
- 15G基础学习1、5G网络架构、网络接口及协议栈_5g网络拓扑图
- 22020-10-24 文件系统
- 3[大模型]GLM-4-9B-Chat vLLM 部署调用
- 4git版本回退和分支_master 分支回退
- 5记一次阿里java实习生面试(失败)_孩子华为阿里实习面试失败了都
- 6吾辈楷模!国人开源的Redis客户端被Redis官方收购了!_ioredis多少钱被收购
- 7SwiftUI 控件_swiftui控件介绍
- 8如何在 SwiftUI 中以编程方式滚动列表?_swiftui scrollviewreader scrollto
- 9vulnhub靶机渗透 FRISTILEAKS: 1.3_vulnhub: fristileaks安装
- 10Linux下Signal信号_linux中又是如何等待信号到来的
数据结构——散列表查找性能综合实验 #散列表 #树表 #线性探测法 #拉链法 #装填因子 #查找 #实验报告
赞
踩
目录
一、概述
通过编写两种具有不同冲突处理方式的散列表,并改变散列表的哈希除数,装填因子等,探究其对平均查找长度 ASL,即查找效率的影响。并将散列表查找和树查找进行结合,发挥各自优势,寻找效率更高的散列表查找方法。
二、代码
1.头文件和存储结构
- #include <stdio.h>
- #include <time.h>
- #include <stdlib.h>
- #include <math.h>
-
- int arr[10010] = {0};
- int q[10010] = {0};
-
- struct Node{
- int data;
- struct Node *next;
- } node[10010];
-
- struct TreeNode{
- int data;
- struct TreeNode *lchild;
- struct TreeNode *rchild;
- } tnode[10010];

2.生成随机数
- // 生成随机数
- void RandNumber(int n)
- {
- for(int i = 0;i < n;i ++){
- // 生成1-100000的随机数并存入数组
- arr[i] = rand() % (100000) + 1;
- }
- }
该函数功能为生成指定区间的随机数并存入数组。指定数据长度,采用rand函数生成位于区间[1,100000]的数据存入arr数组,为后续实验提供数据。
3.主函数
- int main()
- {
- int n = 1000; // 数据个数
