
- 1Promise面试题汇总
- 2【模块化与包管理】:解锁【Python】编程的高效之道
- 3保姆级手把手图文并茂教你配置MAC系统Flutter环境_mac配置flutter环境变量
- 402-用户画像-技术架构+业务划分
- 5Navicat数据库软件免费了!推出Navicat Premium Lite
- 6Flink 之时间语义与Wartermark_flink1.15设置时间语义
- 7java文件上传判重姿势浅谈_com.twmacinta.util.md5
- 8大模型+小模型协同处理跨文档理解任务,成本更低,性能更高_大小模型协同
- 9FreeCAD傻瓜式教程之入门初级使用方法-移动图形、坐标系、视角切换、工作台介绍、Blender导航模式、约束,导出dxf格式
- 10vue3 嵌入unity 3D模型入门教程_unity3d vue
10分钟构建本地知识库,让 ChatGPT 更加懂你_chatgpt 知识库
赞
踩
本文将从零开始构建本地知识库,从而辅助 ChatGPT 基于知识库内容生成回答。
对向量检索相关内容可以查看之前的文章:
这里再重复下部分核心观点:
-
向量:将人类的语言(文字、图片、视频等)转换为计算机可识别的语言(数组)。
-
向量相似度:计算两个向量之间的相似度,表示两种语言的相似程度。
-
语言大模型的特性:上下文理解、总结和推理。
这三个概念结合起来,就构成了 “向量搜索 + 大模型 = 知识库问答” 的公式。
一、FastGPT 部署
1.介绍
FastGPT 是目前 Prompt 串接做的最好的项目,知识库核心流程图如下:
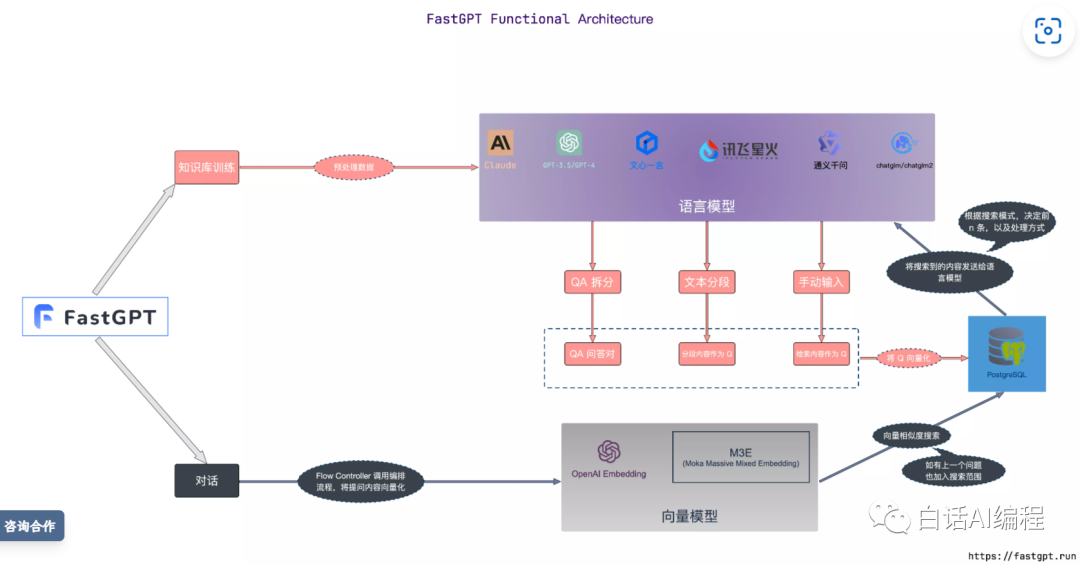
从官方简介也可以看出很牛逼:
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
FastGPT 官网地址:https://doc.fastgpt.in/docs/intro/
FastGPT 在线体验:https://fastgpt.run
2. 安装 Docker
