
热门标签
热门文章
- 1C#等语言、反射机制实现简单 智能语音人机交互(2)-- 皓月_c# ai对话
- 2分类算法之决策树C4.5算法_决策树c4.5sunny rain overcast hot mild cool
- 3AI人工智能的使用教程:从入门到精通_ai人工智能使用
- 4swagger的ApiImplicitParam注解中的required属性不起作用_@apiimplicitparam的defaultvalue不生效
- 5[实战]openGauss之AI4DB,领先的开源数据库自治运维平台DBMind
- 6python人工智能应用开发方案_最全的Python+人工智能学习大纲
- 7巧用Stable Diffusion,实现不同风格的LOGO设计|实战篇幅,建议收藏!_stablediffusion 生成logo的提示词
- 8用Python实现自动向ChatGPT(GPT3.5)提问并获取回答 v2.0_python使用chatgpt自动化脚本输入prompt
- 9solidity转账函数的实现(基于transfer)_solidity transfer函数
- 10如何用DockerFile部署项目
当前位置: article > 正文
FedRS: Federated Learning with Restricted Softmax for Label Distribution Non-IID Data, KDD 2021
作者:不正经 | 2024-04-06 20:27:56
赞
踩
fedrs: federated learning with restricted softmax for label distribution non
首先讲道理
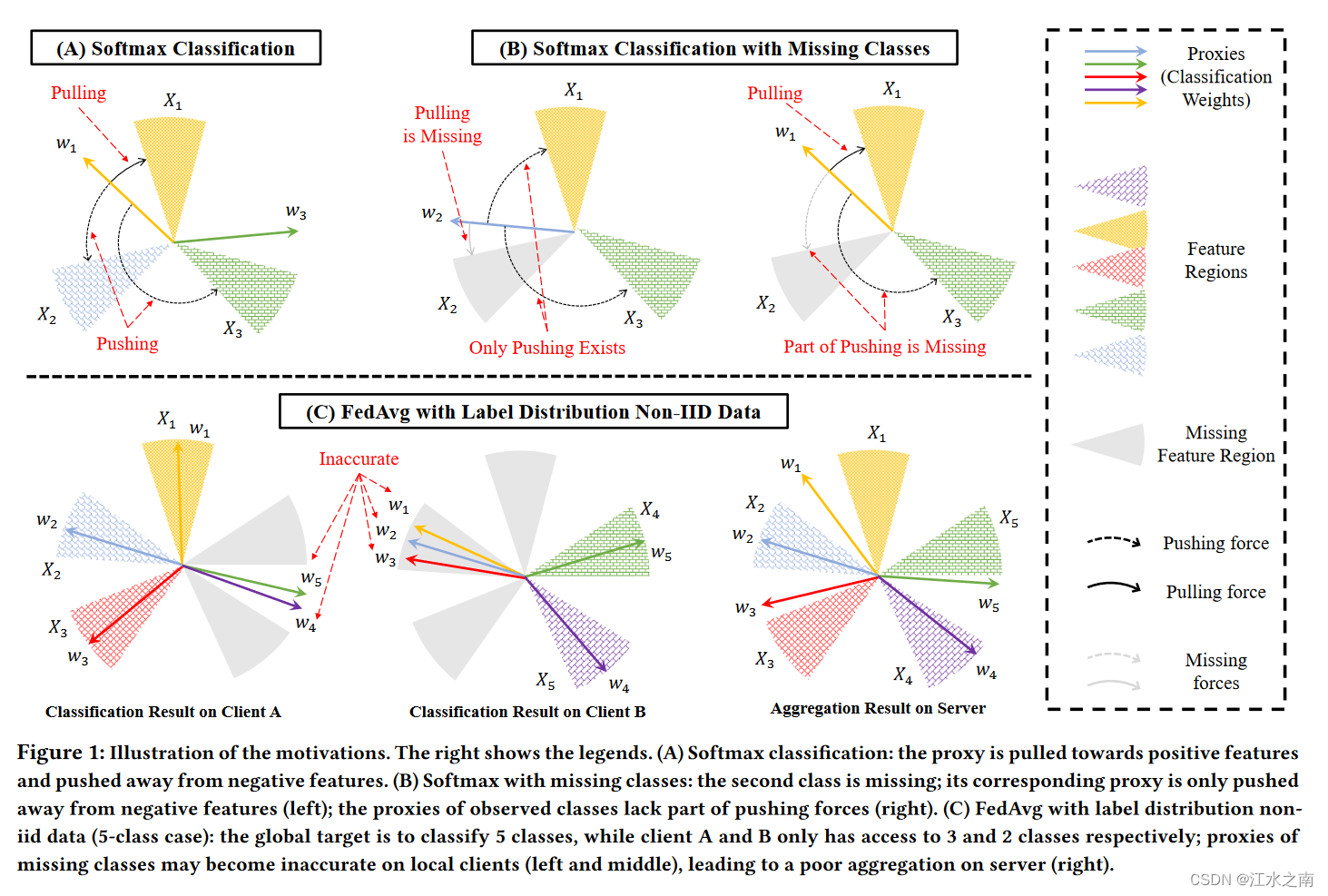