- int p = 1000; // 除数
- int len = 1040; // 散列表长度
- double x = n / len; // 装填因子
-
- RandNumber(n);
-
- // Init(n,p,len); // 创建散列表(线性探测法)
- // SingleSearch(23782,p,n,len);
- // AllSearch(p,n,len);
-
- // Init_zip(n,p,len);
- // SingleSearch_zip(arr[0],p,n,len);
- // AllSearch(p,n,len);
-
- // Init_ZipAndTree(n,p,len);
- // SingleSearch_Tzip(arr[2930],p,n,len);
- // AllSearch(p,n,len);
-
- // printf("%d",arr[38]);
- // printf(" %d",q[0]);
- return 0;
- }
在主函数中对散列表的属性进行定义和赋值,并根据要测试的方法选择性注释无关函数,实验时向子函数中传入需要使用的参数。使用此方法有效地发挥了主函数与子函数之间的调用关系,可以使程序架构更加清晰,从而简化实验过程。
4.1.初始化-线性探测法
- // 创建散列表-线性探测法
- void Init(int n,int p,int len)
- {
- // n:数据长度 p:除数 len:散列表长度
- for(int i = 0;i < n;i ++){
- int temp;
- temp = arr[i];
- if(q[temp % p] == 0){
- q[temp % p] = temp;
- }
- else{
- int k = temp % p;
- while(++ k){
- if(k >= len){
- k = 0;
- }
- if(q[k] == 0){
- q[k] = temp;
- break;
- }
- }
- }
- }
- }
该函数功能为创建散列表,并以线性探测法处理冲突。在主函数中准备好数据长度n,除数p,散列表长度len参数,并将其作为参数传入该子函数,从创建好的随机数数组中读入测试数据以创建散列表。创建采用除留余数法,并考虑伪指针到达表尾后重新指向表头的返回操作。
4.2.单个元素查找-线性探测法
- // 查找单个元素-线性探测法
- double SingleSearch(int ele,int p,int n,int len)
- {
- // 函数return查找长度