话不多说直接开干,首选需要我们安装 Docker 应用,这里以 Windows 安装为例(其他系统可自行百度解决)。
Docker 官网 :https://www.docker.com/get-started/
进入官网双击下载的 Docker for Windows Installer 安装文件,一路 Next,点击 Finish 完成安装。
安装完成后,Docker 会自动启动。通知栏上会出现个小鲸鱼的图标,这表示 Docker 正在运行。
我装的 docker-desktop 自带了 docker-compose,如果未安装可以去官网进行下载。
Docker-Compose 官网:https://docs.docker.com/desktop/install/windows-install/
安装 Docker 还是比较简单,如果遇到大家可直接百度解决,网上这类文章很多。
3. 配置文件
先创建一个文件夹
# 创建文件夹 mkdir fastgpt # 进入文件夹 cd fastgpt
- 1
创建 config.json,内容如下:
{ "FeConfig": { "show_emptyChat": false, "show_contact": false, "show_git": false, "show_doc": true, "systemTitle": "个人知识库", "limit": { "exportLimitMinutes": 0 }, "scripts": [] }, "SystemParams": { "vectorMaxProcess": 15, "qaMaxProcess": 15, "pgIvfflatProbe": 20 }, "ChatModels": [ { "model": "gpt-3.5-turbo", "name": "GPT35-4k", "contextMaxToken": 4000, "quoteMaxToken": 2000, "maxTemperature": 1.2, "price": 