
- 1消息中间件RabbitMQ需要知道的6个端口的作用_4369端口是什么服务
- 2从零开始学“纯血鸿蒙”?先别急,看完这篇再决定!_纯血鸿蒙系统
- 3Ubuntu 24.04安装MySQL_ubuntu24.04安装mysql
- 4NGUI系列教程五(角色信息跟随)_uifllowtarget
- 5Mac M1安装编译FFmpeg教程_ffmpeg mac
- 6推荐开源项目:MyOS —— 打造个性化Linux环境的利器
- 7四个不看会后悔,但看了更后悔的故事_不看会后悔,看了更后悔
- 8CDR2024最新免费序列号keygen注册机网盘下载_cdr注册机网盘
- 9Oracle云服务器安全配置_oracle 云服务器 防火墙配置
- 10微信小程序坐标位置接口使用整理(一)_微信小程序 wx.openlocation使用
Keras 3.0强势回归,助力深度学习_keras版本
赞
踩
大家好,Keras的简洁代码风格一直受到开发者的青睐,自从Keras宣布支持Pytorch和Jax后,开发者们迎来了新的选择。
本文将介绍Keras 3.0的实用技巧,以一个典型的编码器-解码器循环神经网络为例,展示如何利用子类化API构建项目,并讲解使用Pytorch作为后端时的注意事项。
1.框架安装和环境配置
1.1 框架安装
安装Keras 3.0非常简单,按照官方网站的入门指南即可(https://keras.io/getting_started/?ref=dataleadsfuture.com)。
在安装Keras之前,建议先安装与CUDA版本相匹配的Pytorch,选择CUDA 11.8或CUDA 12.1都可以,具体取决于显卡驱动程序是否支持。
虽然Pytorch可以作为后端使用,但Keras在安装时默认会安装Tensorflow 2.16.1版本。由于该版本的Tensorflow是基于CUDA 12.3编译的,安装Keras后,可能会收到关于CUDA缺失的警告。
Could not find cuda drivers on your machine, GPU will not be used.
如果使用Pytorch作为后端,可以忽略这个警告。
此外,为了避免Tensorflow日志的干扰,可以通过设置系统环境变量来永久关闭Tensorflow的日志输出。具体做法如下:
- import os
- os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
这样设置后,Tensorflow不再显示不必要的日志信息,为用户提供一个更清晰的开发环境。
1.2 环境配置
安装Pytorch和Keras之后,接下来需要将Keras的后端设置为Pytorch。可以通过两种方式实现:
-
修改配置文件
-
设置环境变量
首先,介绍下使用配置文件的方法。
Keras的配置文件通常位于~/.keras/keras.json中,Windows系统中,位于<user directory>/.keras/keras.json。
如果需要,还可以通过设置KERAS_HOME环境变量来改变.keras目录的位置。
初次安装Keras后,如果找不到.keras目录,可以在IPython或Jupyter Notebook中执行import keras来定位目录。
找到配置文件后,需在keras.json中将"backend"键的值设置为"torch"。
- {
- "floatx": "float32",
- "epsilon": 1e-07,
- "backend": "torch",
- "image_data_format": "channels_last"
- }