- int k = ele % p;
- double times;
- int i;
- for(i = k,times = 1;times <= len;i ++,times ++){
- if(i >= len){
- i = 0;
- }
- if(ele == q[i]){
- printf("查找成功!\n‘%d’位于散列表的第%d个结点\n",ele,i+1);
- return times;
- }
- if(q[i] == 0){
- printf("查找失败!\n");
- return 0;
- }
- }
- printf("查找失败!\n");
- return 0;
- }
该函数功能为在已创建好的散列表中查找多个数据,并输出平均查找时间和平均查找长度(ASL)。从数组中读入要查找的数据,然后对每个数据调用SingleSearch函数,并记录该函数运行时间和查找长度,累加求和。查找文件中所有数据后,计算并输出该数据集的平均查找时间和平均查找长度。
SingleSearch函数:该函数利用除数p首先找到关键字对应位置,判断该位置元素是否符合待查找元素,若符合则查找成功,若该位置元素为0,则说明查找失败(数据元素中不包含0,若该结点为0,则表示散列表该结点无值),若不符合且不为0,则将伪指针后移继续查找,并考虑查找到散列表尾部的返回头部情况。
5.1.初始化-拉链法
- // 创建散列表-拉链法
- void Init_zip(int n,int p,int len)
- {
- // n:数据长度 p:除数 len:散列表长度
- struct Node *q,*pre;
- for(int i = 0;i < n;i ++){
- struct Node *temp;
- temp = (struct Node *)malloc(sizeof(struct Node));
- temp->next = NULL;
- temp->data = arr[i];
- q = &node[temp->data % p];
- while(q->data){
- pre = q;
- q = q->next;
- if(!q){
- q = (struct Node *)malloc(sizeof(struct Node));
- }
- pre->next = q;
- }
- *q = *temp;
- }
- }
该函数功能为创建散列表,并用拉链法处理冲突。将提前准备好的数据存储在数组中,从数组中读取数据,在函数体内定义临时指针变量temp用于将数据整合进散列表,定义指针q指向满足余数要求的顺序表位置,如果当前位置已存储元素,则将pre变量指向q,并将q后移,直到找到q的数据域为NULL时,为q分配动态内存,结束循环,将临时变量的值赋给指针q所指位置(其间指针pre用来保证结点指针域的连接)。