0, "defaultSystem": "" }, { "model": "gpt-3.5-turbo-16k", "name": "GPT35-16k", "contextMaxToken": 16000, "quoteMaxToken": 8000, "maxTemperature": 1.2, "price": 0, "defaultSystem": "" }, { "model": "gpt-4", "name": "GPT4-8k", "contextMaxToken": 8000, "quoteMaxToken": 4000, "maxTemperature": 1.2, "price": 0, "defaultSystem": "" } ], "VectorModels": [ { "model": "text-embedding-ada-002", "name": "Embedding-2", "price": 0, "defaultToken": 500, "maxToken": 3000 } ], "QAModel": { "model": "gpt-3.5-turbo-16k", "name": "GPT35-16k", "maxToken": 16000, "price": 0 }, "ExtractModel": { "model": "gpt-3.5-turbo-16k", "functionCall": true, "name": "GPT35-16k", "maxToken": 16000, "price": 0, "prompt": "" }, "CQModel": { "model": "gpt-3.5-turbo-16k", "functionCall": true, "name": "GPT35-16k", "maxToken": 16000, "price": 0, "prompt": "" }, "QGModel": { "model": "gpt-3.5-turbo", "name": "GPT35-4k", "maxToken": 4000, "price": 0, "prompt": "", "functionCall": false } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