对于生产环境或使用Colab等云环境的情况,可能无法直接修改配置文件。在这种情况下,可以通过设置环境变量来解决这个问题:
os.environ["KERAS_BACKEND"] = "torch"
Keras 后端配置完成后,可以通过以下代码进行确认:
- In: import keras
- keras.config.backend()
-
- Out: 'torch'
准备工作完成后,接下来正式开始项目实践。
2.项目实战:端到端示例
使用子类化API实现一个神经机器翻译(NMT)模型,并解释使用Keras 3.0的一些细节。
2.1 理论介绍
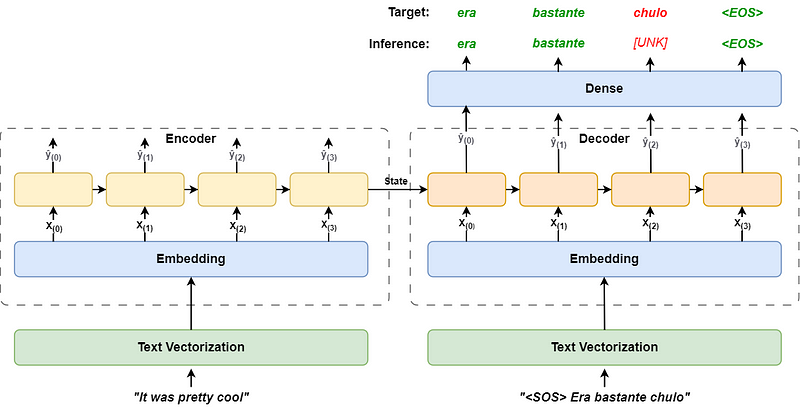
自然语言处理(NLP)领域中,神经机器翻译(NMT)模型是一种重要的技术。NMT通常采用编码器-解码器架构,该架构基于循环神经网络(RNN),本例中特指长短期记忆网络(LSTM)。
在这种架构下,编码器由一个嵌入层和一个RNN层组成,负责将原始文本转换为向量形式。处理后的编码器最终状态随后传递给解码器。
与此同时,目标文本也经过嵌入层,但在送入解码器前,会向前偏移一个步骤,以序列开始(SOS)占位符作为起始。
解码器结合编码器的状态和目标文本,通过递归计算生成输出,最终通过一个全连接层(Dense)进行激活,计算每个文本向量的概率,并与目标文本的词向量进行比较,以计算损失。为了明确标记文本的结束,这里在目标文本末尾添加序列结束(EOS)占位符。
整个架构如下图所示:
由于 Transformer 架构很受欢迎,Keras 的 KerasNLP 软件包(https://keras.io/keras_nlp/?ref=dataleadsfuture.com)也提供了各种预训练模型,如 Bert 和 GPT,用于完成 NLP 任务。
不过,本文的重点是了解如何使用 Keras 3.0,因此使用基本的 RNN 网络就足够了。
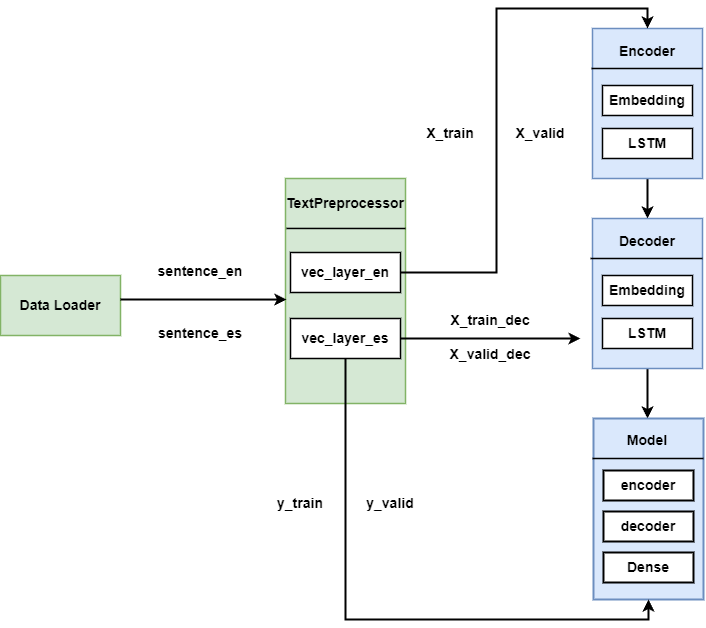
2.2 模块和流程图
本项目是一个生产级别的应用,采用了Keras 3.0的子类化API来构建各个模块。为了帮助理解各个模块及其相互之间的工作流程,专门制作了一个流程图。
流程图详细展示了项目的模块结构和它们之间的交互方式。通过这个流程图,可以清晰地看到整个项目的运作流程。接下来,会依据流程图的设计来编写代码。
2.3 导入包
在Jupyter Notebook中进行项目开发时,建议在项目初期就导入所有必要的库。这样做的好处是,如果中途发现缺少某些库,只需在一个地方进行补充,而无需在代码中四处搜寻并添加导入语句。
以下是个典型的导入模块的代码块:
- from pathlib import Path
- import pickle
-
- import keras
- from keras import layers, utils
- import numpy as np
-
- # 设置随机种子以确保结果的可复现性
- utils.set_random_seed(42)
这里有一个实用的小技巧:utils.set_random_seed 函数可以在一行代码中设置Python、Numpy以及Pytorch的随机种子,这在确保实验结果的一致性方面非常有用。
2.4 数据准备
在项目启动之初,选择恰当的数据很重要。与以往的编码器-解码器模型相同,本项目选用了西班牙语-英语(spa-eng)的文本数据集。
该数据集由Tatoeba项目的贡献者提供,涵盖了120,000对句子,遵循Creative Commons Attribution 2.0 France许可,可通过特定链接下载(https://www.manythings.org/anki/?ref=dataleadsfuture.com)。
