
- 1华为的热机备份和流量限制
- 2前端7大常用布局方式_前端布局
- 3超简单,手把手教你在本地运行Llama 3大模型_ollama run llama3
- 4直播系统源码性能调优方案最全最详细
- 5【项目开发记录】微信小程序_colorui底部导航栏
- 6基于Hadoop2.7.2+ ICTCLAS2015的并行化中文分词
- 7HarmonyOS Next开发学习手册——UI开发 (兼容JS的类Web开发范式)
- 8信创基础软件之信创云介绍_信创软件
- 9英伟达A100、A800、H100、H800、V100以及RTX 4090的详细性能参数对比_a100 a800 h100 h800
- 10基于复旦微的 FMQL45T900 ARM+FPGA+AD全国产化解决方案,兼容XILINX的XC7Z045-2FFG900I (即ZYNQ7045)
chatGPT 背后的技术 之 GPT3_chatgpt3
赞
踩
chatGPT是由openAI 公司发布的大型语言对话机器学习模型,因为其强大的功能,可以帮助编程,可以咨询问题,可以检查语法错误等等,而在最近半年火爆全网。
chatGPT 背后的技术是 GPT3.5,其本质是 大型预训练语言模型。
GPT3.5 是 在 GPT3 的 基础上进行了微调(fine-tuning),具体进行了什么微调我们在后面的文章中会介绍,今天我们先介绍GPT3.
GPT3 的详细介绍在 Language Models are Few-Shot Learners 这篇 论文中,https://arxiv.org/abs/2005.14165 点击网页链接中的Download 下的 PDF 就可以下载论文原文。
论文中的重点如下:
GPT3 的网络结构和 GPT2 是一样的(GPT2 会在后面的文章中详细介绍),但GPT3 的模型尺寸比GPT2大 两个数量级。
和GPT2的主要不同是,GPT3 使用了 Sparse Transformer。
训练的数据集进行了一些处理,增加了一些可信度高的文本的学习次数。
GPT3 可以处理多种文本相关的任务,如填词,回答问题,阅读理解等,不再需要对特性任务进行分别训练,可以认为是在通用人工智能的道路上迈出了举足轻重的一步。
GPT3 有 1750 亿个参数。
GPT3 没有进行微调(fine-tuning),就可以在很多任务中表现出很好的效果。针对任务进行微调,影响了模型的通用性,也和大模型在预训练中尽可能的吸收知识的初衷不符。这样做的原因还有就是人在学习处理大部分新的文字类任务时,并不需要接受这类任务的大量数据进行专门的训练便可完成。
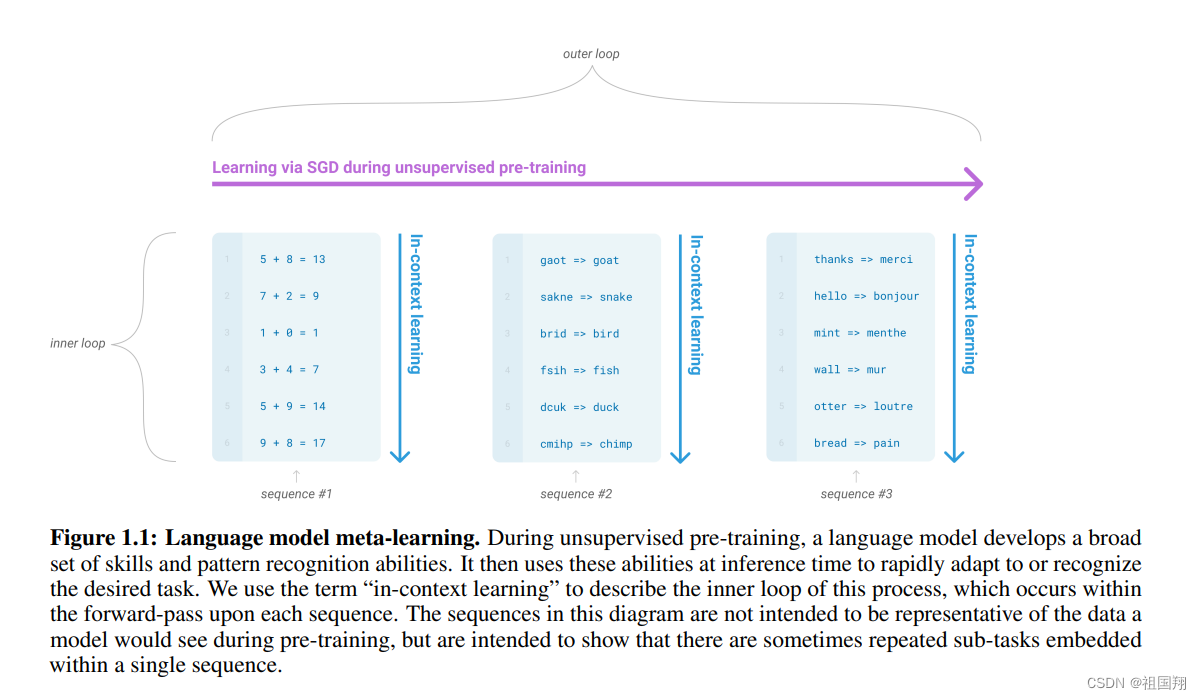
大型预训练模型学习了大量技能和模式识别的能力,这些能力会在推理时识别出要完成的任务是什么。也就是说,对任务的理解是其能力的一部分。
下图展示了预训练模型是怎样能学到背景知识的。
下图展示了,无实例,单个示例,多个示例 和 训练微调(fine-tuning)的区别,GPT3 没有进行微调。

下图展示了训练所用的数据,Common Crawl 是一个抓取网络内容的存储库,数据量很大,只用了其中的44%Common Crawl https://commoncrawl.org/
https://commoncrawl.org/

图片来源:论文 Language Models are Few-Shot Learners
祖国翔,
于上海

