- 1微信公众平台开发简介
- 2假设检验的P值_假设检验指标p
- 3Python深度学习之路:TensorFlow与PyTorch对比【第140篇—Python实现】
- 4YOLOv9改进策略:注意力机制 | SKAttention注意力效果优于SENet
- 5CSS动画(快速入门)
- 6不再错过短视频风口,用python一键生成短视频,就是这么简单!_图文生视频接口
- 7Google Chrome 旧版本下载地址_chrome old version download
- 8Long Short-Term Memory (LSTM)_“long short-term memory,” neural comput
- 9灰色关联分析_灰色关联csdn
- 10vue3 ---- 递归组件生成menu菜单 && 路由守卫鉴权_el-menu-item onmouseenter 箭头函数
给开源大模型带来Function Calling、 Respond With Class
赞
踩
前言
> 推荐电脑阅读
OpenAI 在他的多个版本的模型里提供了一个非常有用的功能叫 Function Calling,就是你传递一些方法的信息给到大模型,大模型根据用户的提问选择合适的方法,然后输出给你,你再来执行。
为了便于理解,我们从聊天开始,你发给模型一个问题,是使用类似下面的json格式:
- [{
- "role": "user",
- "content": "What's the weather like in San Francisco, Tokyo, and Paris?"
-
-
- }]
模型会返回一个json格式数据给你。这里我们问的是当前的天气问题,显然大模型不可能知道(当然了,很多模型服务自己内置了一些包括检索等插件,这是另外一个话题,单纯的大语言模型是无法调用外部工具来获取外部信息的。),所以这里我们需要提供一个计算天气的函数给他。他会在你问的确实是天气的情况下,选择这个计算函数,并且将问题里的信息拆解成函数参数提供给你,这样你可以根据他给到的信息直接执行函数。
我们来看看加了“函数” 加持的样子
相比第一个请求,我们加了一个tools字段,里面详细的描述了函数的名称,用法,参数列表,参数含义等等。相应的大模型会在他的返回字段里,多一个tool_calls 字段。你从这里可以拿到被选中的函数的具体信息,包括从问题抽取出来的参数值。接着你根据这些信息具体的调用你的函数,从而完成最后的天气调用。
所以实际上 function calling 的作用很简单,根据问题,根据你提供的函数列表,选择合适的一个或者多个函数给到你,你自己来执行。
那如果我想在开源大模型里用这个功能,怎么办呢?这不,Byzer-LLM 提供了一个比 OpenAI 更加易用的 Function Calling能力, 而且还额外送了个新的礼包:Respeond With Class, 就是真的把大模型当做一个方法调用,返回值要符合函数返回值的定义。来,我们一一来解读。
下载一个开源模型和安装 Byzer-LLM
首先,我们必须有一个开源的模型,这里我们从 ModelScope 下载 QWen-70B 大模型。选择 ModelScope 是因为 HuggingFace 下载速度太慢, 选择 QWen-70B 是因为 Function Calling 是比较吃大模型能力的,较为复杂的函数调用,还是需要大一点的模型。
从 ModelScope 下载模型:
git clone https://modelscope.cn/qwen/Qwen-72B-Chat.git接着我们使用 [Byzer-LLM](https://github.com/allwefantasy/byzer-llm) 部署下模型。Byzer-LLM 一个基于Ray的,支持大模型预训练,微调和部署的 分布式Python 库。
在你的有显卡的机器(推荐 Ubuntu22 / 8卡 3090或4090)上安装下 Byzer-LLM:
- git clone https://github.com/allwefantasy/byzer-llm
- cd byzer-llm
- pip install -r requirements.txt
- pip install -U vllm
- pip install -U byzerllm
-
-
- ray start --head
部署 QWen 72B
假设你的模型地址为:
/home/byzerllm/models/Qwen-72B-Chat那么你可以直接复制黏贴下面的代码,使用 python 运行即可。
运行完成后,你可以简单测试下是不是可以聊天了:
- t = llm.chat_oai([{
- "content":'''你好,你是谁''',
- "role":"user"
- }])
-
-
- t[0].output
输出内容大概像这样:
- 我是通义千问,由阿里云开发的人工智能助手。我被设计用来回答各种问题、提供信息和与用户进行对话。有什么我可以帮助你的吗?
