
- 1设计模式(16):观察者模式
- 2ICLR2024丨Simulation在ICLR-2024全线溃败?18篇Simualtion & Agent相关论文合集_2024 agent论文
- 3prompt工程
- 4基于ssm jsp宠物医院信息管理系统源码论文PPT
- 5基于Python的房产数据爬取及可视化分析系统的设计与实践_基于python爬虫的房
- 6关于GPT的Open API,看这一篇就够了(教你搭建)_gpt api
- 7中小型超市的网络规划与设计(完整文档+思科拓扑图)_计算机网络课设中小型网络拓扑图
- 8(java毕业设计源码)基于java(springboot)家具商城管理系统
- 9解决aiml中文支持和模糊匹配问题探索_模糊匹配式问答
- 10python实现文本情感分析_python文本情感识别
GPT系列模型详解_gpt模型讲解
赞
踩
NLP系列模型解析:
Transformer:https://blog.csdn.net/lppfwl/article/details/121084602
GPT系列:https://blog.csdn.net/lppfwl/article/details/121010275
BERT:https://blog.csdn.net/lppfwl/article/details/121124617
最近看了GPT系列模型,这里特此做一下学习记录和个人思考,先附上三个模型的论文:
GPT:https://paperswithcode.com/method/gpt
GPT2:https://paperswithcode.com/method/gpt-2
GPT3:https://paperswithcode.com/method/gpt-3
下面逐一进行介绍:
GPT
pytorch版本代码:https://github.com/huggingface/pytorch-openai-transformer-lm
一句话就是:预训练+微调
作者指出:无标签的文本语料很丰富,但是针对特定任务的有标签文本数据很稀少,导致针对特定任务来训练一个准确的模型很有挑战。因此作者提出了”预训练+微调“的方法,先大量多样的无标签语料数据上训练一个通用的语言模型,再用特定任务的有标签数据进行微调,也就是迁移学习。GPT模型在12个任务中的9个都实现了SOTA的效果,且个别任务效果提升很明显。

1.模型架构
无监督预训练
预训练阶段作者使用语言模型(LM)的训练方式,模型使用的是transformer的变体,即多层transformer-decoder,这个后面会讲。

GPT是单向语言模型,也就是模型在预测下一个词的时候,只能使用该词前面的词语,不能使用后面的词语信息,这个和BERT的双向上下文信息不同,因此GPT模型的性能比BERT要差。
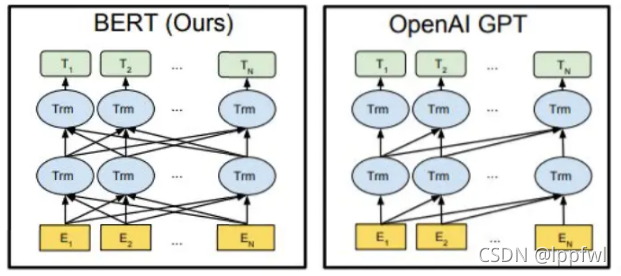
(图片来源:https://www.jianshu.com/p/4dbdb5ab959b?from=singlemessage)
有监督微调
预训练之后,使用有监督的方式微调模型参数来实现特定的任务。值得一提的是,作者发现将语言模型作为辅助目标函数加入到微调过程可以提高微调后模型的泛化能力,加速收敛。(原文见下图红框中的内容)

特定任务如何使用预训练模型进行迁移呢,输入数据形式是什么呢
NLP的许多任务的输入数据形式都不同,比如文本分类是一段文本+一个标签,问答是问句+答句,语义相似判定是两段文本。而预训练模型要在多种不同的任务上都可以微调,那么特定任务的输入数据形式都要向预训练模型靠拢。具体是什么形式呢,就是上图3.2节画横线的那句话,一个字符序列+一个标签。不同任务如何实现,见下图:
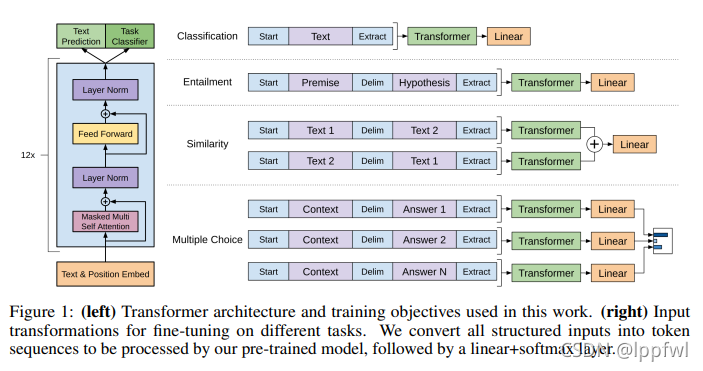
2.模型结构
以上说了这么多,都是GPT实现的技术方案,那GPT模型的结构是什么样的呢?那就是这个图


就是12层的transformer-decoder。其中只使用了transformer模型中的decoder部分,并且把decoder里面的encoder-decoder attention部分去掉了,只保留了masked self-attention,再加上feed-forward部分。再提一句,masked self-attention保证了GPT模型是一个单向的语言模型。
另外,作者在position encoding上做了调整,使用了可学习的位置编码,不同于transformer的三角函数位置编码