本文探讨在Label Shift的场景下(即大多数论文实验的数据划分设置),提出Restricted Softmax来缓解异质性。
Softmax会让结果拉向(Pull)自己的类别,并使结果远离(Push)不属于自己的类别。如A所示,对于X1样本,Softmax将它拉近(Pull)所属于的区域,并且将它推离(Push)不属于自己的区域。两种力共同作用。
客户的训练数据只包含几个类别。把他包含的类的样本成为正样本,反之则为负样本。如B所示,由于用户缺少负样本的指导,Softmax就不知道怎么Push原理不存在的负样本。同时,当拿他训练的模型遇到负样本时,又不知道往哪Pull。即图B所示的两个Missing。
图C举了个FedAvg的栗子。A有三个类的数据,B有2个类的数据。A训练的模型只会分他有的那三个类,另外两个类就随便弄了,没有学习到相应的分类知识。B同理。所以当把A和B的模型进行聚合时,就不准了。这钟现象与Softmax的作用效果有关。
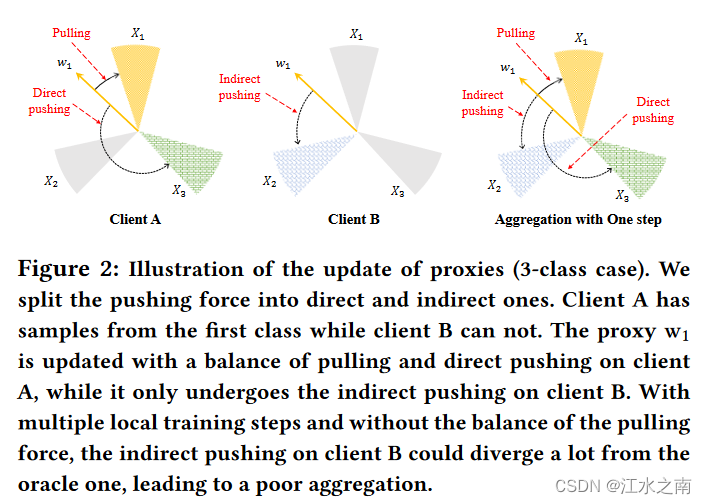
当进行多轮Local training后,由于不正确的指导(pulling and pushing)本地就会越来越偏。进而导致不好的聚合。
然后提方法
既然作者说Softmax有锅,那就对它进行改进!提出了受限的Softmax

向Softmax里加权重参数,限制它更新不准确的方向。核心思想就是限制Pushing的力量(你不知道咋退离你就省点劲,少推点,反正也不准)。与此同时,作者说这样也会使特征向更准确的方向进行更新。实验部分说,α取0.5效果就不戳。
杂谈
没啥说的,我是废物
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/374123
推荐阅读
相关标签