5.2.单个元素查找-拉链法
- // 查找单个元素-拉链法
- double SingleSearch_zip(int ele,int p,int n,int len)
- {
- int k = ele % p;
- double times = 1;
- struct Node *q;
- q = &node[k];
- for(int i = 0;;i ++){
- if(q == NULL){
- printf("查找失败!\n");
- return 0;
- }
- if(q->data == ele){
- printf("查找成功!\n‘%d’位于散列表的第%d个结点的第%.0lf位\n",ele,k+1,times);
- return times;
- }
- else{
- times ++;
- q = q->next;
- }
- }
- }
AllSearch函数原理与4.2相同。
SingleSearch_zip函数:首先根据除数p找到指定元素ele关键字的位置,然后判断该位置数据域是否符合ele,若该位置为NULL,则表明该结点未被赋值,查找失败;若符合则查找成功;若不符合则将指针后移,依次判断顺序表当前位置的纵向链表结点,并记录times。
6.1.初始化-综合散列表和树表
- // 综合散列表和树表
- void Init_ZipAndTree(int n,int p,int len)
- {
- struct TreeNode *q,*root;
- for(int i = 0;i < n;i ++){
- struct TreeNode *temp;
- temp = (struct TreeNode *)malloc(sizeof(struct TreeNode));
- temp->lchild = NULL;
- temp->rchild = NULL;
- temp->data = arr[i];
- q = &tnode[temp->data % p];
- while(q->data){
- root = q;
- if(temp->data < root->data){
- q = q->lchild;
- if(!q){
- q = (struct TreeNode *)malloc(sizeof(struct TreeNode));
- }
- root->lchild = q;
- }
