
- 12021年G3锅炉水处理报名考试及G3锅炉水处理模拟考试_臭屁的玻璃件及其电位与溶液中氢离子浓度成
- 2网页适配 iPhoneX,就是这么简单_chrome调试ios安全距离
- 3手机免root安装kali linux 步骤,离线版(最终可行版)_kali linux手机版安装
- 4Android/iOS APP备案流程指南
- 5vue错误:Property or method "**" is not defined 和 Invalid handler for event "click"_property or method is not defined
- 6android viewpager 内容有的不能滑动,关于viewpager无法滑动
- 7欧拉操作系统在线安装mysql8数据库并用navicat premium远程连接_欧拉系统安装mysql数据库
- 8单神经元自适应控制算法,bp神经网络缺点及克服_bp神经网络能优化单个的因素吗
- 9spring-framework-3.2.16.RELEASE源码编译并导入eclipse_org.springframework:spring-beans:3.2.16.release
- 10组合式(Composition)API_组合式api
An All-In-One Convolutional Neural Network for Face Analysis_fg-net(leave-one-out)fg-net (mf1)
赞
踩
https://arxiv.org/abs/1611.00851
摘要
我们提出了一个多用途的算法,使用单一的深度卷积神经网络(CNN)同时进行人脸检测,人脸对齐,姿态估计,性别识别,微笑检测,年龄估计和人脸识别。本文提出的方法是一个多任务学习框架,该框架规范了CNN的共享参数,并在不同领域和任务之间建立协同作用。大量的实验表明,该网络对人脸有更好的理解,并且在大多数任务中都取得了最先进的结果。
1 引言
人脸分析在人脸识别、情绪分析、生物特征分析、安全等方面都是一个具有挑战性和积极研究的问题。虽然使用基于cnn的方法后,无约束人脸检测和人脸验证等少数具有挑战性的人脸分析任务的性能有了很大提高,但由于缺乏大量公开的训练数据,人脸对齐、头部姿态估计、性别和微笑识别等任务仍然具有挑战性。此外,所有这些任务都被当作单独的问题来处理,这使得它们在集成到端到端系统时效率低下。例如,一个典型的人脸识别系统需要从给定的图像中检测并对齐人脸,然后才能确定其身份。这将导致不同模块之间的错误累积。即使上述任务是相关的,现有的方法也没有利用它们之间的协同作用。最近有研究表明,联合学习相关任务可以提高单个任务[59],[36],[5]的表现。
在本文中,我们提出了一种新的CNN模型,它可以同时解决人脸检测、特征点定位、姿态估计、性别识别、微笑检测、年龄估计和人脸验证与识别等任务(见图1)。我们选择这组任务是因为它们的应用范围很广。我们在一个多任务学习(MTL)框架(Caruana[3])中联合训练一个CNN,这样CNN的较低层的参数在所有任务之间共享。通过这种方式,较低的层学习了所有任务的通用表示,而较高的层对给定的任务更具体,这减少了共享层中的过度拟合。因此,我们的模型能够学习不同任务的鲁棒特征。使用多个任务使网络能够有效地了解来自不同分布的数据之间的相关性。这种方法在端到端系统中节省了时间和内存,因为它可以同时解决任务,并且需要为每个任务存储一个单一的CNN模型,而不是单独的CNN。据我们所知,这是第一个使用一个CNN以端到端方式同时解决多种面部分析任务的工作。