- 说明部署没问题。
准备一些函数
比如,用户经常会问,"最近xxx" 之类的问题,我们需要提取出精确的时间后改写query方便后续应用处理,这种情况,我们可以定义两个函数:
- from typing import List,Dict,Any,Annotated
- import pydantic
- import datetime
- from dateutil.relativedelta import relativedelta
-
-
- def compute_date_range(count:Annotated[int,"时间跨度,数值类型"],
- unit:Annotated[str,"时间单位,字符串类型",{"enum":["day","week","month","year"]}])->List[str]:
- '''
- 计算日期范围
- Args:
- count: 时间跨度,数值类型
- unit: 时间单位,字符串类型,可选值为 day,week,month,year
- '''
- now = datetime.datetime.now()
- now_str = now.strftime("%Y-%m-%d %H:%M:%S")
- if unit == "day":
- return [(now - relativedelta(days=count)).strftime("%Y-%m-%d %H:%M:%S"),now_str]
- elif unit == "week":
- return [(now - relativedelta(weeks=count)).strftime("%Y-%m-%d %H:%M:%S"),now_str]
- elif unit == "month":
- return [(now - relativedelta(months=count)).strftime("%Y-%m-%d %H:%M:%S"),now_str]
- elif unit == "year":
- return [(now - relativedelta(years=count)).strftime("%Y-%m-%d %H:%M:%S"),now_str]
- return ["",""]
-
-
- def compute_now()->str:
- '''
- 计算当前时间
- '''
- return datetime.datetime.now().strftime("%Y-%m-%d %H:%M

第一个函数其实就是计算时间区间,第二个函数当用户问现在几点啦啥的,可以调用这个函数回答用户。
激动时刻来临了:将这些函数作为工具给到大模型
Byzer-LLM 将 Python 作为 LLM 的第一语言,你可以直接把函数传递给大模型,而不需要像 OpenAI 那样,写一堆的 json 描述文件。
具体用法如下:
- t = llm.chat_oai([{
- "content":'''计算当前时间''',
- "role":"user"
- }],tools=[compute_date_range,compute_now],execute_tool=True)
-
-
- t[0].values
-
-
- ## output: ['2023-12-18 17:30:49']
在上面的代码中,我们增加了两个参数:
- 1. tools: 一个函数列表
- 2. execute_tool: 是否直接执行选中的函数,而不是返回函数信息
我们让大模型计算下当前的时间,所以大模型选择了 compute_now 函数,然后因为我们配置了 execute_tool 为 True, 所以他直接运行了 compute_now 函数,你可以通过 t[0].values 拿到 compute_now 的返回值。
惊不惊喜,意不意外,使用竟然这么简单,这么 Python 化。
现在再让我们问两个问题:
- t = llm.chat_oai([{
- "content":'''你吃饭了么?''',
- "role":"user"
- }],tools=[compute_date_range,compute_now],execute_tool=True)
-
-
- if t[0].values:
- print(t[0].values[0])
- else:
- print(t[0].response.output)
-
-
- ## output: '您好,我是一个人工智能语言模型,暂时无法吃饭。'
- 我们问了一个和时间无关的问题,大模型很好的没有调用任何工具,单纯的返回说他没办法吃饭。
接着看看:
- t = llm.chat_oai([{
- "content":'''最近三个月趋势''',
- "role":"user"
- }],tools=[compute_date_range,compute_now],execute_tool=True)
-
-
- t[0].values
-
-
