
数学建模之聚类算法(K-means)_k平均聚类初始聚类中心和最终聚类中心是什么
赞
踩
K-means聚类算法k-means算法以k为参数,把n个对像分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。 1、随机选择k个点作为初始的棸类中心。 2、对于剩下的点,根据其与棸类中心的距离,将其归入最近的簇。 3、对于每个簇,计算所有点的均值作为新的聚类中心。 4、重复2、3直到棸类中心不再发生改变。 |
加载数据, 创建K-means算法实例, 井进行训练, 获得标签。 调用K-Means方法所需参数: 1、n_clusters:用于指定聚类中心的个数。 2、 init:初始聚类中心的初始化方法。 3、 max_iter:最大的迭代次数。 4、一般调用时只用给出n_clusters即可,init默认是 k-means ++ , max_iter默认是300。 5、fit_predict():计算簇中心以及为簇分配序号。 |
将城市按照消费水平分成n_clusters类,消费水平相近的城市聚集在一类中。 |
| expens:聚类中心点的数值加和,也就是平均消费水平。 |
n_clusters=2时,聚类的结果

n_clusters=3时,聚类的结果

n_clusters=4时,聚类的结果

| 结论:从这几次聚类的比较中可以看出,消费水平相近的省市聚集在一类。而北京、上海和广东很稳定的一直聚集在同一类中,在当k = 4时,这样的一种聚类可以比较明显的看出消费层级。 |
K-Means的扩展改进计算两条数据相似性时, Sklearn的K-Means默认使用的是欧式距离。虽然还有余弦相似度, 与马氏距离等多种方法,但没有设定计算距离方法的参数。如果要改变计算距离的公式时,可以改变K-means的源代码。 |
K-Means算法
![]()
| k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。 |
|
例4:对16个地区居民生活水平的进行分析。数据为我国16个地区的农民在1982年支出的抽样情况,每个地区都调查反映每个人平均生活消费支出情况的6个指标。利用K-Means聚类的方法分析进行分类。 Step1:第一步一定是先将数据预处理(查找缺失值、消除量纲与标准化) 在SPSS进行操作得到: |
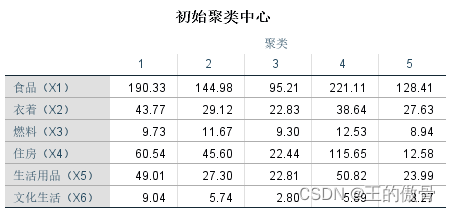
| 初始聚类中心表:系统自动选出了5个初始聚类中心,分别为以下地区:北京、江苏、河北、上海和内蒙古。以上初始类中心基本包括了16个地区中高消费到低消费地区的各个层次。 |
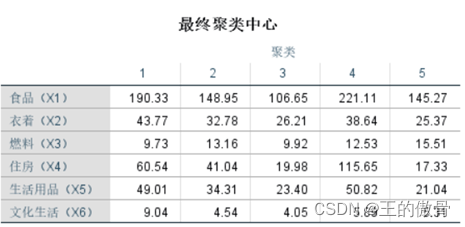
| 最终聚类中心:表示各类地区消费水平指数。(实际意义) 最终聚类中心的距离:表示各个类之间的差距。 |
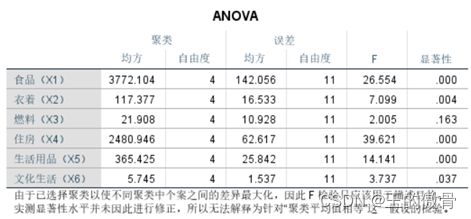
| 方差分析表:表示各指数在不同地区的均值比较,即五类地区之间的差异。观测图中的数据:X3和X6在聚类分析得出的类别都呈现出了显著差异,可见这两个变量在聚类分析中没有起到作用,当前聚类分析结果可以不能用数据的聚类。 |
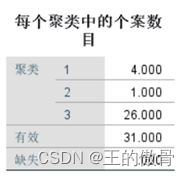
| 系统聚类与K-means的区别 |
| 系统聚类 | K-means聚类 |
| 事先不需要确定要分多少类 自动确定最佳分类数 | 事先需要确定要分多少类 |
| 计算量较大,对大量数据的聚类效率不高 | 计算量小,适于数据量大的聚类 |
| 可对个案和变量聚类 | 不能对变量聚类,所使用的变量必须是连续变量。 |
| 可以绘制出树状聚类图,方便使用者直观选择类别 |