图1:该方法可以同时检测人脸,预测任何无约束的人脸图像中的特征点位置、位姿角度、微笑表情、性别、年龄以及身份。
我们使用Sankaranarayanan等人[41]为人脸识别任务训练的CNN模型初始化网络。我们认为,一个预先训练过人脸识别任务的网络具有较细的人脸信息,可以用来有效地训练其他人脸相关任务。特定任务的子网络从这个网络的不同层分支出来,取决于它们是依赖于脸部的局部信息还是全局信息。完整的网络经过端到端训练后,可以显著提高人脸识别性能和其他人脸分析任务的性能。本文对其进行了研究:
1)我们提出了一种新的CNN架构,可以同时进行人脸检测、特征点定位、姿态估计、性别识别、微笑检测、年龄估计和人脸识别与验证。
2)设计了一个MTL训练框架,使网络参数规范化。
3)对于这些任务中的大多数,我们在挑战无约束数据集方面取得了最先进的性能。
Ranjan等人[36]最近提出了HyperFace,可以同时完成人脸检测、特征点定位、姿态估计和性别识别等任务。本文的方法与HyperFace有以下几个不同之处。首先,我们另外解决了微笑检测、年龄估计和人脸识别的问题。其次,我们的MTL框架通过在多个数据集上进行训练,利用了基于领域的正则化,而HyperFace只在AFLW[24]上进行训练。最后,我们使用来自人脸识别任务[41]的权值来初始化我们的网络,而HyperFace网络使用来自AlexNet[25]的权值来初始化。
本文组织如下。第二节回顾了密切相关的工作。第三节详细描述了所提出的算法。第四节提供了我们的方法对挑战数据集的所有任务的结果。最后,第五部分对全文进行了总结,并对今后的工作进行了简要的讨论。
2 相关工作
Caruana[3]首先对多任务学习进行了详细的分析。此后,有几种方法利用MTL来解决计算机视觉中的许多问题。在[59]中提出了联合学习人脸检测、特征点定位和姿态估计的方法,随后扩展到[60]中。它使用了混合树模型和共享的部分池,其中一个部分代表一个特征点。最近,一些方法已经将MTL框架与深度cnn相结合来训练人脸相关的任务。Levi 等[27]提出了一种同时估计年龄和性别的CNN。HyperFace[36]通过融合CNN的中间层来改进特征提取,训练一个MTL网络用于人脸检测、特征点定位、姿态和性别估计。Ehrlich等人[10]提出了一种多任务受限的Boltzmann 机制来学习面部属性,Zhang等人[56]将其与头位估计和面部属性推断联合训练,改进了特征点定位。虽然这些方法在小任务集上执行MTL,但它们不允许像本文所提议的那样训练大量相关任务集。
为了改进个人的面部分析任务,已经进行了重要的研究。目前基于深度CNNs的人脸检测方法,如DP2MFD[35]、Faceness[50]、Hyperface[36]、Faster-RCNN[20]等,明显优于TSM[59]、NDPFace[30]等传统方法。
由于缺乏足够的训练数据,目前只有少数方法将深度cnn用于人脸对准任务[56]、[26]、[58]、[36]。现有的特征点定位方法主要集中在近正脸[2]、[38]、[22],这些位置的关键点都是可见的。最近的一些方法,如PIFA[21]、3DDFA[58]、HyperFace[36]和CCL[57],已经探索了不同位姿角度下的面部对齐。
姿态估计的任务是推断一个人的头部相对于相机的方向。除了TSM[59]、FaceDPL[60]和HyperFace[36]之外,对于无约束图像的这个任务研究并不多。
将无约束图像的性别分类和微笑分类看作是面部属性推理的一部分。最近,Liu等[31]发布了CelebA数据集,该数据集包含约20万张近正面图像,包含性别、微笑等40个属性,加速了[46]、[36]、[55]、[10]这一领域的研究。世界的人脸[13]挑战数据集进一步加速了[28]、[44]、[53]不同尺度、不同光照、不同姿态的面向任务的研究。
年龄估计是一项根据一个人的面部图像来确定其真实年龄或表面年龄的任务。在使用深度CNNs[40],[6]进行表观年龄估计的挑战上,很少有方法已经超越了人为误差。
人脸验证是预测两张脸是否属于同一个人的任务。最近的方法如DeepFace [43], Facenet [42],VGG-Face[34]通过训练数百万注释数据的deep CNN模型,显著提高了LFW[17]数据集的验证精度。然而,对于视角和光照变化较大的无约束人脸,这仍然是一个具有挑战性的问题。为了解决这个问题,我们使用MTL框架对CNN参数进行正则化,只使用50万个样本(CASIA[51])进行训练。
3 提出的方法
我们提出了一种能同时检测人脸、提取关键点和姿态角度、检测笑容表情、年龄和性别的多用途CNN。此外,它还为每个人脸分配了一个身份描述,可以用于人脸识别和验证。该算法在MTL框架中进行训练,在不同的人脸相关任务之间建立协同作用,提高了每个任务的性能。在本节中,我们讨论了MTL在人脸分析方面的优势,并提供了网络设计、训练和测试的详细程序
- 多任务学习
通常,人脸分析任务需要一个裁剪过的人脸区域作为输入。深度CNN对人脸进行处理,获得一种表示,并提取与任务相关的有意义的信息。根据[52]的报道,CNN的底层学习的特征与一般的面部分析任务是相同的,而上层则是针对个别任务的。因此,我们在不同的任务之间共享CNN的低层参数,从而产生一个通用的人脸表示,然后由特定任务的层处理生成所需的输出(图2)。Goodfellow等[14]将MTL解释为深度CNN的正则化方法。在我们的框架中使用的MTL方法可以通过以下两种正则化来解释