- ## output: [['2023-09-18 17:31:21', '2023-12-18 17:31:21']]
- 很精准。
还有这个:
- t = llm.chat_oai([{
- "content":'''最近几天的趋势''',
- "role":"user"
- }],tools=[compute_date_range,compute_now],execute_tool=True)
-
-
- t[0].values
不按常理出牌啊,竟然说的最近几天,那到底是几天阿呀喂。这个时候可能不同的模型会反应不一样,有的会无法调用函数,有的会自己给一个默认值,比如Qwen 给的默认值是 7。那我们怎么控制这种模糊的问发呢?直接修改我们的函数签名:
我们原先的写法:
- def compute_date_range(count:Annotated[int,"时间跨度,数值类型"],
- unit:Annotated[str,"时间单位,字符串类型",{"enum":["day","week","month","year"]}])->List[str]:
可以看到, count/unit 我们都没给默认值。我们直接给个默认值就行了:
- def compute_date_range(count:Annotated[int,
- "时间跨度,数值类型,如果用户说的是几天,几月啥的,比较模糊,务必使用默认值"]=3,
- unit:Annotated[str,"时间单位,字符串类型",
- {"enum":["day","week","month","year"]}]="day")->List[str]:
这里我们设置为默认值 count 为 3, 当然,光给一个默认值 3 还不够,因为大模型其实没那么聪明,你需要在参数解释里稍微说明下:如果用户说的是几天,几月啥的,比较模糊,务必使用默认值。这样就好了。
再执行,会返回三天的时间区域给你:
[['2023-12-18 13:00:07', '2023-12-21 13:00:07']]这里我们提出一个新概念。
LLM友好函数
下面这段代码就是 LLM 友好函数,因为他包含了几个要素:
函数命名,参数命名规范
对函数有介绍和描述
对参数指定了强类型,有描述,以及有默认值,如果是枚举值还指定了可选枚举值。
- def compute_date_range(count:Annotated[int, "时间跨度,数值类型,如果用户说的是几天,几月啥的,比较模糊,务必使用默认值"]=3,
- unit:Annotated[str,"时间单位,字符串类型",
- {"enum":["day","week","month","year"]}]="day")->List[str]:
- '''
- 计算日期范围
- '''
Respond with Class
这个属于额外复送的一个功能。我们看一眼代码,大家就知道有啥用了,
先定义一个类:
- import pydantic
-
-
- class Story(pydantic.BaseModel):
- '''
- 故事
- '''
-
-
- title: str = pydantic.Field(description="故事的标题")
- body: str = pydantic.Field(description="故事主体")
然后调用大模型:
- t = llm.chat_oai([
- {
- "content":f'''请给我讲个故事,分成两个部分,一个标题,一个故事主体''',
- "role":"user"
- },
- ],response_class=Story)
-
-
- t[0].value
我们额外加了一个参数,response_class=Story, 现在大模型不再返回一段文本,而是一个 Story 对象:
- Story(
- title='勇敢的小兔子',
- body='在一个美丽的森林里,住着一只可爱的小兔子。小兔子非常勇敢,有一天,森林里的动物们都被大灰狼吓坏了。只有小兔子站出来,用智慧和勇气打败了大灰狼,保护了所有的动物。从此,小兔子成为了森林里的英雄。')
酷不酷。
总结
这里我们用 ModelScope + Qwen72B + Byzer-LLM 演示了在开源模型使用OpenAI 类似的 Function Calling 功能,并且提供了额外的 Respond with Class 功能。我们把 Python 作为大模型第一语言,并且提出了 LLM 友好函数的概念。
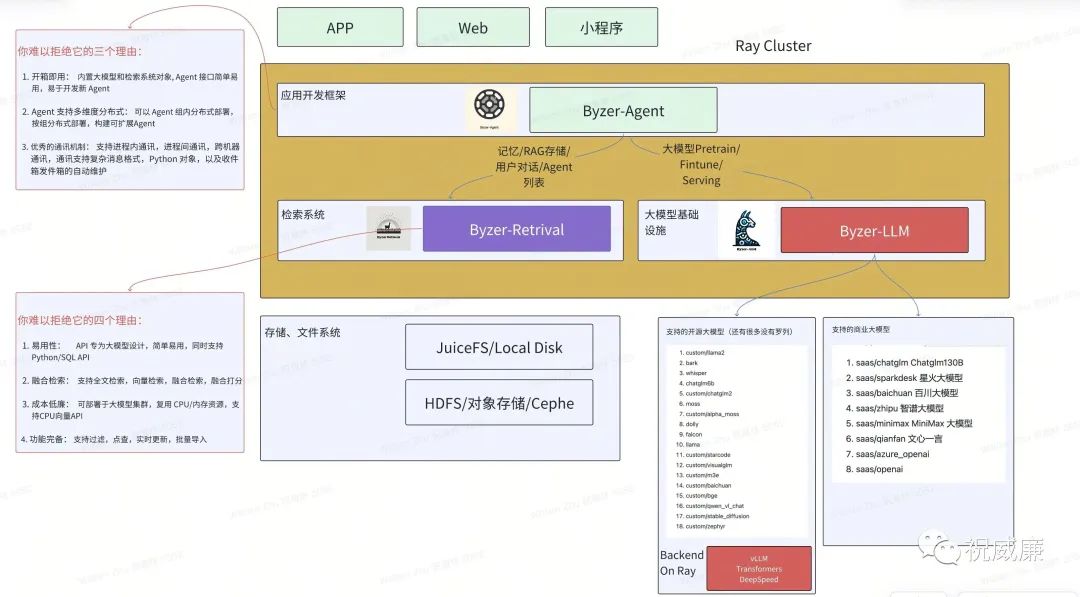
此外,如果用户希望构建基于大模型的业务应用,我们推荐存储采用 [Byzer-Retrieval](https://github.com/allwefantasy/byzer-retrieval), 应用开发框架使用 [Byzer-Agent](https://github.com/allwefantasy/byzer-agent) ,并在允许的情况下,尽量使用更大的模型,从而保证减少工程量。
赠送架构图一份: