
- 1OeceanBase开发者大会·2024精彩内容回顾_林春 oceanbase开发者大会 bilibili
- 2matlab rho是什么意思,rho(rho值是什么意思)
- 3李航机器学习之决策树CART算法_cart算法问题
- 42021 字节前端面试题汇总
- 5软件崩溃时Visual Studio中看不到有效的调用堆栈,使用Windbg动态调试去分析定位_visual studio 堆栈分析
- 6太高效!ChatGPT论文润色攻略
- 7zookeeper+schedule实现分布式定时任务_schedulelock zk
- 82024最新免费版轻量级Navicat Premium Lite 下载和安装教程
- 9Python吴恩达深度学习作业10 -- 深度学习框架TensorFlow入门 + 完整图像识别实战_result = sess.run函数的使用
- 10贵州农信DevOps研发转型,加速乡村振兴最后一公里
centos7 配置单机 HDFS_centos如何部署单点的hdfs集群
赞
踩
Centos 7 上配置 HDFS(单机版)
一、配置Java环境
二、配置Hadoop
前提是配置好java 环境;
1、配置ssh免密登录
(1)
ssh-keygen
- 1
一直回车
(2)将生成的密钥发送到本机地址
ssh-copy-id localhost
- 1
(注意:若报错找不到命令则需要安装openssh-clients执行:yum -y install openssh-clients 即可)
(3)测试免登录是否成功
ssh localhost
- 1
2、安装hadoop
(1)下载Hadoop
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
- 1

(2)、通过第三方软件 Xshell 将已下载好的Hadoop上传到Centos系统上
首先将下载的包放在Xshell的安装目录下

用 Xshell FTP链接centos

在命令界面输入
put XXX.tar.gz
- 1
如下图所示,稍等一会就上传完毕。
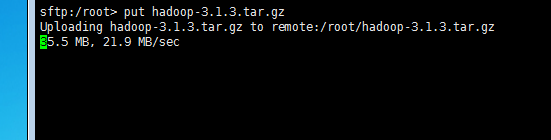
(3)开始安装hadoop
解压缩文件
tar -zxvf haddop-XXX.tar.gz
- 1
配置hadoop环境变量: 编辑文件 /etc/profile
vim /etc/profile
- 1
在文件末尾添加如下(具体位置自看自己目录位置):
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
- 1
- 2

退出编辑后进行保存(该命令只在该命令窗口有效,若使其一直有效,重启系统即可)
source /etc/profile
- 1
(4)验证hadoop是否安装成功
hadoop version
- 1
显示如图所示说明Hadoop安装成功,接下来只需要配置Hadoop 的配置文件即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ksDGxXB-1574124404790)(5.jpg)]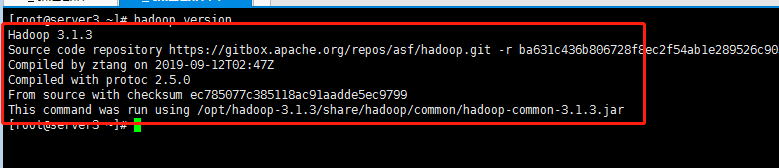
3、HDFS配置
(1)、Hadoop中的重要目录说明
1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
4)sbin目录:存放启动或停止Hadoop相关服务的脚本
5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(2)、配置 hadoop下 /etc/hadoop 的 hadoop-env.sh 文件
在该文件中添加Java的JAVA_HOME
export JAVA_HOME=具体目录根据自己的环境配置
- 1
如下图所示
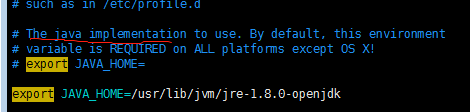
(3)、修改 hadoop下 /etc/hadoop 的 core-site.xml 文件
修改如下
<configuration>
<!--这里路径是namenode 、datanode 等存放的公共临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data_hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!--设置hdfs中服务的主机和端口号-->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.249.133:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(4)、修改 hadoop下 /etc/hadoop 的 hdfs-site.xml 文件
修改如下
<configuration> <!--设置hdfs中的namenode文件目录--> <property> <name>dfs.namenode.name.dir</name> <value>/opt/data_hadoop/dfs/name</value> <final>true</final> </property> <!--设置hdfs中的datanode文件目录--> <property> <name>dfs.datanode.data.dir</name> <value>/opt/data_hadoop/dfs/data</value> <final>true</final> </property> <!--设置数据块副本(由于是单机所以1即可)--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--hdfs的访问权限设置为false--> <property> <name>dfs.permissions</name> <value>false</value> </property> <!--web界面访问--> <property> <name>dfs.http.address</name> <value>192.168.249.133:50070</value> </property> <!--开启webhdfs--> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
(5)、格式化namenode
在启动hadoop集群前需要格式化namenode。需要注意的是,第一次安装Hadoop集群的时候需要格式化Namenode,以后直接启动Hadoop集群即可,不需要重复格式化Namenode。
在Hadoop目录下输入如下命令
bin/hdfs namenode -format
- 1
(6)、启动
启动前需要在start-dfs.sh加入以下,stop-dfs.sh 也需要加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
在hadoop目录下输入
sbin/start-dfs.sh
- 1
(7)、访问(根据自己的地址来访问)
192.168.249.133:50070
- 1



