩阵
confMat = confusionmat(testGroup,testPred);
% 计算分类精度
acc = sum(diag(confMat))/sum(confMat(:));
分类精度 = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第四题:利用 GMM 学习算法实现以上分类效果
波峰图如下:
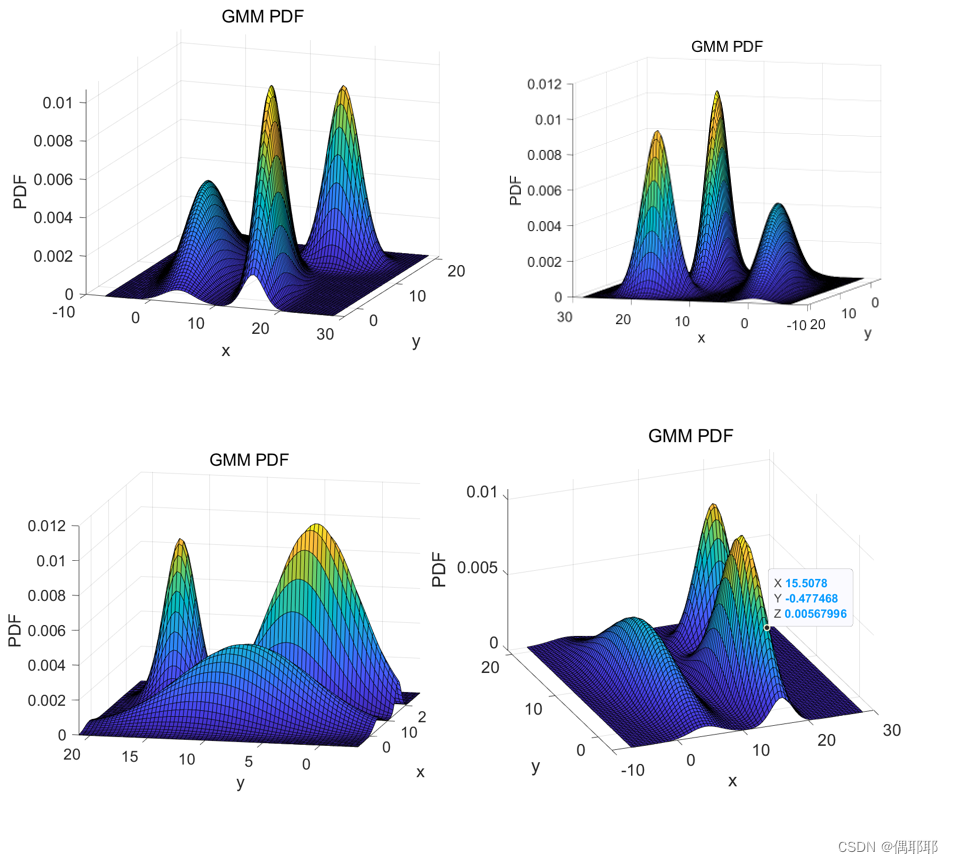
代码如下:
% 读取数据文件 data = readmatrix('data00.csv'); % 将数据按标签分组 label1 = data(data(:,end)==1,:); label2 = data(data(:,end)==2,:); label4 = data(data(:,end)==4,:); label3 = data(data(:,end)==3,:); label5 = data(data(:,end)==5,:); % 将第一类、第二类和第四类数据合并为一类 label124 = [label1; label2; label4]; % 将数据标签合并为 3 类 group = zeros(size(data,1),1); group(ismember(data(:,end),[1,2,4])) = 1; % 第一类、第二类和第四类为第一类别 group(data(:,end)==3) = 2; % 第三类为第二类别 group(data(:,end)==5) = 3; % 第五类为第三类别 % 划分训练集和测试集 [trainInd,valInd,testInd] = dividerand(size(data,1),0.85,0,0.15); trainData = data(trainInd,:); trainGroup = group(trainInd,:); testData = data(testInd,:); testGroup = group(testInd,:); % 使用GMM学习算法进行分类 options = statset('MaxIter',500); gmmMdl = fitgmdist(trainData(:,1:end-1),3,'CovarianceType','full','Options',options); gmmPred = cluster(gmmMdl,testData(:,1:end-1)); % 计算分类精度 acc = sum(gmmPred == testGroup)/length(testGroup); % 绘制散点图和分类曲线 figure(); hold on; gscatter(data(:,1),data(:,2),group); % 绘制GMM分布 M = 70; X = linspace(min(data(:,1)), max(data(:,1)), M); Y = linspace(min(data(:,2)), max(data(:,2)), M); [X,Y] = meshgrid(X, Y); points = [X(:), Y(:)]; gmPDF = pdf(gmmMdl, points); Z1 = reshape(gmPDF, M, M)'; figure; surf(X, Y, Z1); view(-39,34); set(gca,'FontSize',14); xlabel('Feature 1'); ylabel('Feature 2'); zlabel('PDF'); title('GMM PDF') % 绘制3D波峰图和分类曲线 figure(); hold on; [xx, yy] = meshgrid(min(data(:,1)):0.01:max(data(:,1)),min(data(:,2)):0.01:max(data(:,2))); zz = zeros(size(xx)); for i=1:size(xx, 1) for j=1:size(xx, 2) zz(i, j) = pdf(gmmMdl, [xx(i, j), yy(i, j)]); end end mesh(xx, yy, zz); gscatter(data(:,1),data(:,2),group);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
结论: 对比两种算法的结果,我们可以看到SVM的分类精度为1,也就是说它可以完美地将数据集分为不同的类别。相比之下,
GMM的分类精度只有0.3991,说明它在某些情况下进行分类时会出现错误。因此,在实际应用中,SVM更容易被应用于分类问题,
特别是对于需要高度准确性的任务,如医学图像识别等。只有在某些不需要非常高的准确性的场景下,GMM才会被优先考虑。
- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/726327
推荐阅读
相关标签

