
- 1爆火!!!中文版 Llama3 开源了!!_ollama llama3 强制用中文回答
- 2520表白神器,小贺只能帮你到这了......
- 32024年,计算机相关专业还值得选择吗?_计算机专业现在饱和了吗
- 4Android 应用程序集成Google 登录及二次封装_com.google.android.gms.auth.api
- 5error: RPC failed; curl 18 transfer closed with outstanding read data remaining fatal: the remote en_linux搭建http server 下载文件出现curl: (18) transfer close
- 6Android Studio 安卓模拟器无法连接网络_androidstudio模拟器没网络
- 7Elasticsearch介绍2
- 8Kubernetes1.23搭建Elasticsearch7集群(集群加密)_kubernetes部署单机elasticsearch7.16.2
- 9【Diffusers库】第五篇 加载pipeline、model、schedulers_diffusers pipline没有本地模型
- 10神仙级AI大模型入门教程(非常详细),从零基础入门到精通,从看这篇开始!_大模型教程
柏拉图式表征:人工智能深度网络模型是否趋于一致?
赞
踩
人工智能模型是否正在向现实的统一表征演进?柏拉图表征假说认为,人工智能模型正在趋同。
麻省理工学院最近的一篇论文引起了我的注意,因为它提出了一个令人印象深刻的观点:人工智能模型正在趋同,甚至跨越了不同的模态–视觉和语言。“我们认为,人工智能模型,尤其是深度网络中的表征正在趋同”,这是 The Platonic Representation Hypothesis (https://arxiv.org/abs/2405.07987)论文的开头。
但是,在不同数据集上针对不同用例训练的不同模型如何趋同?是什么导致了这种趋同?

柏拉图的洞穴寓言 Jan Saenredam(https://en.wikipedia.org/wiki/Allegory_of_the_cave#/media/File:Platon_Cave_Sanraedam_1604.jpg) 著
1.柏拉图表征假说
我们认为,在不同的神经网络模型中,数据点的表示方法越来越相似。这种相似性跨越了不同的模型架构、训练目标,甚至数据模式。

source: https://arxiv.org/abs/2405.07987
1.1 引言
论文的中心论点是,各种来源和模式的模型都在向现实的表征靠拢–即世界事件的联合分布,这些事件产生了我们观察到的数据,并用来训练模型。
作者认为,这种向柏拉图式表征的趋同是由模型所训练的数据的基本结构和性质以及模型本身日益增长的复杂性和能力所驱动的。随着模型遇到各种数据集和更广泛的应用,它们需要一种能捕捉所有数据类型中常见基本属性的表示方法。
1.2 柏拉图的洞穴
本文特别引用了柏拉图的《洞穴寓言》(Allegory of the Cave),以类比假设人工智能模型如何发展出对现实的统一表征,以及柏拉图关于感知和现实的哲学思想。在柏拉图的寓言中,洞穴中的囚犯只能看到投射在墙上的真实物体的影子,他们只相信这些影子就是现实。然而,这些物体的真实形态存在于洞穴之外,比囚犯感知到的影子更加真实。

2.人工智能模型是否趋同?
各种规模的人工智能模型,即使建立在不同的架构上,并针对不同的任务进行训练,在如何表示数据方面都显示出趋同的迹象。随着这些模型的规模和复杂性的增长,以及输入数据的规模和种类的增加,它们处理数据的方法也开始趋于一致。
针对不同数据模式(视觉或文本)训练的模型也会趋同吗?答案可能是肯定的!
2.1 会说话的视觉模型
这种一致性涵盖了视觉和文本数据–论文后来证实,这一理论的局限性在于它只关注这两种模块,而没有关注其他模态,如音频或机器人对世界的感知。LLaVA是支持这一理论的案例之一[1],它显示了使用双层MLP将视觉特征投射到语言特征中,从而获得了最先进的结果。
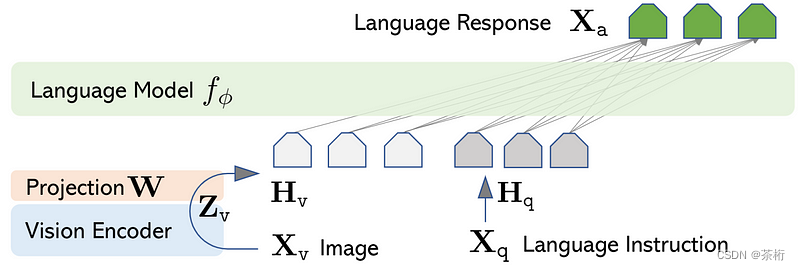
2.2 看得见的语言模型
另一个有趣的例子是《语言模型的视觉检查》[2],它探讨了大型语言模型理解和处理视觉数据的程度。这项研究使用代码作为图像和文本之间的桥梁,这是一种向语言模型提供视觉数据的新方法。论文揭示了 LLMs 可以通过代码生成图像,虽然这些图像看起来可能不太真实,但仍然包含足够的视觉信息来训练视觉模型。
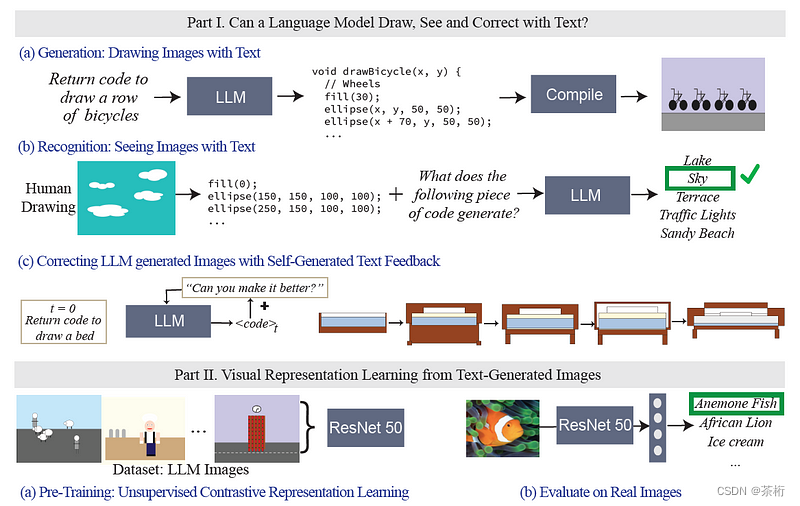
2.3 更大的模型,更大的排列组合
不同模型的一致性与它们的规模有关。举例来说,与较小的模型相比,在 CIFAR-10 分类基础上训练出来的更大模型之间的一致性更高。这意味着,随着目前建立十亿级和千亿级模型的趋势,这些巨型模型将更加一致。
“所有强模型都是相似的,每个弱模型都有自己的弱点”。
3.人工智能模型为何趋同?

人工智能模型的学习过程,
f
∗
f^∗
f∗ 是训练好的模型,
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