- else{
- q = q->rchild;
- if(!q){
- q = (struct TreeNode *)malloc(sizeof(struct TreeNode));
- }
- root->rchild = q;
- }
- }
- *q = *temp;
- }
- }
该函数功能为创建散列表,并结合树表处理冲突。将提前准备好的数据存储在数组中,从数组中读取数据,在函数体内定义临时指针变量temp用于将数据整合进散列表,定义指针q指向满足余数要求的顺序表位置,如果当前位置已存储元素,则采用树表的方式处理冲突,判断ele与当前结点数据域的大小关系,并放在左子树或右子树,若该结点有值,则继续循环直到找到无值结点放入ele元素。
6.2.单个元素查找-综合散列表和树表
- // 查找单个元素-综合散列表和树表
- double SingleSearch_Tzip(int ele,int p,int n,int len)
- {
- int k = ele % p;
- double times = 1;
- struct TreeNode *q;
- q = &tnode[k];
- for(int i = 0;;i ++){
- if(q == NULL){
- printf("查找失败!\n");
- return 0;
- }
- if(q->data == ele){
- printf("查找成功!\n'%d'位于位于散列表的第%d个结点的第%.0lf层\n",ele,k+1,times);
- return times;
- }
- else{
- if(ele < q->data){
- q = q->lchild;
- }
- else{
- q = q->rchild;
- }
- times ++;
- }
- }
- }
SingleSearch_Tzip函数:该函数参考拉链法的单个数据查找函数,区别在于首次查找失败后的指针移动问题,拉链法只是简单的指针后移,该方法需要结合树表的方法判断ele与左右子树数据域的大小关系再选择指针移动方向。
同样将该SingleSearch函数整合进AllSearch函数,在主函数中调用AllSearch函数进行实验数据记录。
7.多个数据查找,并计算ASL和平均查找时间
- // 查找多个元素
- void AllSearch(int p,int n,int len)
- {
- clock_t start,stop;
- double times = 0; // 用于计算average time
- double sum = 0; // 用于计算average search length