下载数据集后,首先需检查spa.txt文件的内容。
- The rain lasted three days. La lluvia duró tres días. CC-BY 2.0 (France) Attribution: tatoeba.org #27004 (CK) & #431740 (Leono)
- The refrigerator is closed. El frigorífico está cerrado. CC-BY 2.0 (France) Attribution: tatoeba.org #5152850 (CarpeLanam) & #10211587 (manufrutos)
- The reports were confusing. Los informes eran confusos. CC-BY 2.0 (France) Attribution: tatoeba.org #2268485 (_undertoad) & #2268486 (cueyayotl)
- The resemblance is uncanny. La similitud es extraña. CC-BY 2.0 (France) Attribution: tatoeba.org #2691302 (CM) & #5941808 (albrusgher)
- The resemblance is uncanny. El parecido es asombroso. CC-BY 2.0 (France) Attribution: tatoeba.org #2691302 (CM) & #6026125 (albrusgher)
- The results seem promising. Los resultados se antojan prometedores. CC-BY 2.0 (France) Attribution: tatoeba.org #8480484 (shekitten) & #8464272 (arh)
- The rich have many friends. Los ricos tienen muchos amigos. CC-BY 2.0 (France) Attribution: tatoeba.org #1579047 (sam_m) & #1457378 (marcelostockle)
该文件包含至少三列,第一列是源语言文本,第二列是目标语言文本,中间通过制表符分隔。
由于文件规模适中,可以直接采用numpy的genfromtxt函数来读取数据集。代码如下:
- text_file = Path("./temp/eng-spanish/spa-eng/spa.txt")
-
- pairs = np.genfromtxt(text_file, delimiter="\t", dtype=str,
- usecols=(0, 1), encoding="utf-8",
- autostrip=True,
- converters={1: lambda x: x.replace("¡", "").replace("¿", "")})
- np.random.shuffle(pairs)
- sentence_en, sentence_es = pairs[:, 0], pairs[:, 1]
处理后,可以通过以下方式验证结果:
- In: print(f"{sentence_en[0]} => {sentence_es[0]}")
-
- Out: I'm really sorry. => Realmente lo siento.
