
- 1LNMP动态网站环境部署
- 2一款开源、简洁、支持全平台的高速下载神器
- 3git 新建分支并切换到该分支_Git 命令 - 分支与合并命令
- 4git整合分支的两种方法——合并(Merge)、变基(Rebase)_git变基和合并用哪个
- 5Vue3DraggableResizable知识点_vue-draggable-resizable
- 6【测试资源】测试新手可放心冲的几个学习网站,团队分享学习清单_学习接口测试可用的网站有哪些
- 7【ARM版银河麒麟安装windows应用程序】_银河麒麟安装wine
- 8固定资产管理系统建设方案_固定资产系统方案
- 9深入解析香橙派 AIpro开发板:功能、性能与应用场景全面测评_香橙派可以用来干嘛
- 10java算法:插入排序_快速排序算法
论文笔记-深度估计(1)Depth Map Prediction from a Single Image using a Multi-Scale Deep Network_scale-invariant error
赞
踩
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
作者认为以前估计深度的方法大概是基于几何代数、优化求解的方法来获得空间信息,但对于单张图片,仅仅基于几何信息是无法判断它的真实尺度的,因为没有先验信息的话,它的尺度是无法进行估计的。单张图深度估计,以人为例,需要综合考虑线条角度,透视关系,物体大小,图像位置以及环境效果等因素。因此融合其他信息的深度网络有望获得更好的单张图深度预测。
网络
为此作者提出一个有监督的包含两个网络的coarse to fine深度学习网络来进行深度估计:coarse网络估计整张图的全局预测,而另外一个网络来对局部信息进行refine:
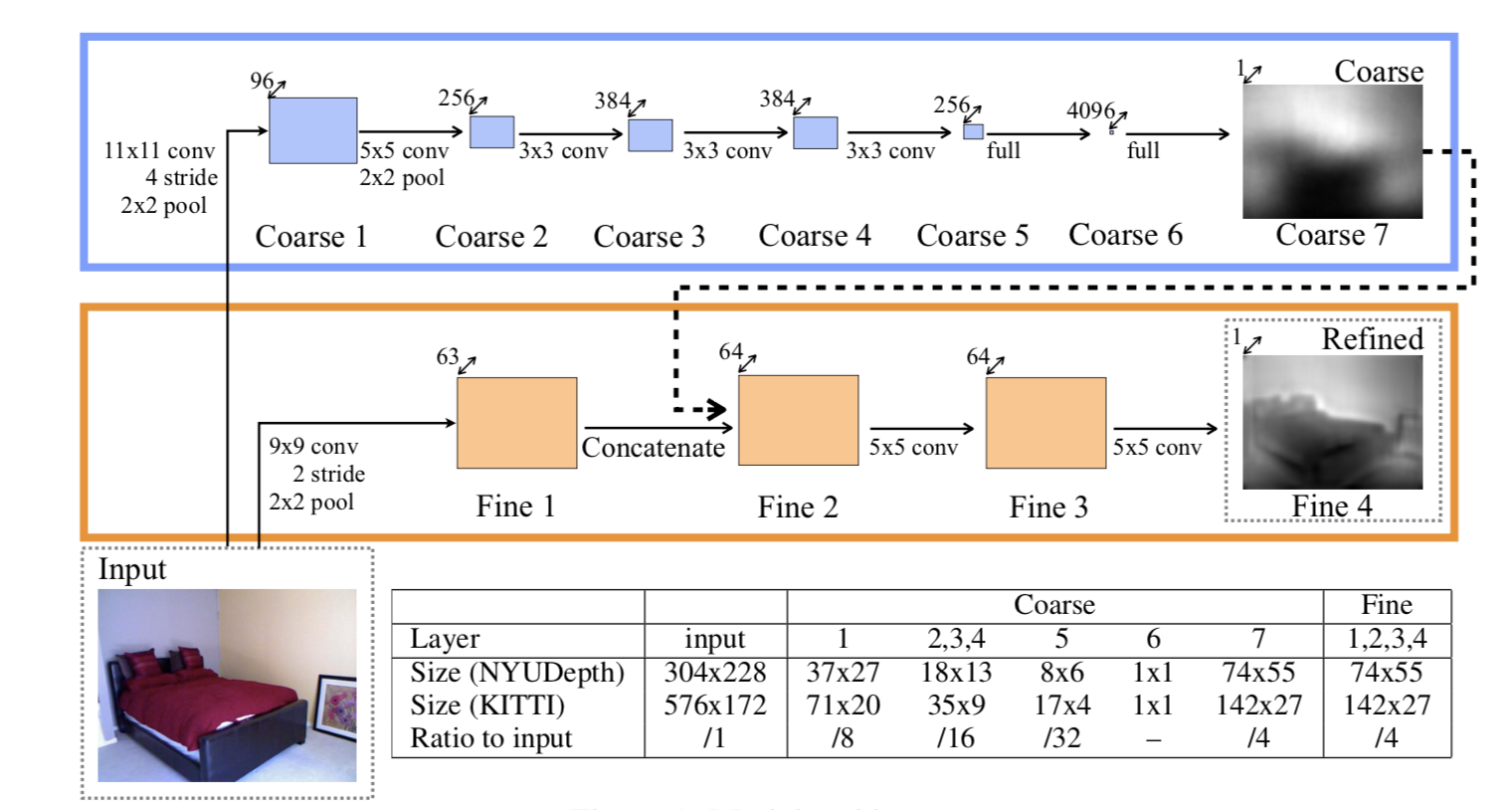
第一个coarse-scale网络和VGG等分类网络是一致的,卷积层+全连接层,得到的输出作为网络而的输入。它最终的输出大小只有输入的1/4大小。RELU,Dropout,不能缺 ;在ImageNet上pretrain好的model,减少工作量。
第二个fine-scale网络用来做精细化调整,比如目标物体的轮廓。这个网络仅仅包含卷积层,这让人想起了同年后面出来的FCR文章(参看博文列表)。
该网络将原来的图片进行卷积操作得到原图的1/4大小,并和第一个网络的输出接在一起(可能就是直接作为向量接在一起)。
训练时先训练好第一个网络,再将输出作为第二层网络来训练第二层网络。也就是:整个后向传播过程只在各自网络进行。
由于没有用到现在大家通用的deconvolution,最终输入大小为为原图1/2的fine网络的输出大小为原图的1/4,这是本文网络的最终输出。
价值函数
与一般作者会用预测值与真实值的绝对误差(欧式距离)不同,作者提出一个类似余弦误差的概念——尺度不变误差(Scale-Invariant Error):

