
热门标签
热门文章
- 1无人机赋能空间规划
- 2全国计算机等级考试三级数据库技术(九)_sql中的强制存取控制中,dbms所管理的全部实体被分为
- 3【TensorFlow】笔记4:图像识别与CNN_tensorflow图像识别
- 4【Python实战】网络爬虫实战详解_partial page rank策略
- 5TCP/UDP_tcp端口号和udp端口号
- 6LLaMA3(Meta)微调SFT实战Meta-Llama-3-8B-Instruct
- 7技术干货 | 基于 MindSpore 实现图像分割之豪斯多夫距离_图像分割surface distance
- 8TensorFlow 深度学习官网教程笔记系列:1.初学者的 TensorFlow 2.0 教程_tensorflow2深度学习官网教程笔记系列 南贝塔
- 9NLP自然语言处理-初探_自然语言处理 去噪
- 10OBS Studio(obs录屏软件)官方中文版V27.2.4 | 最新obs中文版百度云下载_obs百度云
当前位置: article > 正文
ShardingSphere 5.0.0 实现按月水平分表_shardingsphere按月分表
作者:一键难忘520 | 2024-06-25 16:00:53
赞
踩
shardingsphere按月分表
背景:
业务数据从大数据进行同步,数据量大概1个月1000W条,如果选择按字段进行hash取模分表时间久了数据量依然会很大,所以直接选择按月进行水平分表。
废话不多说,直接上代码
1.Maven引入依赖
- <dependency>
- <groupId>org.apache.shardingsphere</groupId>
- <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
- <version>5.0.0</version>
- </dependency>
2.application.yml配置
3.数据分配算法类 OTAStrategyShardingAlgorithm.java
- import com.alibaba.fastjson.JSON;
- import com.google.common.collect.Range;
- import org.apache.commons.lang.StringUtils;
- import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
- import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
- import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
- import org.springframework.stereotype.Component;
-
- import java.time.LocalDateTime;
- import java.time.format.DateTimeFormatter;
- import java.util.*;
-
-
- /**
- * @Description: sharding分表规则:按单月分表
- * @Author: lg
- * @Date: 2022/6/9
- * @Version: V1.0
- */
- @Component
- public class OTAStrategyShardingAlgorithm implements StandardShardingAlgorithm<String> {
-
- private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
- private static final DateTimeFormatter yyyyMM = DateTimeFormatter.ofPattern("yyyyMM");
-
- /**
- * 【范围】数据查询
- */
- @Override
- public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
- // 逻辑表名
- String logicTableName = rangeShardingValue.getLogicTableName();
-
- // 范围参数
- Range<String> valueRange = rangeShardingValue.getValueRange();
- Set<String> queryRangeTables = extracted(logicTableName, LocalDateTime.parse(valueRange.lowerEndpoint(), formatter),
- LocalDateTime.parse(valueRange.upperEndpoint(), formatter));
- ArrayList<String> tables = new ArrayList<>(collection);
- tables.retainAll(queryRangeTables);
- System.out.println(JSON.toJSONString(tables));
- return tables;
- }
-
- /**
- * 根据范围计算表明
- *
- * @param logicTableName 逻辑表明
- * @param lowerEndpoint 范围起点
- * @param upperEndpoint 范围终端
- * @return 物理表名集合
- */
- private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
- Set<String> rangeTable = new HashSet<>();
- while (lowerEndpoint.isBefore(upperEndpoint)) {
- String str = getTableNameByDate(lowerEndpoint, logicTableName);
- rangeTable.add(str);
- lowerEndpoint = lowerEndpoint.plusMonths(1);
- }
- // 获取物理表明
- String tableName = getTableNameByDate(upperEndpoint, logicTableName);
- rangeTable.add(tableName);
- return rangeTable;
- }
-
- /**
- * 根据日期获取表明
- * @param dateTime 日期
- * @param logicTableName 逻辑表名
- * @return 物理表名
- */
- private String getTableNameByDate(LocalDateTime dateTime, String logicTableName) {
- String tableSuffix = dateTime.format(yyyyMM);
- return logicTableName.concat("_").concat(tableSuffix);
- }
-
- /**
- * 数据插入
- *
- * @param collection
- * @param preciseShardingValue
- * @return
- */
- @Override
- public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
- String str = preciseShardingValue.getValue();
- if (StringUtils.isEmpty(str)) {
- return collection.stream().findFirst().get();
- }
- LocalDateTime value = LocalDateTime.parse(str, formatter);
- String tableSuffix = value.format(yyyyMM);
- String logicTableName = preciseShardingValue.getLogicTableName();
- String table = logicTableName.concat("_").concat(tableSuffix);
- System.out.println("OrderStrategy.doSharding table name: " + table);
- return collection.stream().filter(s -> s.equals(table)).findFirst().orElseThrow(() -> new RuntimeException("逻辑分表不存在"));
- }
-
- @Override
- public void init() {
-
- }
-
- @Override
- public String getType() {
- // 自定义 这里需要spi支持
- return null;
- }
-
- }

shardingsphere5.0版本开始,数据插入和数据查询都可以在一个类中实现,需要实现接口:StandardShardingAlgorithm
4.重写方法doSharding()、extracted()
- // 根据精准值查询逻辑表
- public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
-
- }
- // 根据范围查询逻辑表
- private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
- }
-
- // 插入数据时根据分表关键词获取物理表
- public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
5.初始化分表
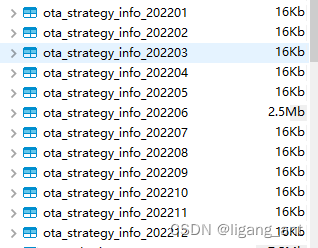
6.插入测试
这里直接使用mybatis或者mybatisplus插入即可,在步骤4中的doSharding方法查看是否匹配到对应的物理表即可,结果直接从表里查看即可。
7.查询测试
执行下述sql
select * from ota_strategy_info where create_time = '2022-04-14 17:21:48'结果:

这里的查询精确找到了4月的物理表,如果未找到则会查询所有表,同理会执行与表数量相对于的sql数量,所以查询的时候一定要命中物理表,否则效率不仅不会提高返回会降低!
总结:
官网文档:概览 :: ShardingSphere https://shardingsphere.apache.org/document/current/cn/overview/更多内容可以参考文档,查询sql是否会命中物理表得多测试,根据日志提示选择查询方法!
https://shardingsphere.apache.org/document/current/cn/overview/更多内容可以参考文档,查询sql是否会命中物理表得多测试,根据日志提示选择查询方法!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/756712
推荐阅读
相关标签