确认无误后,即可开始后续的项目实践。
2.5 数据预处理
在进行文本内容的预处理和向量化之前,需要先设定一些基本参数,并定义一个专门的类来管理这些配置:
- class Configure:
- VOCAB_SIZE: int = 1000
- MAX_LENGTH: int = 50
- SOS: str = 'startofseq'
- EOS: str = 'endofseq'
接下来,进入数据处理的核心环节。
尽管选择使用Pytorch作为后端,但在Keras 3.0中TextVectorization层实际上是基于TensorFlow的实现。这意味着不能直接将TextVectorization作为Keras模型的一部分,而需要在预处理阶段单独使用。
这引出了一个问题,在将训练好的模型部署到生产环境时,如果没有TextVectorization的词汇表,就无法进行文本向量化。因此,必须确保词汇表的持久化,以便在推理任务中重复使用。
使用TextPreprocessor模块来执行向量化。以下是具体代码:
- class TextPreprocessor:
- def __init__(self,
- en_config = None, es_config = None):
- if en_config is None:
- self.text_vec_layer_en = layers.TextVectorization(
- Configure.VOCAB_SIZE, output_sequence_length=Configure.MAX_LENGTH
- )
- else:
- self.text_vec_layer_en = layers.TextVectorization.from_config(en_config)
-
- if es_config is None:
- self.text_vec_layer_es = layers.TextVectorization(
- Configure.VOCAB_SIZE, output_sequence_length=Configure.MAX_LENGTH
- )
- else:
- self.text_vec_layer_es= layers.TextVectorization.from_config(es_config)
-
- self.adapted = False
- self.sos = Configure.SOS
- self.eos = Configure.EOS
-
- def adapt(self, en_sentences: list[str], es_sentences: list[str]) -> None:
- self.text_vec_layer_en.adapt(en_sentences)
- self.text_vec_layer_es.adapt([f"{self.sos} {s} {self.eos}" for s in es_sentences])
- self.adapted = True
-
- def en_vocabulary(self):
- return self.text_vec_layer_en.get_vocabulary()
-
- def es_vocabulary(self):
- return self.text_vec_layer_es.get_vocabulary()
-
- def vectorize_en(self, en_sentences: list[str]):
- return self.text_vec_layer_en(en_sentences)
-
- def vectorize_es(self, es_sentences: list[str]):
- return self.text_vec_layer_es(es_sentences)
-
- @classmethod
- def from_config(cls, config):
- return cls(**config)
-
- def get_config(self):
- en_config = self.text_vec_layer_en.get_config()
- en_config['vocabulary'] = self.en_vocabulary()
- es_config = self.text_vec_layer_es.get_config()
- es_config['vocabulary'] = self.es_vocabulary()
- return {'en_config': en_config,
- 'es_config': es_config}
-
- def save(self, filepath: str):
- if not self.adapted:
- raise RuntimeError("Layer hasn't been adapted yet.")
- if filepath is None:
- raise ValueError("A file path needs to be defined.")
- if not filepath.endswith('.pkl'):
- raise ValueError("The file path needs to end in .pkl.")
- pickle.dump({
- 'config': self.get_config()
- }, open(filepath, 'wb'))
-
- @classmethod
- def load(cls, filepath: str):
- conf = pickle.load(open(filepath, 'rb'))
- instance = cls(**conf['config'])
- return instance

解释一下这个模块的作用:
-
这个模块的作用是将原始文本和目标文本转换为向量形式。它包含两个
TextVectorization层,分别用于处理英文和西班牙语文本。 -
通过适配过程,模块会保存两种语言的词汇表,这样在部署到生产系统时,就无需再次进行适配。
-
该模块使用pickle模块来实现持久化。通过
get_config方法,可以获取TextVectorization层的配置并保存。同样,也可以通过from_config方法,从保存的配置中直接初始化模块实例。 -
然而,在使用
get_config方法时,词汇表并没有被正确检索出来(这可能是Keras 3.3的一个bug)。因此,转而使用get_vocabulary方法来单独获取词汇表。
以下是如何适配文本并保存词汇表的示例:
- text_preprocessor = TextPreprocessor()