(图片来源:https://www.cnblogs.com/yifanrensheng/p/13167796.html)
3.subword算法
这里说一下GPT里面使用的subword算法:BPE(byte pair encoding,字节对编码)。作者使用BPE构建模型词表,这一点在GPT论文中被一句话带过,在GPT2论文中有较为详细的介绍为什么使用BPE。简单来说就是对于英文来说,单词特别多,使用word-level级别的词表可能会出现OOV(out of vocabulary)问题,也就是说可能会出现inference的时候某些单词不在词表中的情况。而使用byte-level字符级别的词表,英文只有26个字母,不会出现OOV问题,但是把每个单词拆成一个个字符会丧失语义信息,导致模型的性能不如使用word-level词表的模型。
为了解决这个问题,subword算法被提出,它是word-level和byte-level的折中,将单词拆成一个个子串,比如:greatest拆成 great 和 ##est 。
对于subword算法的具体介绍,可参考https://zhuanlan.zhihu.com/p/86965595 这篇知乎。
GPT2
pytorch版本实现代码:https://github.com/huggingface/transformers/tree/master/src/transformers/models/gpt2
1.思想原理
GPT2论文名是:Language Models are Unsupervised Multitask Learners,顾名思义,GPT2的主张就是:语言模型是无监督多任务学习器。
注意两个词:无监督,多任务。作者认为语言模型在无监督训练过程中就已经学习到了多任务能力,可以用来做多种不同的NLP任务而不需要进行微调(zero-shot)。而实现这个的关键就是模型的容量,GPT2模型有15亿参数,在8个语言模型数据集中的7个获得了SOTA。

作者认为,学习一个特定任务的模型就是对条件概率分布 p(output|input)建模,而学习一个通用的多任务模型不仅要将input作为条件,还要将task作为条件,对p(output|input, task)进行建模。
而task conditioning的实现有两种方式:
第一种是模型层的( architectural level),也就是针对不同的任务构建不同的模型结构来训练;
第二种是算法层的(algorithmic level),作者指出:language provides a flexible way to specify tasks, inputs, and outputs all as a sequence of symbols,也就是语言可以提供一种灵活的方式将tasks, inputs, 和outputs作为语言序列输入的一部分。比如:翻译任务的训练样本可以写成(translate to french, english text, french text),阅读理解任务的训练样本可以写成(answer the question, document, question, answer)。以这种形式可以训练一个可以实现多任务的模型,这种是有监督的多任务训练。
但是作者认为语言模型可以进行无监督的多任务学习,而不需要显示的指出哪些是要预测的输出。
有监督训练的目标函数和无监督训练的目标函数相同,但是有监督训练只是预测序列的子集,而且有监督训练的目标函数和无监督训练的目标函数的全局最小也是一样的。
既然都一样,那么问题就变成了无监督训练能否像有监督训练一样收敛,作者初步的实验证实了是可以的,但是速度要比有监督训练要慢。
2.数据集
既然要语言模型可以实现多任务,除了模型要大要强之外,数据集也要足够大且足够多样且涵盖多个领域。

作者构建了一个40G的数据集WebText,这个数据集的数据隐含了多个不同的NLP任务,可以让模型隐式的学到多任务的能力,比如下图,就隐含了英法互译的翻译任务。

3.输入表示
用的还是subword算法,具体可以看原论文
4.模型
作者还是用的GPT模型结构,但也做了一些改动:layer normalization移到了每个子模块的输入端,在最后的self-attention模块后添加了一个额外的layer normalization,残差层参数初始化根据网络深度进行调节,词表扩大,batchsize扩大

给了四个尺寸的模型。

5.模型体验
GPT2的文本生成能力很强大,有兴趣可以通过这个工具来体验一下
AllenAI GPT-2 Explorer(https://gpt2.apps.allenai.org/?text=Joel%20is)
参考:https://zhuanlan.zhihu.com/p/57251615
https://www.cnblogs.com/zhongzhaoxie/p/13064404.html
GPT3
作者提出了巨型网络GPT3,有1750亿参数。模型结构和GPT2一样,有一点改动:use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer,这个我还没有细究。
作者认为现在主流的做法是预训练+微调,但是微调还是需要几千上万的监督数据,而人类呢,humans can generally perform a new language task from only a few examples or from simple instructions,人类可以仅通过个别的例子或者一个简单的任务说明,就可以实现一个新的语言任务。所以说呢,现在的NLP模型和人类还是有很大差距的。
因此,作者提出了GPT3,对于所有的NLP任务,GPT3在应用时不进行梯度更新或者微调,仅使用任务说明和个别示例与模型进行文本交互。最终GPT3在许多NLP的数据集上都有很好的表现。
另外值得一提的是,GPT3的文本生成是真的强大,写出来的文章连专业评估者都很难区出来分到底是人写的还是模型写的。
模型训练就不说了,就是在大型数据集上训练。
作者抛弃了fine tuning,因为作者认为虽然fine tuning效果很好,但是还是需要很多标签数据,而且会导致模型学到一些虚假的特征,造成过拟合,使模型泛化性能变差。
这里着重说一下作者提出来的测试GPT3模型在特定任务上性能的三种方式

few-shot
在inference time,只给模型某个特定任务的说明和一些示例,但不进行权重更新
one-shot
在inference time,只给模型某个特定任务的说明和一个示例,不进行权重更新
zero-shot
在inference time,只给模型某个特定任务的说明,不给示例,不进行权重更新
具体怎么实现的,作者在原论文里有提到这一点:

参考:https://zhuanlan.zhihu.com/p/174782647
https://www.cnblogs.com/dagis/p/13424245.html
原创不易,转载请注明出处!