- for(int i = 0;i < n;i ++){
- start = clock();
-
- // sum += SingleSearch(arr[i],p,n,len); // 线性探测法
- // sum += SingleSearch_zip(arr[i],p,n,len); // 拉链法
- // sum += SingleSearch_Tzip(arr[i],p,n,len); // 散列表+树表
-
- stop = clock();
- printf("\n");
- times += stop - start;
- }
- double avelen = sum / n;
- printf("Average Time: %.2lfms\n",times / n);
- printf("Average Search Length: %.2lf\n",avelen);
-
- }
4.2、5.2、6.2已详细说明。
三、实验结果
1.对比不同数据规模下两种冲突处理方法的ASL
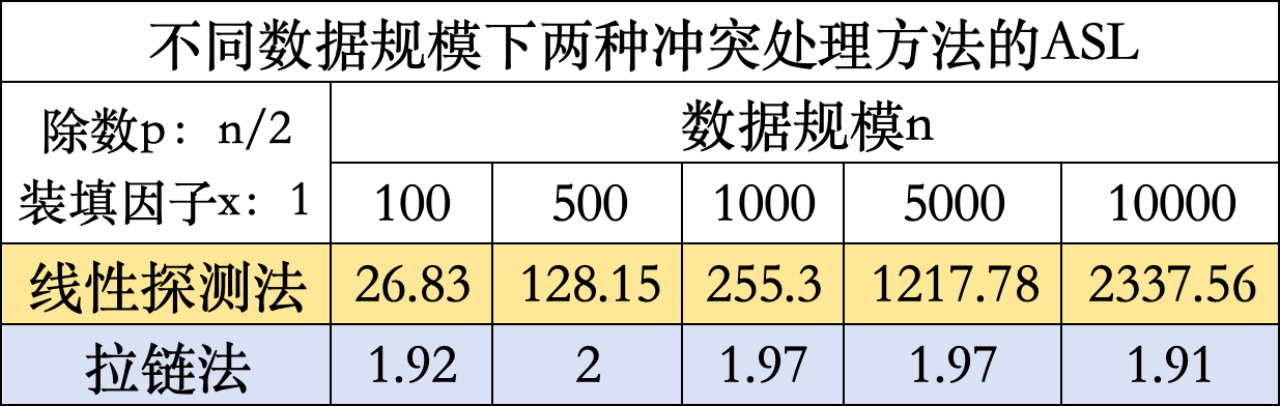
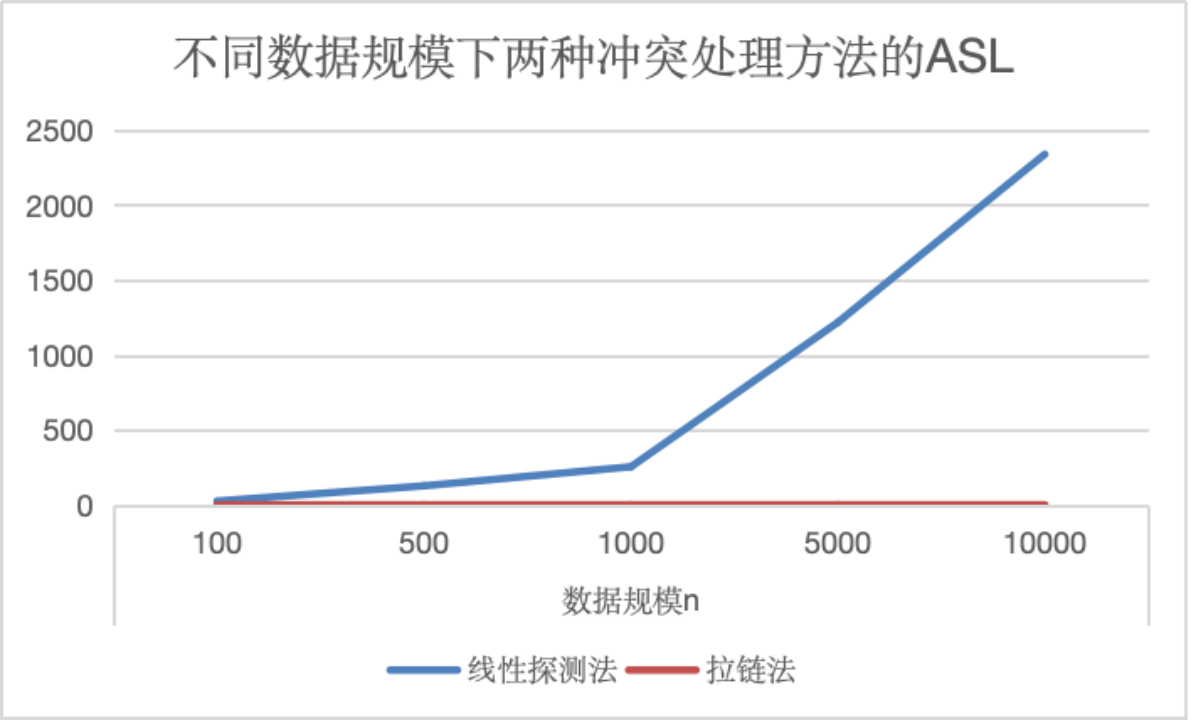
为确保除数p始终小于散列表长度,且对不同数据规模具有适用性和普遍性,因此采用n / 2作为除数而不采用固定值,并保证散列表长度和数据长度相等,即装填因子x为1,对比此情况下两种冲突处理方法的差异。
由图可得,在数据规模n取不同值的情况下,线性探测法的ASL普遍大于拉链法,且随数据规模的增加,差异逐渐明显。因此可以得出初步结论,在创建散列表时,利用拉链法往往能使查找效率更高。
2.对比不同除数下两种冲突处理方法的ASL
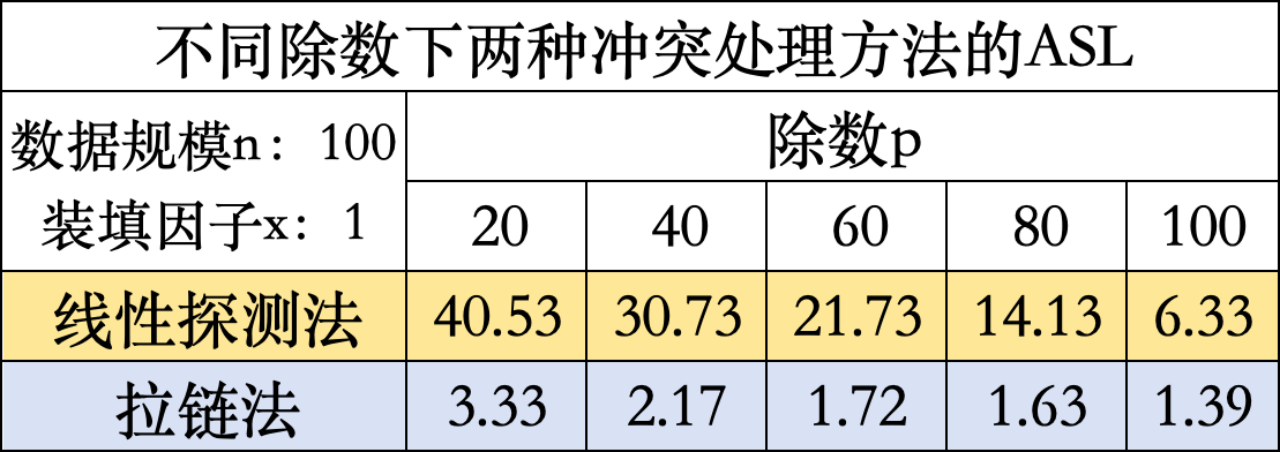
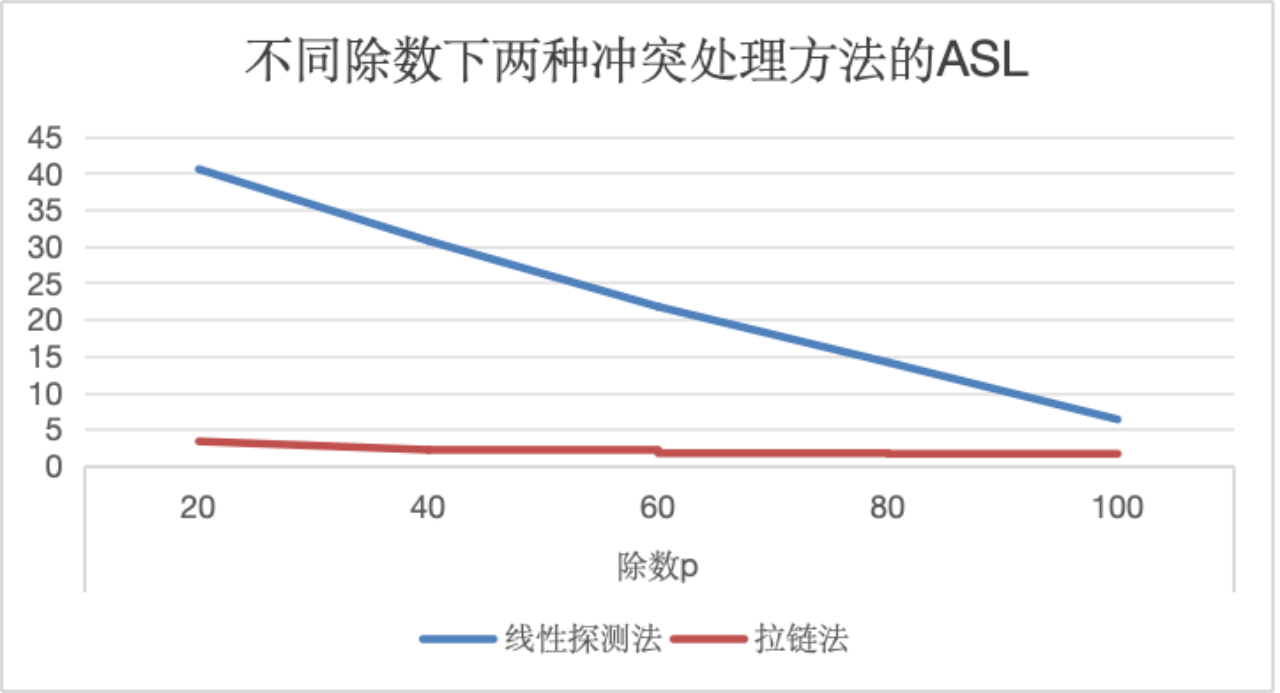
由于实验结果1.得出线性探测法与拉链法的显著差异,因此为确保拉链法数据在折线统计图表中的趋势可视性,采用较小的数据规模100,分别对比不同除数下的ASL变化趋势。
实验结果如图所示,两种冲突处理方法在随除数p(小于散列表长度)逐渐增大时,ASL呈下降趋势,分析得出除数与散列表长度越相近时,发生冲突需要移动的次数越少,查找效率越高。实验数据同样得出拉链法相较于线性探测法的优越性。
3.不同装填因子下两种散列表的平均查找时间和ASL
由于拉链法散列表长度允许小于数据长度(仅需满足len >= p,即可保证所有关键字均可以找到位置,预计散列表长度(或装填因子)对查找性能无影响),而线性探测法不具有此特性。因此对两种方法分开讨论,为保证实验的准确性和全面性,引入新的衡量标准——平均查找时间(记为AST):