再创建 docker-compose.yml 文件,内容如下:
# 非 host 版本, 不使用本机代理 version: '3.3' services: pg: # 使用阿里云的 pgvector 镜像 image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.4.2 container_name: pg restart: always # 生产环境建议不要暴露端口 ports: - "5432:5432" networks: - fastgpt # 环境变量配置,首次运行生效,修改后需删除持久化数据再重启 environment: - POSTGRES_USER=username - POSTGRES_PASSWORD=password - POSTGRES_DB=fastgpt # 卷挂载,包括初始化脚本和数据持久化 volumes: - ./pg/init.sql:/docker-entrypoint-initdb.d/init.sh - ./pg/data:/var/lib/postgresql/data mongo: # 使用阿里云的 mongo 镜像 image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 container_name: mongo restart: always # 生产环境建议不要暴露端口 ports: - "27017:27017" networks: - fastgpt # 环境变量配置,首次运行生效,修改后需删除持久化数据再重启 environment: - MONGO_INITDB_ROOT_USERNAME=username - MONGO_INITDB_ROOT_PASSWORD=password # 卷挂载,包括数据和日志 volumes: - ./mongo/data:/data/db - ./mongo/logs:/var/log/mongodb fastgpt: container_name: fastgpt # 使用阿里云的 fastgpt 镜像 image: registry.cn-hangzhou.aliyuncs.com/david_wang/fastgpt:latest ports: - "3000:3000" networks: - fastgpt # 确保在 mongo 和 pg 服务启动后再启动 fastgpt depends_on: - mongo - pg restart: always # 可配置的环境变量 environment: - DEFAULT_ROOT_PSW=123456 - OPENAI_BASE_URL=https://api.openai.com/v1 - CHAT_API_KEY=sk-***** - DB_MAX_LINK=5 - TOKEN_KEY=wenwenai - ROOT_KEY=wenwenai - FILE_TOKEN_KEY=filetoken - MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin - PG_URL=postgresql://username:password@pg:5432/fastgpt # 配置文件的卷挂载 volumes: - ./config.json:/app/data/config.json # 定义使用的网络 networks: fastgpt:
- 1
注意修改 docker-compose.yml 中的 CHAT_API_KEY 为你的 OpenAI Key 即可。
4. 启动
执行命令启动本地知识库:
# 在 docker-compose.yml 同级目录下执行 docker-compose pull docker-compose up -d
- 1
执行完成后就可以在浏览器上通过 http://localhost:3000/ 网址来访问个人知识库了。