- text_preprocessor.adapt(sentence_en, sentence_es)
- text_preprocessor.save('./data/text_preprocessor.pkl')
检查两种语言的词汇表:
- In: text_preprocessor.en_vocabulary()[:10]
- Out: ['', '[UNK]', 'i', 'the', 'to', 'you', 'tom', 'a', 'is', 'he']
-
- In: text_preprocessor.es_vocabulary()[:10]
- Out: ['', '[UNK]', 'startofseq', 'endofseq', 'de', 'que', 'no', 'tom', 'a', 'la']
TextPreprocessor模块配置完成后,就可以开始数据集的划分和文本的向量化处理。考虑到目标文本同样需要作为解码器模块的输入,这里特别准备了两组额外的数据集:X_train_dec和X_valid_dec。这两组数据集将专门用于训练和验证解码器的性能。
- X_train = text_preprocessor.vectorize_en(sentence_en[:100_000])
- X_valid = text_preprocessor.vectorize_en(sentence_en[100_000:])
-
- X_train_dec = text_preprocessor.vectorize_es([f"{Configure.SOS} {s}" for s in sentence_es[:100_000]])
- X_valid_dec = text_preprocessor.vectorize_es([f"{Configure.SOS} {s}" for s in sentence_es[100_000:]])
-
- y_train = text_preprocessor.vectorize_es([f"{s} {Configure.EOS}" for s in sentence_es[:100_000]])
- y_valid = text_preprocessor.vectorize_es([f"{s} {Configure.EOS}" for s in sentence_es[100_000:]])
2.6 实现编码器-解码器模型
如之前架构图所示,整个模型被划分为编码器和解码器两部分,因此为每个部分各自创建了基于keras.layers.Layer的自定义子类。
每个自定义层都需要实现三个核心方法:__init__、call和get_config。
-
__init__方法用于初始化层的成员变量、权重和子层。 -
call方法接受输入参数,并返回处理后的输出,其工作机制与Keras的功能API相似。 -
get_config方法则用于在模型保存时获取层的配置信息。
编码器层的实现如下:
- @keras.saving.register_keras_serializable()
- class Encoder(keras.layers.Layer):
- def __init__(self, embed_size: int = 128, **kwargs):
- super().__init__(**kwargs)
- self.embed_size = embed_size
-
- self.encoder_embedding_layer = layers.Embedding(input_dim=Configure.VOCAB_SIZE,
- output_dim=self.embed_size,
- mask_zero=True)
- self.encoder = layers.LSTM(512, return_state=True)
-
- def call(self, inputs):
- encoder_embeddings = self.encoder_embedding_layer(inputs)
- encoder_outputs, *encoder_state = self.encoder(encoder_embeddings)
- return encoder_outputs, encoder_state
-
- def get_config(self):
- config = {"embed_size": self.embed_size}
- base_config = super().get_config()
- return config | base_config
在编码器中,特别将LSTM层的return_state参数设置为True,这样做是为了能够将LSTM的最终状态传递给解码器层使用。
解码器层的实现:
- @keras.saving.register_keras_serializable()
- class Decoder(keras.layers.Layer):
- def __init__(self, embed_size: int = 128, **kwargs):
- super().__init__(**kwargs)
- self.embed_size = embed_size
-
- self.decoder_embedding_layer = layers.Embedding(input_dim=Configure.VOCAB_SIZE,
- output_dim=self.embed_size,
- mask_zero=True)
- self.decoder = layers.LSTM(512, return_sequences=True)
-
- def call(self, inputs, initial_state=None):
- decoder_embeddings = self.decoder_embedding_layer(inputs)
- decoder_outputs = self.decoder(decoder_embeddings,
- initial_state=initial_state)
- return decoder_outputs
-
- def get_config(self):
- config = {"embed_size": self.embed_size}
- base_config = super().get_config()
- return config | base_config
解码器层的call方法不仅接收数据输入,还通过initial_state参数接收来自编码器的状态,并据此产生输出。