(1)线性探测法
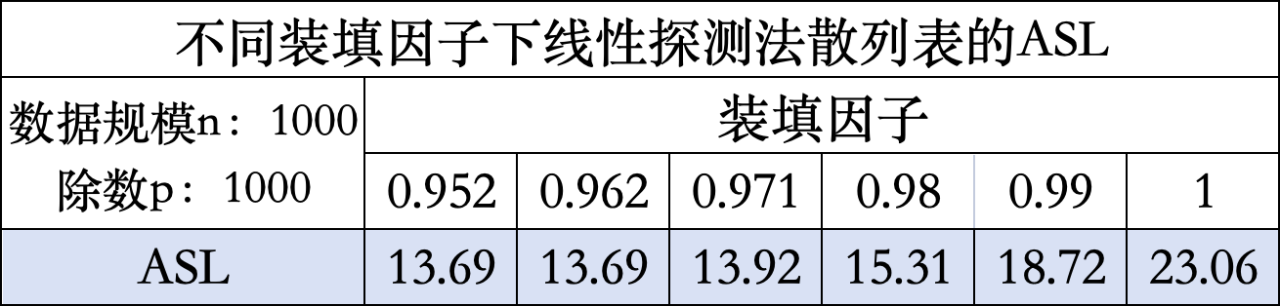
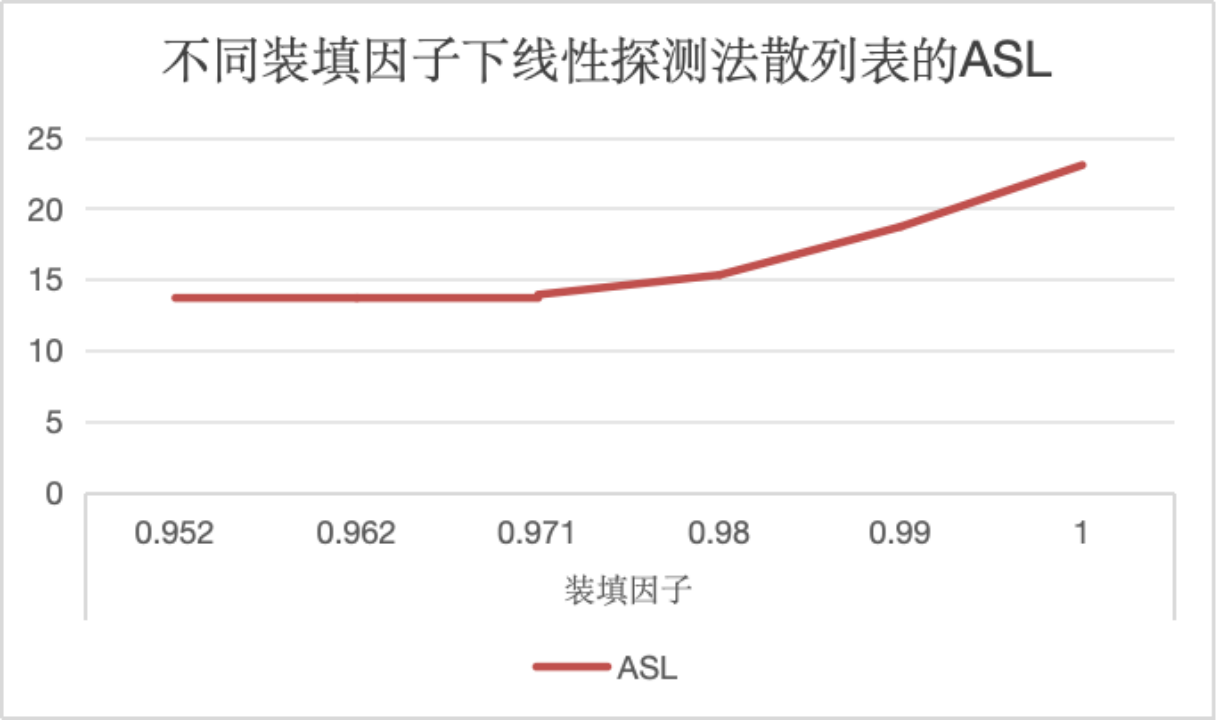

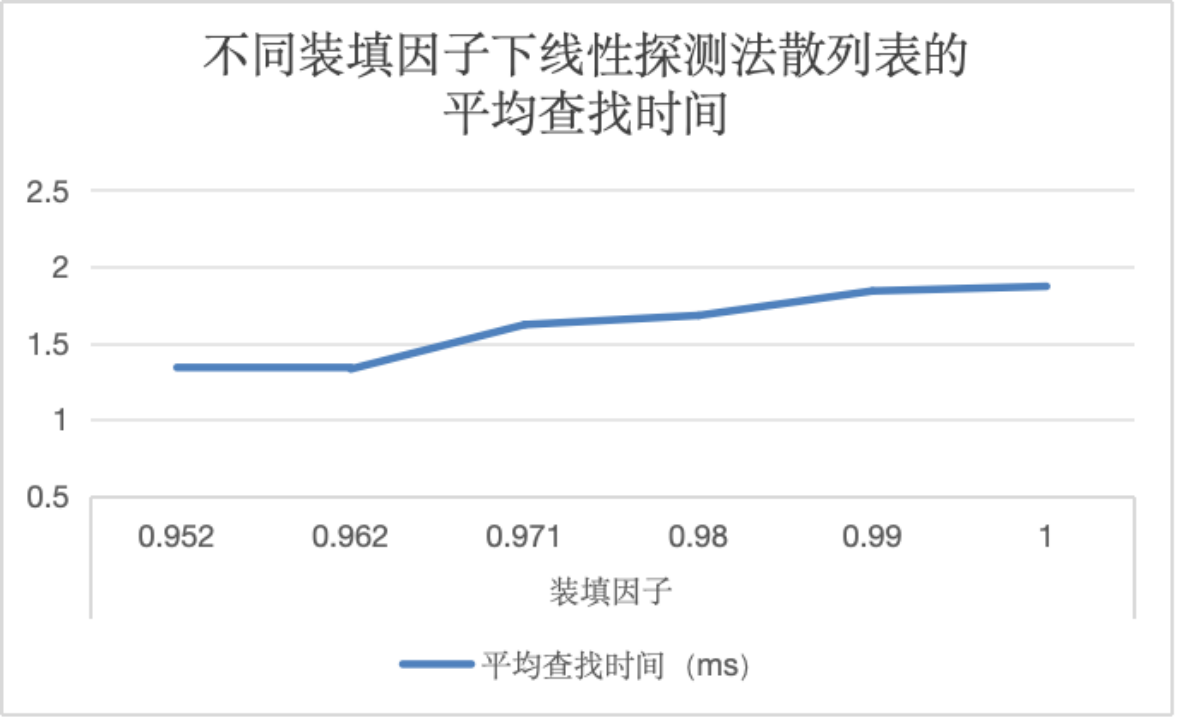
为使实验结果趋势更加明显且尽可能具有普遍性,数据规模n采用1000,除数p采用1000。
结合ASL和AST分析得出:随装填因子的增大,查找效率先几乎不变,后下降。分析其原因,发现若装填因子较小时,发生冲突的可能性较小,且处理冲突的成本也可能更小,但当装填因子小于一定值后,散列表的空位较多,对于解决索引值冲突问题性能过剩,查找效率将不发生改变;当装填因子较大时,发生冲突的可能性增加,解决冲突的成本可能更高,从而导致一部分数据的查找效率降低。
(2)拉链法
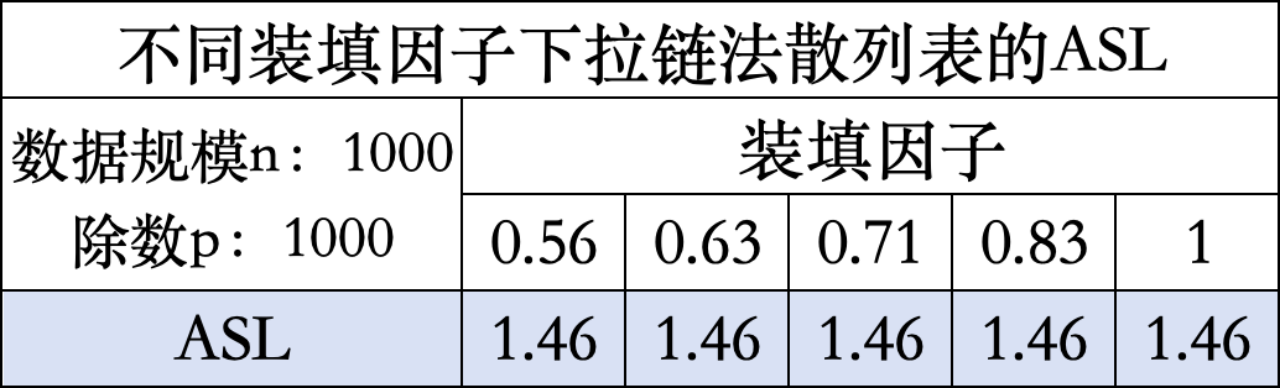
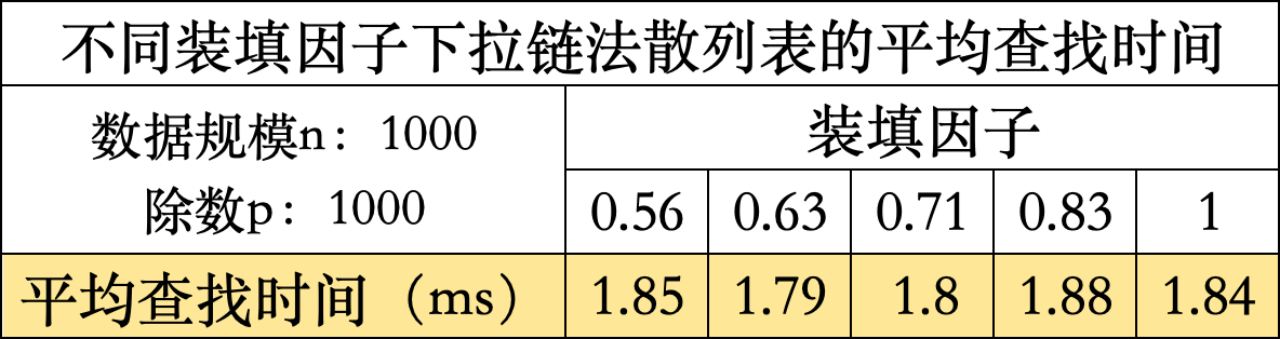
为避免无关变量造成的偶然性,拉链法的散列表属性遵循线性探测法,即数据规模n为1000,除数p为1000。
结合ASL和AST分析得出:随装填因子的增大,查找效率几乎无变化,因为拉链法计算得出关键字位置后不会再对位置进行改变,而是采用链式结构纵向延伸,因此装填因子(或散列表长度)对查找效率几乎无影响。成功验证了先前对拉链法实验结果的预期。
通过分析以上两种散列表的实验数据,发现装填因子会在一定程度上影响线性探测法散列表的查找性能,装填因子较大时,散列表内数据密度也会更大,冲突发生的概率就会增加,因此若采用处理冲突性能较差的线性探测法时,就容易导致查找效率下降的情况;若采用处理冲突效率较高的拉链法,查找效率将不会受到影响,但可能会导致内存空间的浪费。
4.对比散列表+树表法与拉链法的ASL
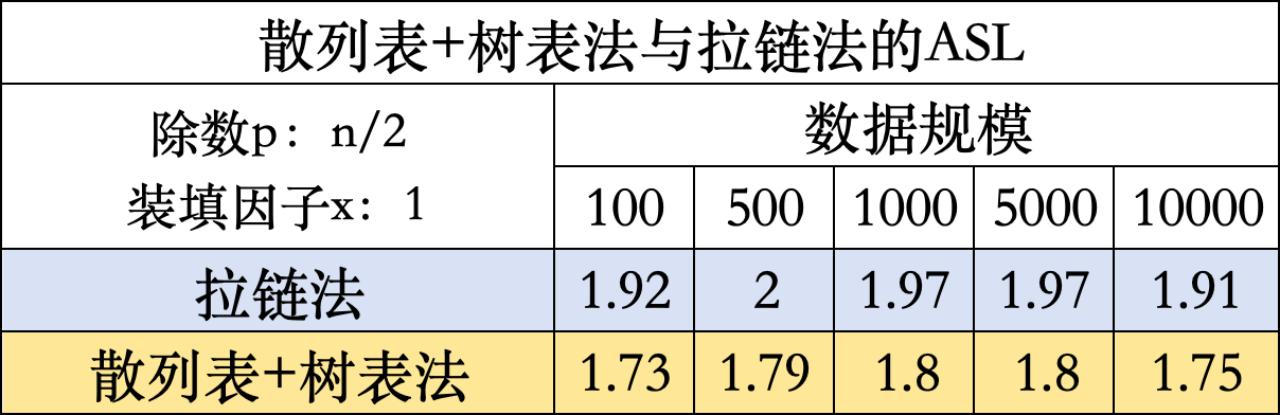
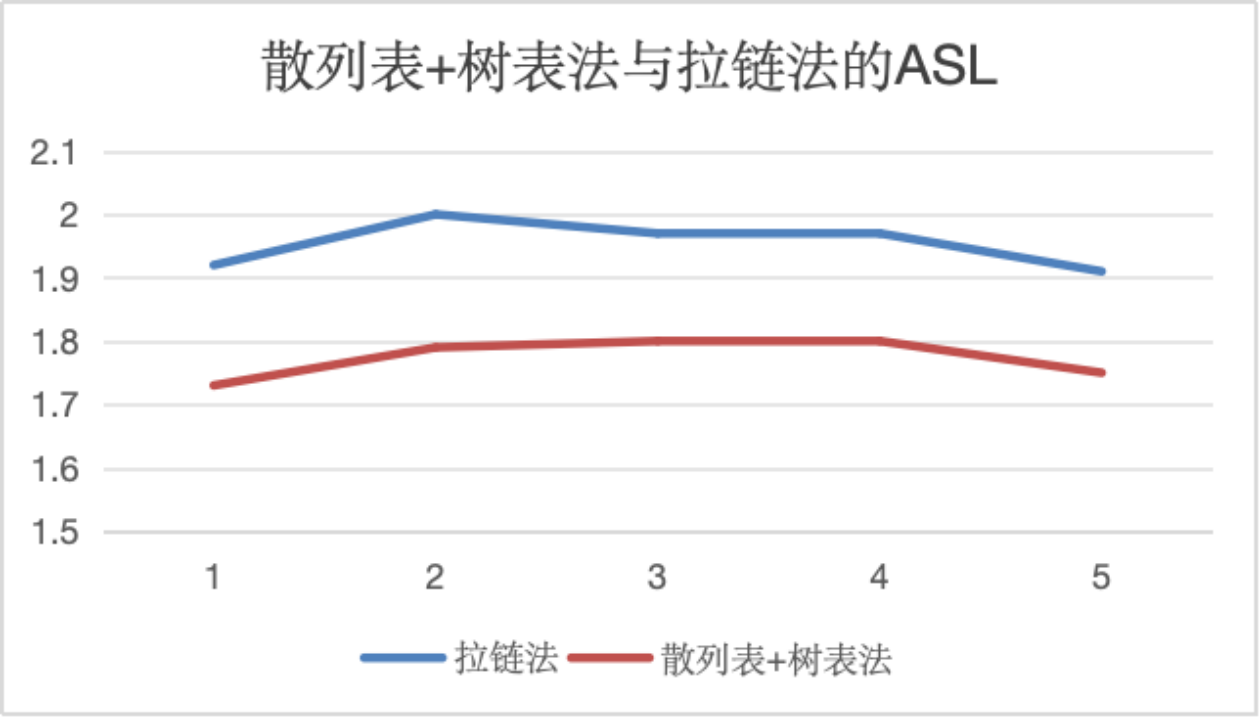
实验原理与1.类似,采用数据规模作为变量,为确保除数p始终小于散列表长度,且对不同数据规模具有适用性和普遍性,因此采用n / 2作为除数而不采用固定值,并保证散列表长度和数据长度相等,即装填因子x为1。选择1.中查找效率更高的拉链法与散列表+树表法进行对比。