二、构建知识库
基于上述操作我们已经成功访问到个人知识库页面,接下来带大家创建导入个人数据进行访问。
登录用户名为 root,密码为 docker-compose.yml 环境变量里设置的 DEFAULT_ROOT_PSW。
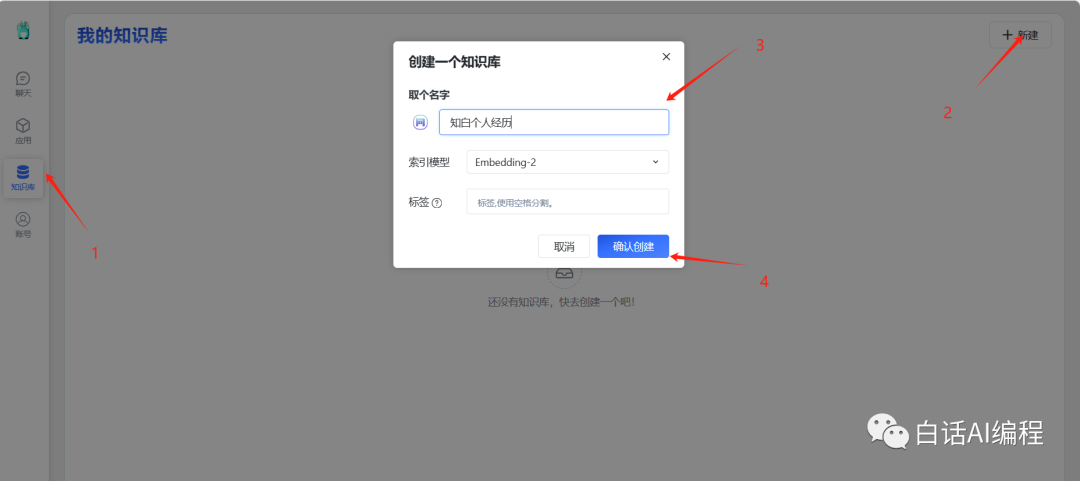
1. 创建知识库
成功登录后,新建一个知识库,这里将我的个人经历导入,所以取名为知白个人经历。
通过文件将个人经历导入到知识库中。
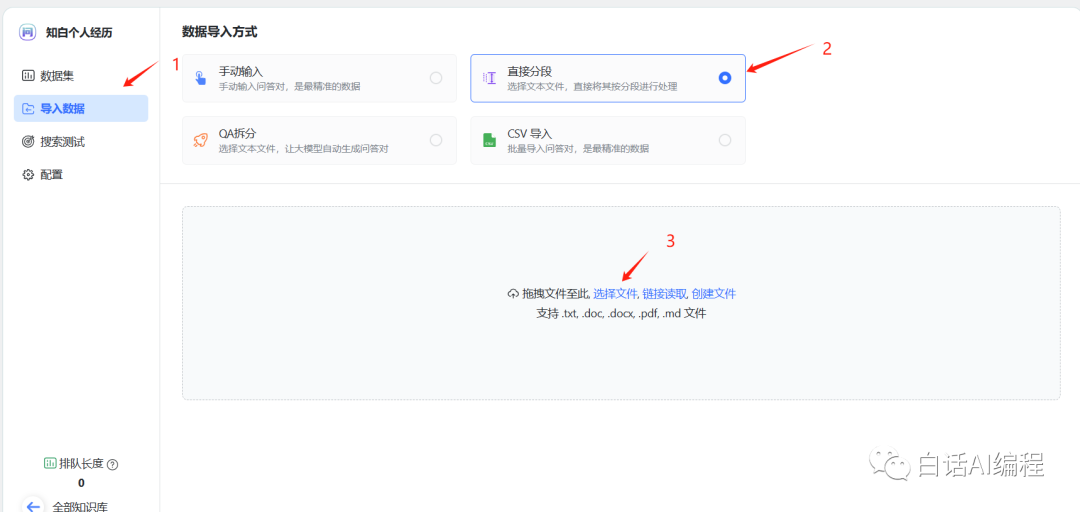
确认后就开始将当前数据转化为向量数据。
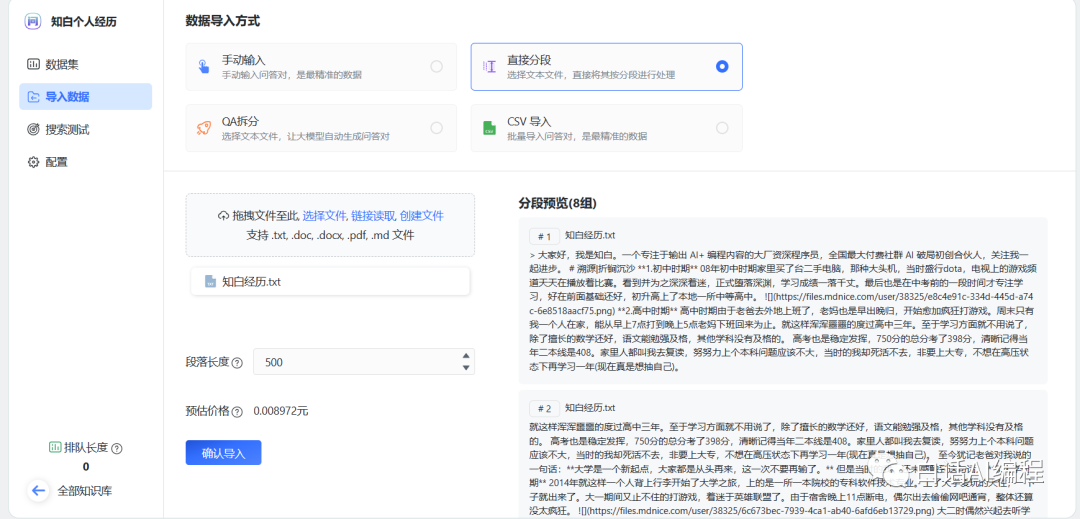
全文大约2300多字,大概3~5分钟就导入完成了。由于文本限制问题,按照固定字数拆分为了8个数据集。

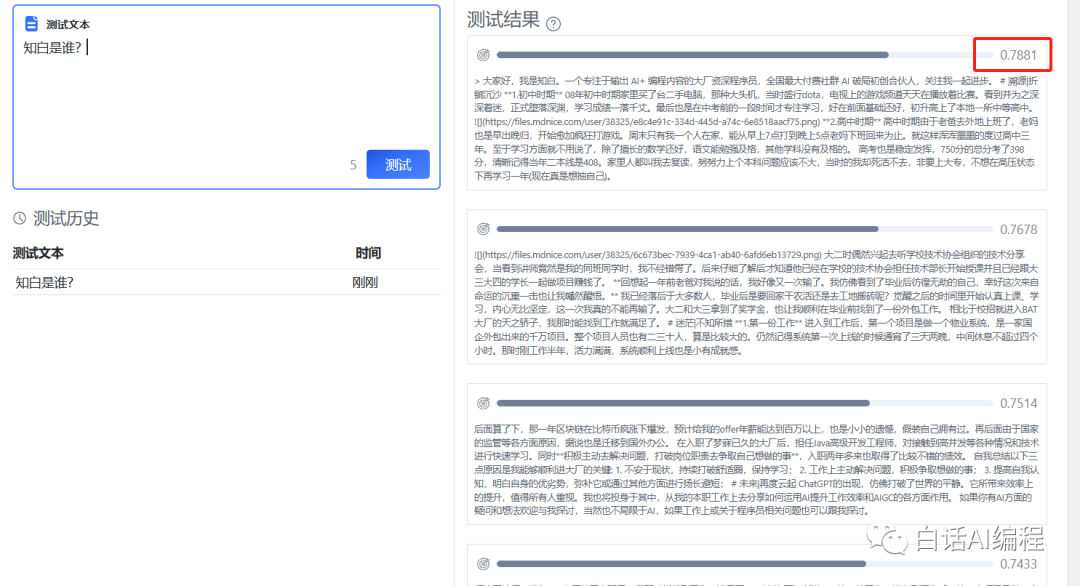
至此,我们的个人知识库已经建好了。我们尝试进行问答,这里的 0.7881 就是向量相似度,相似度越高的越靠前。
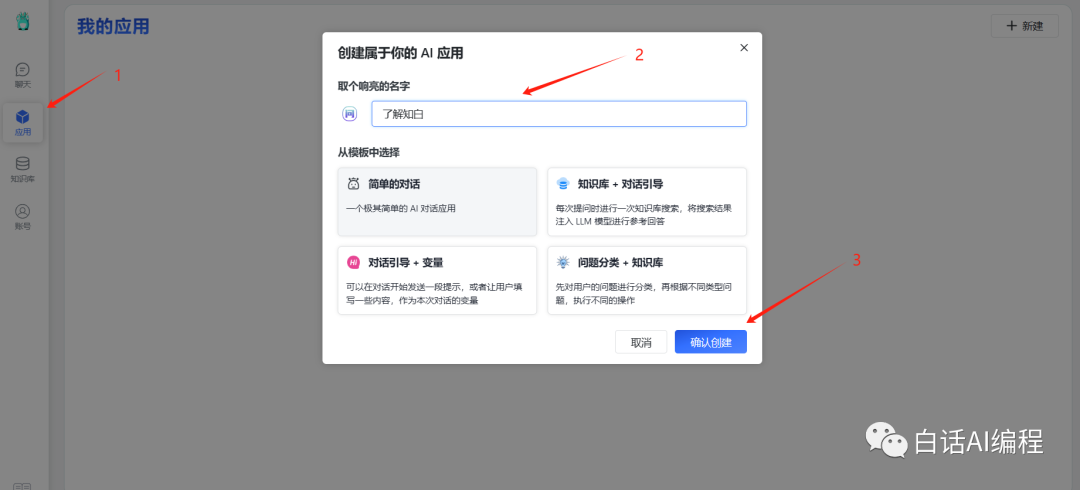
2. 使用知识库
创建一个应用来使用知识库。
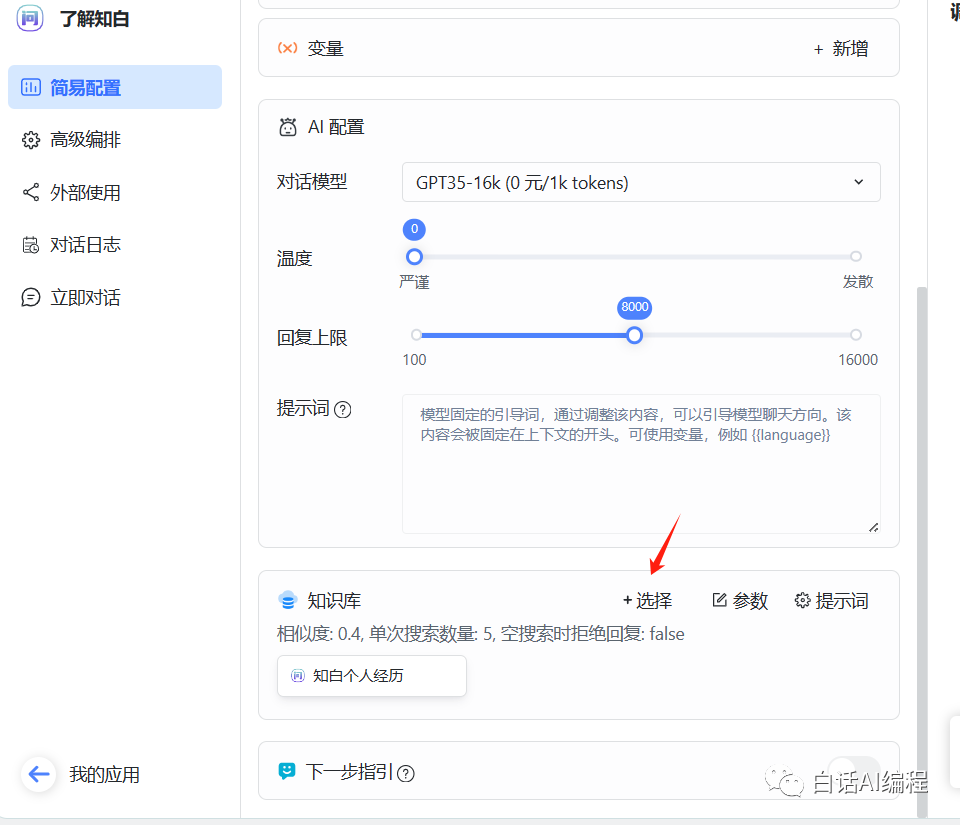
这里简单设置了一下开场白,选择并绑定对应知识库。
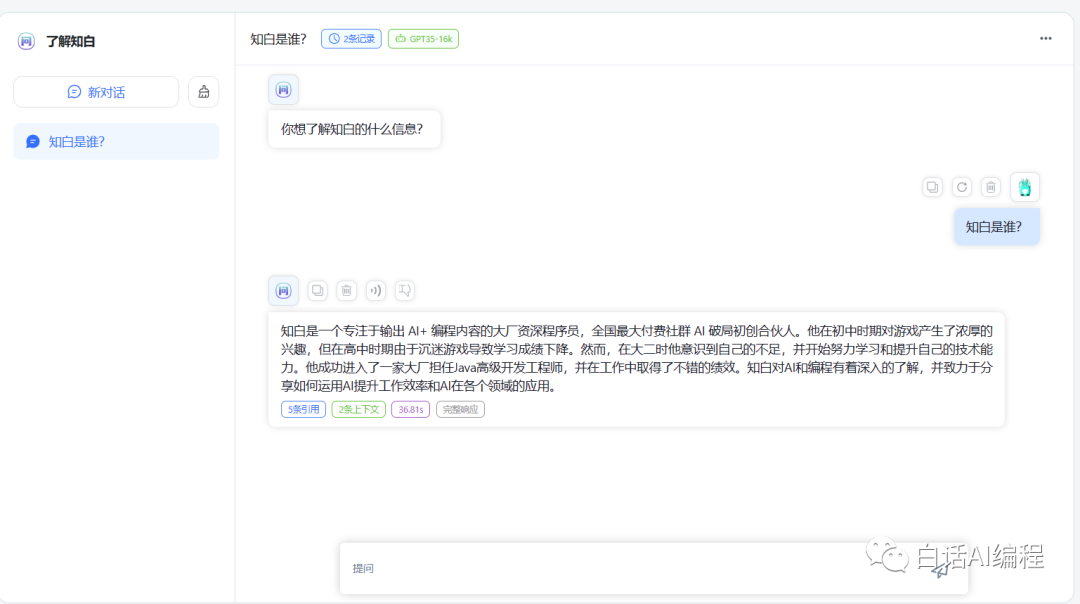
开始对话,效果展示如下:
三、总结
我们从零到一完成了本地个人知识库的搭建,整体花费时间也较短,刨除安装 Docker 的时间预计在10分钟左右。
后续对召回内容从多方面进行详细分析,从而使回答内容更加符合我们的预期。
如何学习大模型 AGI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/850359?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

