
热门标签
热门文章
- 1使用sklearn学习多项式回归(三)_sklearn 多项式回归
- 2STM32入门学习(一):STM32 简介与软件安装
- 3【无人驾驶系列】基于ROS的无人驾驶系统
- 4git clone代码报错:fatal: unable to checkout working tree
- 5【EI会议】2024年光电信息、光学工程与机器视觉国际学术会议(OIOEMV 2024)_光电信息会议
- 6python判断文件或文件夹是否存在、创建文件夹_python判断文件夹存不存在
- 7大模型公开课:探索人工智能的未来与挑战_大模型 算法 挑战
- 8可消费的媒体类型和可生成的媒体类型
- 9MySQL数据库——数据库设计概念和数据库设计步骤_数据库设计: - 设计数据库表结构,包括充电桩、用户、订单等相关表。 - 创建数据库
- 10防火墙的安全策略_防火墙没做策略无法访问
当前位置: article > 正文
Stable Diffusion系列(七):实现SD webui的全盘汉化_sd webui怎么切换中文
作者:一键难忘520 | 2024-07-17 12:39:40
赞
踩
sd webui怎么切换中文
插件下载
SD webui中用于汉化的插件统一叫localization(本地化),使用时需要安装这两个插件,一个用于开启本地化支持,一个用于中文本地化。
插件安装完成后,进入\extensions\stable-diffusion-webui-localization-zh_CN\localizations这个路径下,可以看到一个名为zh_CN.json的文件,打开之后如下图所示,每一行的第一部分是英文原文,第二部分是要翻译成的中文,插件会自动完成替换
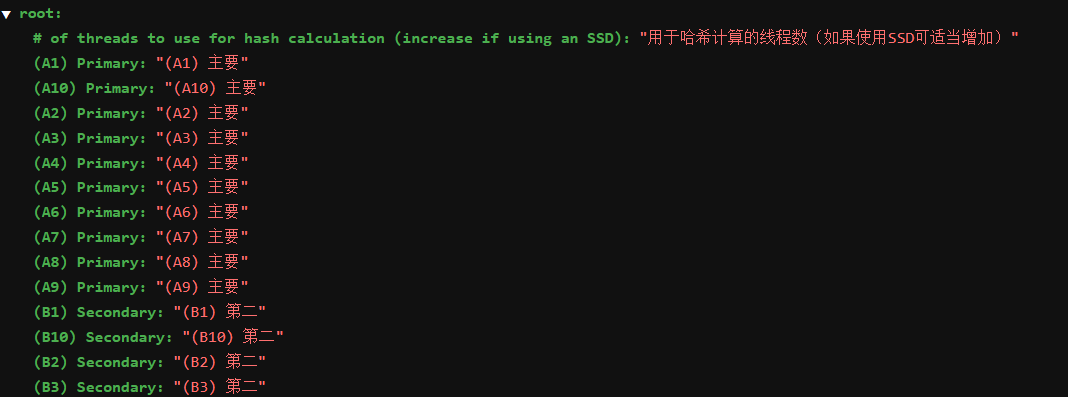
但是在实际的界面中,仍然有很多东西没有更新,原来这已经是几个月前的文件了,跟不上进度了
文件合并
于是我又搜了搜其他的本地化插件,发现还有其他的简体字插件zh-Hans(Stable).json和繁体字插件zh_Hans.json可用,并且日期比较新。
所以现在目录下就有一下三个JSON文件,且从质量上来说,zh_CN.json>zh-Hans(Stable)>zh_Hans.json。
因此,按照优先级zh_CN.json>zh-Hans(Stable)>zh_Hans.json的顺序,完成JSON文件的合并,代码如下所示。注意要完成繁体到简体的转换。
这是我给ChatGPT的问题:
我有zh_CN.json、zh-Hans(Stable)、zh_Hans.json这三个用来翻译英文到中文的文件,它们包含的内容(英文原文:中文翻译)是部分重叠的,并且翻译质量逐个递减。现在我要你写一段python代码,将这三个文件按顺序两两合并成一个文件,保存为merge.json。注意zh_Hans.json中翻译的结果是繁体中文,你需要转换成简体字。
下面是回答的代码
# pip install opencc-python-reimplemented import json from opencc import OpenCC # 初始化繁体转简体的转换器 cc = OpenCC('t2s') # 读取 JSON 文件内容 def read_json(file_path): with open(file_path, 'r', encoding='utf-8') as file: return json.load(file) # 合并两个字典,第二个字典的内容会覆盖第一个字典的内容 def merge_dicts(dict1, dict2): merged = dict1.copy() merged.update(dict2) return merged # 读取三个 JSON 文件 zh_CN = read_json('zh_CN.json') zh_Hans_Stable = read_json('zh-Hans (Stable).json') zh_Hans = read_json('zh_Hans.json') # 将繁体中文转换为简体中文 zh_Hans_simplified = {key: cc.convert(value) for key, value in zh_Hans.items()} # 按顺序合并字典 merged = merge_dicts(zh_Hans_Stable, zh_Hans_simplified) merged = merge_dicts(merged, zh_CN) # 保存合并后的结果到 merge.json with open('merge.json', 'w', encoding='utf-8') as file: json.dump(merged, file, ensure_ascii=False, indent=4) print('Merge completed and saved to merge.json')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
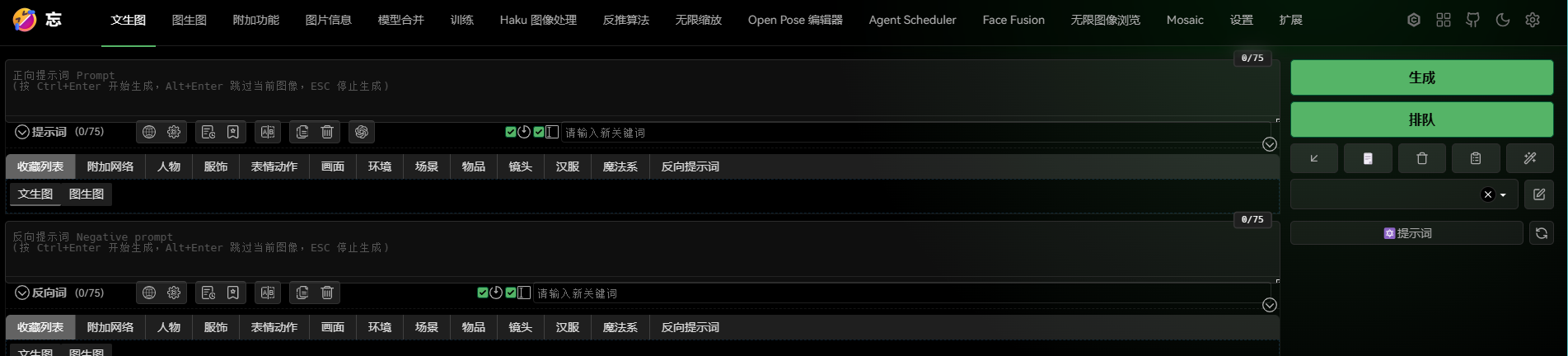
插件启用
进入设置里的用户界面

重启之后
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/839961
推荐阅读
相关标签

