- 12024认证杯数学建模A题保暖纤维保暖能力原创论文讲解(含完整python代码)_涤纶纤维保暖数学建模
- 2Arduin基础学习-蓝牙模块基础_arduremoteid
- 3人工智能——机器学习概述
- 4最新详细eclipse下载、安装、汉化教程
- 5Flink性能调优小小总结_flink1.17参数调优
- 6计算机毕业设计PHP财务管理系统(源码+程序+VUE+lw+部署)_php记账系统源码
- 7信息安全体系建设☞开源入侵检测系统HIDS_开源hids
- 8RabbitMQ的死信队列和延时队列
- 9C语言数据结构判断字符串是否是回文_数据结构判断回文
- 10BurpSuite安装以及基本使用方式分享_burpsuite压缩包
昇腾AI创新大赛集训营(南京站)
赞
踩
初识Asend C
AI Core架构
AI Core是昇腾AI处理器的计算核心,采用华为自研的达芬奇架构(Davinci Core)
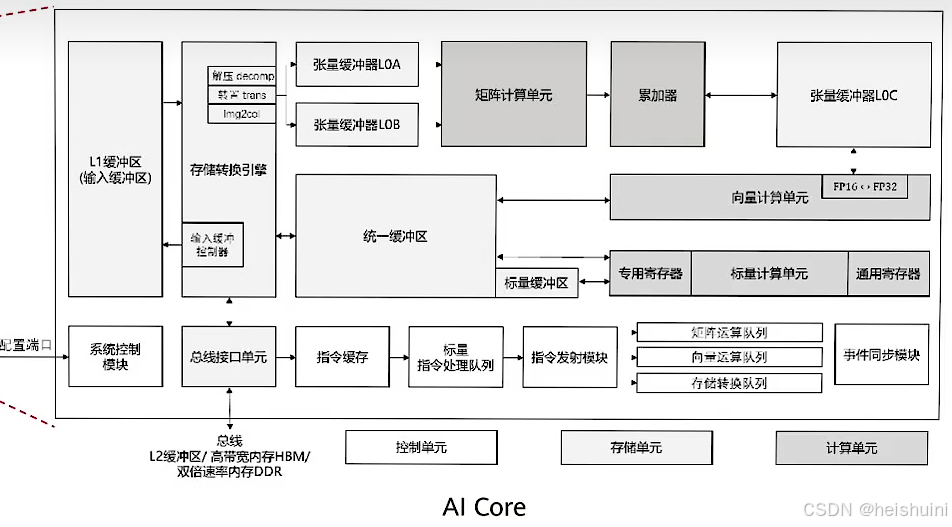
其包含的主要部分:
计算单元:矩阵计算单元,向量计算单元,标量计算单元(Scalar)
存储系统:片上存储单元+数据通路
控制单元:计算过程需要有指令进行控制。
·异步指令流:使得多个任务能够并行执行,加快执行速率。
·同步信号流:用于同步任务的执行,如存储,搬运数据的执行顺序
抽象部分:计算单元,存储单元,搬运单元等
SPMD架构:单个程序多个数据运行
算子
名称
类型
承载容器 张量(Tensor)
·统一的数据结构,可表示各种维度的数据(如二维、三维等)
·数据排布格式(format)NHWC,遍历顺序相反CWHN,是从低维到高维。
调用核函数
编程范式

·copyin: 从inqueue中取出数据(enque实现)
·compute: 将取出的数据进行计算
·copyout: 从outqueue取出数据
基础API、高级API的调用接口:基础API通用说明-通用概念和约束(必读)-Ascend C API-Ascend C API-算子开发接口-API参考-CANN社区版8.0.RC3.alpha001开发文档-昇腾社区 (hiascend.com)
Kernel直调案例&微认证
题目要求:
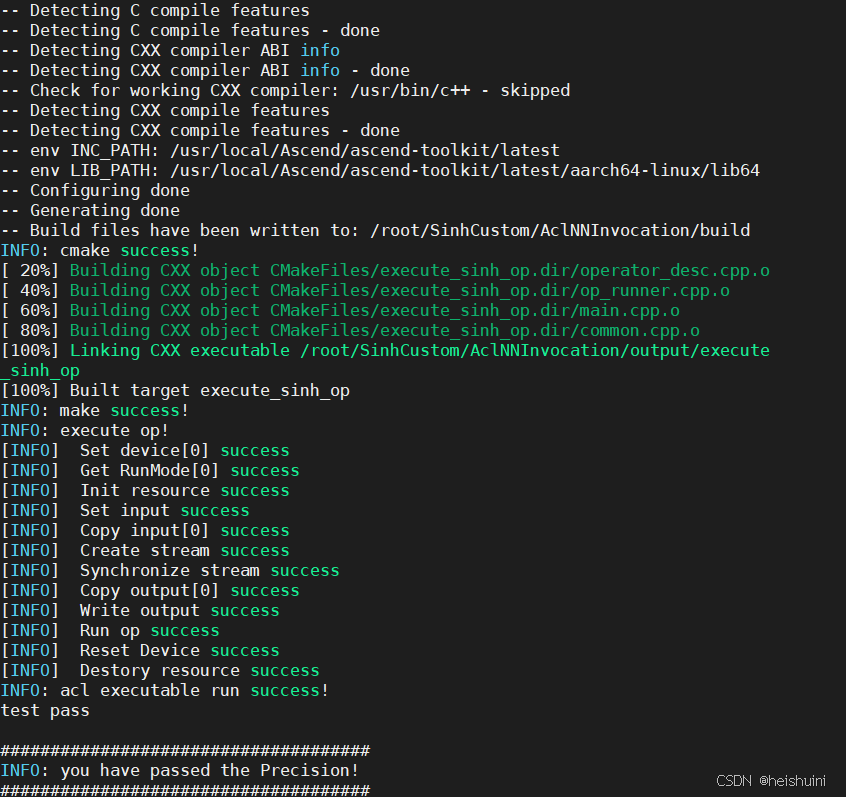
实现Ascend C算子Sinh,编写其kernel侧代码、host侧代码,并完成aclnn算子调用测试。
其中,sinh(x) = (exp(x) - exp(-x)) / 2.0
1.kernel侧
SinhCustom\op_kernel\sinh_custom.cpp
核函数部分修改sinh_custom
对Init和Process进行调用。
op.Init(x, y, tiling_data.totalLength, tiling_data.tileNum); op.Process();
初始化部分Init
初始化全局变量
xGm.SetGlobalBuffer((__gm__ half*)x + this->blockLength * GetBlockIdx(), this->blockLength); yGm.SetGlobalBuffer((__gm__ half*)y + this->blockLength * GetBlockIdx(), this->blockLength);
处理过程Process
主要分为Copyin,Compute,Copyout
int32_t loopCount = this->tileNum * BUFFER_NUM;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
2.host侧
- SinhCustom\op_host\sinh_custom.cpp
在TilingFunc中进行Tiling数据的设置。
uint32_t totalLength = context->GetInputTensor(0)->GetShapeSize(); context->SetBlockDim(8); tiling.set_totalLength(totalLength); tiling.set_tileNum(8); tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0;
- SinhCustom\op_host\sinh_custom_tiling.h
进行tiling数据结构体的定义
TILING_DATA_FIELD_DEF(uint32_t, totalLength); TILING_DATA_FIELD_DEF(uint32_t, tileNum);
3.AclNN调用
①在SinhCustom目录下,执行:bash ./build.sh
②在build_out文件夹下,执行:./custom_opp_euleros_aarch64.run
③在SinhCustom/AclNNInvocation/目录下,执行:bash ./run.sh