实验结果表明:在不同数据规模下,散列表+树表法的查找效率普遍高于拉链法。结合数据结构算法进行分析,发现两种方法的区别在于冲突处理方式,拉链法只是单一将指针后移,而散列表+树表法则是根据待查找元素与当前根结点数据域的关系选择进入左子树或右子树继续查找,因此理论上减少了冲突处理成本,查找效率更高。
四、实验结论
1.拉链法的查找效率普遍高于线性探测法。
因为在查找过程中,遇到冲突时两种方法采用不同的处理思路:线性探测法向下一个结点移动,直到找到查找元素,因此若装填因子较大时,需要移动的平均次数也会增多,从而降低查找效率;拉链法则是对该结点进行纵向延伸,依托遍历链表的方式对顺序表的指定结点进行深度遍历,直到找到查找元素,因此在数据均匀分散且关键词重复次数较少时,拉链法具有明显的优势,但是也容易导致在装填因子较小的情况下,数据量小于散列表长度时,导致内存空间的浪费。
2.在一定情况下,除数越接近散列表长度时,查找效率越高。
在除数越接近散列表长度时,越可能存在索引值,使其仅需一次判断便可进入散列表的末位,尽可能少地存在需要发生冲突时才能访问到的位置。因此除数与散列表长度越接近(p <= len)时,发生冲突的可能性越小,处理冲突的效率更高,查找效率也更高。
3.在一定范围内,装填因子越大,线性探测法的查找效率越低。
装填因子会在一定程度上影响散列表的查找性能,装填因子较大时,散列表内数据密度也会更大,冲突发生的概率就会增加,因此若采用处理冲突性能较差的线性探测法时,就容易导致查找效率下降的情况;若采用处理冲突效率较高的拉链法,查找效率将不会受到影响,但可能会导致内存空间的浪费。
4.散列表+树表法能有效提高查找效率。
两种方法的区别在于冲突处理方式,拉链法只是单一将指针后移,而散列表+树表法则是根据待查找元素与当前根结点数据域的关系选择进入左子树或右子树继续查找,因此理论上减少了冲突处理成本,查找效率更高。
五、实验特色和创新点
1.为了使程序架构清晰,简化实验过程,因此严格遵守了主函数与子函数之间的层级调用关系,在主函数中定义散列表相关属性并根据实验要求进行手动赋值,实验时通过注释主函数中的无关子函数来实现实验所需的特定方法,从而使程序架构更加清晰。(详见测试过程)
2.为了方便实验过程中的测试,特别编写了SingleSearch函数,用来对单个数据进行查找来验证散列表是否按照预期正确创建以及查找算法的正确性,并且返回查找长度。在后续进行查找时间和平均查找长度ASL的数据记录时,编写AllSearch函数,函数体内调用SingleSearch函数,对所有数据的查找长度进行累加,并计算平均查找长度。
3.为了寻找查找效率更高的散列表,本实验将散列表与树表结合,发挥了散列表的快速定位优势和树表的冲突处理优势,将两种优势进行结合,巧妙地降低了冲突处理成本,从而提高查找效率。