此外,还实现了一个自定义模型,同样需要实现__init__、call和get_config方法,与keras.layers.Layer.Model类似。:
- @keras.saving.register_keras_serializable()
- class NMTModel(keras.models.Model):
- embed_size: int = 128
-
- def __init__(self, **kwargs):
- super().__init__(**kwargs)
-
- self.encoder = Encoder(self.embed_size)
- self.decoder = Decoder(self.embed_size)
-
- self.out = layers.Dense(Configure.VOCAB_SIZE, activation='softmax')
-
- def call(self, inputs):
- encoder_inputs, decoder_inputs = inputs
-
- encoder_outputs, encoder_state = self.encoder(encoder_inputs)
- decoder_outputs = self.decoder(decoder_inputs, initial_state=encoder_state)
- out_proba = self.out(decoder_outputs)
- return out_proba
-
- def get_config(self):
- base_config = super().get_config()
- return base_config
-
在模型中,初始化了一个
Dense层,将解码器的输出转换为单词向量的结果。 -
call方法接收两个输入,可以通过解包轻松区分。 -
为了确保模型能够被正确序列化和保存,编码器、解码器和模型都需要使用
@keras.saving.register_keras_serializable()装饰器。
2.7 模型训练
定义好模型后,进入训练阶段,以下是训练过程的详细步骤:
- nmt_model = NMTModel()
- nmt_model.compile(loss='sparse_categorical_crossentropy',
- optimizer='nadam',
- metrics=['accuracy'])
- checkpoint = keras.callbacks.ModelCheckpoint(
- './data/nmt_model.keras',
- monitor='val_accuracy',
- save_best_only=True
- )
- nmt_model.fit((X_train, X_train_dec), y_train, epochs=1,
- validation_data=((X_valid, X_valid_dec), y_valid),
- batch_size=128,
- callbacks=[checkpoint])
在这部分代码中:
-
首先通过compile方法对模型实例进行编译,配置
loss,optimizer和metrics。 -
接着,定义一个
ModelCheckpoint回调,该回调在训练过程中监测验证集的准确率,并在发现最佳模型时自动保存。 -
使用
fit方法,将X_train和X_train_dec作为元组传递给x参数,并以类似方式处理validation_data。 -
示例中将
epochs设置为1,这仅为演示目的。在实际应用中,应根据模型训练效果灵活调整epochs和batch_size的数值。 -
Keras 3.0版本支持Pytorch的
DataLoader,也可以通过keras.utils.PyDataset构建一个不依赖于后端的预处理流程。
训练完成后保存模型,以便后续部署。
2.8 推理任务
完成模型训练后,接下来是部署阶段。此时,应将相关的代码模块、保存的词汇表以及训练好的模型一并部署到生产系统中,以便执行推理任务。
模型的Dense层负责输出词汇表中每个单词向量对应的概率。为了生成翻译文本,需要将已翻译的单词与预测出的单词结合,并将其连同原始文本再次输入模型,以预测出下一个单词。这一过程可以通过以下代码实现:
- preprocessor = TextPreprocessor.load('./data/text_preprocessor.pkl')
- nmt_model = keras.saving.load_model('./data/nmt_model.keras')
-
- def translate(sentence_en):
- translation = ""
- for word_index in range(50):
- X = preprocessor.vectorize_en([sentence_en])
- X_dec = preprocessor.vectorize_es([Configure.SOS + " " + translation])
- y_proba = nmt_model.predict((X, X_dec), verbose=0)[0, word_index]
- predicted_word_id = np.argmax(y_proba)
- predicted_word = preprocessor.es_vocabulary()[predicted_word_id]
- if predicted_word == Configure.EOS:
- break
- translation = translation + " " + predicted_word
- return translation.strip()
通过简单的测试函数,可以验证翻译结果:
- In: translate("It was pretty cool.")
- Out: 'era bastante [UNK]'
虽然结果不是很准确,但本文的目标是学习如何使用Keras 3.0的子类化API,因此,对于模型的优化和改进,仍然存在广阔的空间。
3.总结
Keras 3.0的推出为开发者带来了便利,使大家能够利用Keras简洁的API高效构建模型,同时可以选择 Pytorch 或 Jax 作为后端支持。为了帮助开发者快速掌握Keras 3.0,本文通过一个完整的实践案例,详细介绍了环境搭建和基础开发步骤。
Keras 3.0仍处于发展初期,尚未能完全独立于TensorFlow,也存在一些TensorFlow的遗留问题。随着多后端支持的不断完善,Keras有望迎来新的发展机遇,进一步推动深度学习技术的普及,并降低初学者的学习门槛。