图2:深度CNN架构下的一般多任务学习框架。较低层在所有任务和输入域之间共享。
1)基于任务的正则化:将给定任务 t i t_i ti在共享参数 θ s θ_s θs和与任务相关的参数 θ t i θ_{t_i} θti下的代价函数记为 J i ( θ s , θ t i ; D ) J_i(θ_s,θ_{t_i};D) Ji(θs,θti;D),其中D为输入数据。对于孤立学习,可以使用(1)计算出最优网络参数 ( θ s ∗ , θ t i ∗ ) (θ_s^*,θ_{t_i}^*) (θs∗,θti∗):
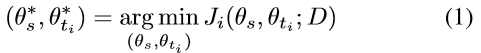
对于MTL,通过最小化每个任务的损失函数的加权和,可以得到任务 t i t_i ti的最优参数,如式(2)所示。任务 t i t_i ti的损失权重记为 α i α_i αi:
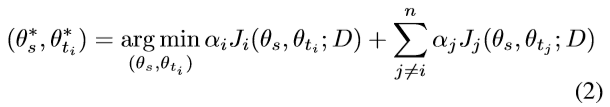
因为其他任务只对共享参数的学习有帮助,他们可以被视为在给定的任务 t i t_i ti下的对参数 θ s θ_s θs的正则化 R i R_i Ri,如(3)所示。因此,MTL收缩θs这样在所有任务中共享的学习参数向量的解空间,从而减少过度拟合,使优化过程中找到一种更鲁棒的解决方案。
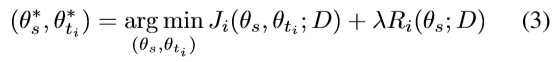
2)基于域的正则化:对于人脸分析任务,我们没有大的数据集可以对人脸边界框、基准点、位姿、性别、年龄、笑容、身份信息进行标注。因此,我们采用针对任务相关数据集 D i D_i Di对多个cnn进行训练的方法,并共享其参数。这样一来,共享参数可适应于完整的域集合(D1,D2,…Dd),而不是适合于某个任务特定的域。另外,训练样本总数增加到100万左右,有利于深度cnn的训练。表1列出了用于训练我们的all-in-one CNN的不同数据集,以及它们各自的任务和样本大小。

- 网络架构
一体式CNN架构如图3所示。我们从Sankaranarayanan等人[41]的预训练人脸识别网络开始。网络由七个卷积层和三个完全连接的层组成。我们将其作为训练人脸识别任务的骨干网络,并将其前六个卷积层的参数与其他人脸相关任务共享。采用参数化线性修正单元(PReLUs)作为激活函数。我们认为,一个预先接受人脸识别任务训练的CNN提供了一个基本的人脸分析任务,因为过滤器保留了有区别的人脸信息。

图3:我们所提方法的CNN架构。每一层由filter kernel的大小、layer的类型、feature map的数量和filter stride来表示。橙色代表Sankaranarayanan等人[41]的预训练网络,蓝色代表MTL的添加层。
我们将任务分为两组:1)受试者无关任务,包括人脸检测、关键点定位和可见性、姿态估计和微笑预测;2)受试者有关任务,包括年龄估计、性别预测和人脸识别。与HyperFace[36]类似,我们融合了第一、第三和第五卷积层来训练受试者无关的任务,因为它们更多地依赖于网络较低层的局部信息。我们在这些层上分别附加两个卷积层和一个池化层,得到一致的feature map size为6×6。增加了降维层,将特征图的数量减少到256张。接下来是维度2048的全连接层,它形成了受试者无关的任务的通用表示。此时,特定的任务被分支到各维度512的完全连接的层中,然后分别是输出层。
年龄估计和性别分类等受试者有关任务是在执行最大池化操作后,从主干网的第六卷积层分支出来的。因此获得的全局特征被馈给一个三层全连接网络的每一个这些任务。我们不共享第七卷积层参数,以适应专门的人脸识别任务。使用任务特有的损失函数对整个网络进行端到端训练。 - 训练
训练CNN模型包含五个子网络,子网络之间共享参数。人脸检测、特征点定位与可见性、姿态估计等任务都在单一子网络中进行训练,因此使用一个通用数据集(AFLW[24])进行训练。其余的微笑检测、性别识别、年龄估计和人脸识别任务则使用不同的子网络进行训练。在测试时,这些子网络被融合成一个的All -in-one CNN(图3)。使用Caffe[19]同时对所有任务进行端到端训练。在这里,我们讨论了它们各自的损失函数和训练数据集。
1)人脸检测、关键点定位和姿态估计:这些任务的训练方法与HyperFace[36]相似,使用AFLW[24]数据集。我们从数据集中随机选择1000张图像进行测试,并使用剩余的图像进行训练。我们使用选择性搜索[45]算法从图像中生成人脸的区域建议。与ground truth boundingbox交并比(IOU)重叠大于0.5的区域作为正例,IOU<0.35的区域作为负例,使用softmax损失函数训练检测任务。将人脸特征点、关键点可见性和位姿估计作为回归问题,用欧几里得损失进行训练。在训练过程中,只有IOU>0.35区域对反向传播有贡献。
2)性别识别:它是一个类似于人脸检测的二元分类问题。表1列出了用于训练性别的数据集。训练图像首先使用面部关键点对齐,这些关键点要么由数据集提供,要么使用HyperFace[36]计算。使用交叉损耗 L G L_G LG进行训练,如(4)所示
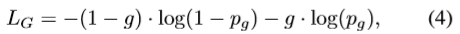
其中 g = 0 g=0 g=0代表男性, g = 1 g=1 g=1代表女性, p g p_g pg是输入人脸是女性的预测概率。
3)Smile检测:训练Smile属性,使网络对表情变化具有鲁棒性,用于人脸识别。我们使用CelebA[31]数据集进行训练。与性别分类任务类似,图像在通过网络之前被对齐。损失函数 L S L_S LS为(5)
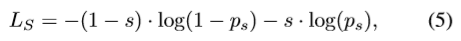
其中 s = 1 s=1 s=1代表笑脸,否则 s = 0 s=0 s=0, p s p_s ps是输入人脸是微笑的预测概率。
4)年龄估计:我们将年龄估计任务描述为一个回归问题,在这个问题中,网络学习从人脸图像中预测年龄。我们使用IMDB+WIKI[40]、Adience[27]和MORPH[39]数据集进行训练。Ranjan等人已经展示过。[37]在给定年龄标准差的情况下,高斯损失比欧几里德损失更适用于表观年龄估计。然而,当预测年龄远离真实年龄时,高斯损耗梯度接近于零(图4),这减慢了训练过程。因此,我们使用这两个损失函数的线性组合,用λ加权,如(6)所示
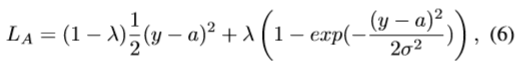
其中 L A L_A LA是年龄损失,y是预测的年龄,a是真实的年龄, σ σ σ是标注的年龄值的标准差。在训练开始时,将 λ λ λ训练初始化为0,之后增加到1。在我们的实现中,我们最初保持 λ = 0 λ= 0 λ=0,在20k迭代后将其切换为1。如果训练集不提供,则 σ σ σ值为3。

图4:欧几里得和高斯损失函数
5)人脸识别:我们使用CASIA[51]数据集的10548个受试者训练人脸识别任务。在将图像通过网络传递之前,使用HyperFace[36]对图像进行对齐。我们使用多类交叉损失函数LR进行训练,如(7)所示
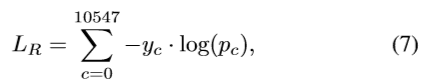
其中如果样本属于c类, y c = 1 y_c=1 yc=1,否则为0。一个样本属于c类的预测概率由 p c p_c pc给出。
最后的总损失L为各损失函数的加权和,如式(8)
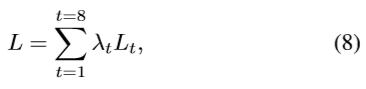
其中 L t L_t Lt是损失,而 λ t λ_t λt是与任务t对应的损失权值。损失权值的选取是基于经验的。我们给回归任务赋予了更高的权重,因为它们比分类任务的损失程度更低。 - 测试
我们在测试期间部署了一个两阶段流程,如图5所示。在第一阶段,我们使用选择性搜索[45]从一幅测试图像中生成区域建议,通过我们的 all-in-one 网络得到检测分数,姿态估计,特征点和能见度。我们使用迭代区域建议和基于特征点的NMS[36]来过滤非面孔,改进基准和姿态估计。

图5:测试期间所提方法的端到端流程
在第二阶段,我们使用所获得的特征点来使用相似性变换将每个检测到的人脸对齐到一个规范视图。排列整齐的面孔和翻转过来的面孔再次通过网络传递,以获得微笑、性别、年龄和身份信息。我们使用身份网络倒数第二完全连接层的512维特征作为身份描述符。
5 实验
由于缺乏适当的评估协议,该方法对训练它的所有任务进行评估,但关键点可见性除外。我们选择HyperFace[36]作为人脸检测、姿态估计、特征点定位和性别识别的比较基线。对于人脸识别任务,以Sankaranarayanan等人的[41]方法作为基线,该方法作为初始化。
- 人脸检测
我们在AFW[59]、PASCAL[48]、和FDDB的[18]数据集上评估人脸检测任务。所有这些数据集都包含了在外观、规模、视角和光照方面有很大变化的人脸。为了评估AFW和PASCAL数据集,我们在FDDB上对网络的人脸检测分支进行了优化。为了评估FDDB数据集,我们根据10倍交叉验证实验[18]进行微调。
AFW和PASCAL数据集的召回率曲线,FDDB数据集的ROC曲线如图6所示。从图中可以看出,我们的方法在AFW和PASCAL数据集上取得了最先进的性能,平均平均精度(mAP)分别为98.5%和95.01%。在FDDB数据集上,我们的方法比大多数报告的算法性能更好。它比Faster-RCNN[20]和Zhang等人[54]的召回率要低,因为FDDB的小面在任何区域方案中都没有被捕捉到。在我们的检测评估中比较的其他近期发表的方法包括DP2MFD [35], Faceness[50],猎头[33],联合级联[5],结构化模型[48],Cascade CNN [29], NDPFace [30], TSM[59],以及三个商业系统Face++, Picasa和Face.com。

图6:对(a) AFW数据集,(b) PASCAL面数据集和© FDDB数据集的性能评估。图例中的数字是对应数据集的平均平均精度。 - 特征点定位
我们评估我们在AFW[59]和AFLW[24]数据集上的表现,因为它们包含了人脸视角的巨大变化。计算IOU>0.5的建议区域的测试人脸特征点位置平均值作为预测特征点。对于AFLW[24]评估,我们遵循[58]中给出的协议。我们从我们的测试集随机创建了450个样本的子集,其中偏航角为 [ 0 ° , 30 ° ] , [ 30 ° , 60 ° ] 和 [ 60 ° , 90 ° ] [0°,30°],[30°,60°]和[60°,90°] [0°,30°],[30°,60°]和[60°,90°]的样本各占1/3。表2比较了我们的方法与最近的人脸对齐方法的归一化平均误差(NME),适应于人脸profoling[58],每个偏航箱。我们的方法显著优于以前的最佳HyperFace[36],将错误降低了30%以上。一个较低的标准差为0.13,表明了当位姿角变化时,特征点预测是一致的。

表2:AFLW测试集上人脸对准结果的NME(%)。
对于AFW[59]评估,我们遵循[57]中描述的方案。图7(a)显示了与最近发表的方法的比较,如CCL[57]、HyperFace[36]、LBF[38]、SDM[47]、ERT[22]和RCPR[1]。在非约束人脸和轮廓人脸上,该算法以小于5%的NME对超过95.5%的测试人脸进行预测,明显优于现有方法。但对于简单人脸,缺少像素级的关键点精确定位,这可以从曲线的低端推断出来。这些算法大部分使用级联阶段回归来改善定位,这比网络的单前向传递要慢。

图7:(a)特征点定位任务、(b)位姿估计任务的AFW数据集性能评价。在图例中的数字是(a) NME小于5%,(b)绝对偏航误差小于或等于15◦的测试面百分比 - 姿态估计
我们对AFW[59]数据集进行了姿态估计。根据[59]中定义的协议,我们只计算偏航角的绝对误差。由于真实偏航角是在15°的倍数提供,我们舍入我们的预测偏航到最近的15◦进行评估。图7(b)显示了我们的方法与HyperFace [36], Face DPL [60], Multiview HoG[59]和face.com的比较。很明显,提出的算法比其他竞争的方法更好,能够预测99%以上的人脸在±15◦范围内的偏航。 - 性别和微笑识别
我们评估了大型名人脸属性(CelebA)[31]和世界[13]数据集的ChaLearn脸的微笑和性别识别性能。虽然CelebA[31]有多种测试对象,但大多数都是正面脸。[13]在规模和视点上有很大的变化。我们取带有IOU>0.5的给定面部的区域建议的预测分数的平均值,作为我们的微笑和性别属性的最终分数。表3比较了与最近发表的方法性别和微笑的准确性。在CelebA[31]上,我们在性别准确性方面胜过所有的方法。我们的微笑准确率只有在走路和学习[46]时才会降低,[46]使用其他上下文信息来提高预测准确率。在对世界[13]的人脸训练集进行评估之前,对网络的性别和微笑分支进行微调。我们实现了最先进的性能,性别和微笑分类的验证集。

表3:适用于CelebA(左)和世界脸(右)的Accuray (%) - 年龄预测
我们使用Chalearn LAP2015[12]表观年龄估计挑战数据集和bg - net[15]老化数据库来评估我们的年龄估计任务。我们在挑战数据集的训练集上对网络的年龄-任务分支进行微调,并在验证集上显示结果。对于FG-Net[15],我们遵循标准的leave - one - out协议(LOPO)。表四列出了这两个数据集的评估误差。我们超越了0.34的人为错误,并执行可与最先进的方法进行比较,在Chalearn LAP2015[12]数据集上获得了0.293的错误。在FG-Net[15]上,我们显著优于其他方法,实现了2年的平均误差。 - 人脸识别/验证
我们在IARPA Janus Benchmark-A (IJB-A)[23]数据集上评估人脸识别和验证任务。数据集包含500个受试者,共计25,813张图像,包括5,399张静态图像和20,414个视频帧。它包含具有极端视点、分辨率和光照的面,使它比常用的LFW[17]数据集更具挑战性。
对于IJB-A数据集,给定一个包含多个面孔的模板,我们通过对单个面孔描述符进行媒体池化来生成一个公共向量表示,如[41]中所述。一种幼稚的方法来衡量一个模板对的相似性,是采用它们的描述符之间的余弦距离。更好的方法是学习一个相似对对应的特征比较接近,不同对对应的特征比较远的嵌入空间。我们使用数据集提供的训练分割来训练一个三重概率嵌入(TPE)[41]。表V与IJB-A上最近发布的方法进行了比较。我们取得了面部识别任务的最新成果。尽管我们在验证任务上的性能与模板自适应学习(Crosswhite等人[9])相当,但我们实现了显著更快的查询时间(每对图像的人脸检测后0.1秒)。对于所有指标,我们得到了比基线网络[41]持续提高2%到3%的结果。
我们还将我们的性能与表六中的端到端人脸识别方法进行了比较。我们的方法优于现有的端到端系统,表明训练管道上的所有任务,减少了错误。我们看到了双重的改进,即。,大约80%的性能提高是由于改进了身份描述符,20%的性能提高是由于改进了人脸对齐。 - 运行时间
我们在一台拥有8个CPU核心和GTX titanium - x GPU的机器上实现了我们的一体机网络。处理一幅图像平均需要3.5秒。速度方面的主要瓶颈是生成区域建议并将每个建议通过CNN的过程。我们方法的第二阶段只需要0.1秒的计算时间。
5 结论及未来工作
本文提出了基于任务的人脸检测、人脸对齐、姿态估计、性别和微笑分类、年龄估计和人脸验证与识别的同时检测方法。在可用的无约束数据集上的广泛实验表明,我们实现了大多数这些任务的最新结果。它们都使用MTL框架。这项研究表明,独立于主体的任务从基于领域的正则化和人脸识别任务的网络初始化中获益。此外,与[41]相比,MTL在人脸验证和识别性能上的改进表明,MTL有助于学习鲁棒特征描述符。未来,我们计划将该方法扩展到其他与人脸相关的任务中,使算法具有实时性。图8显示了我们方法的几个定性结果。

图8:我们方法的定性结果。蓝色的方框表示检测到的面孔。绿点是地标性的位置。每个面的姿态估计显示在盒子的顶部的顺序滚动,俯仰和偏航。预测的身份、年龄、性别和微笑属性显示在脸框下面。尽管算法会为所有的面孔生成这些属性,但为了更好的图像清晰度,我们只会为出现在IJB-A数据集中的主题显示它们。